This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Modern chatbots can serve as digital agents, providing a new avenue for delivering 24/7 customer service and support across many industries. Their popularity stems from the ability to respond to customer inquiries in real time and handle multiple queries simultaneously in different languages.
To start simply, you could think of LLMOps ( LargeLanguageModel Operations) as a way to make machine learning work better in the real world over a long period of time. As previously mentioned: model training is only part of what machine learning teams deal with. What is LLMOps? Why are these elements so important?
This integration uniquely bridges the gap between scalable data management and cutting-edge AI development, unlocking new efficiencies in dataingestion, labeling, model development, and deployment for our customers. Validate in Databricks: Ensure that the newly labeled dataset is loaded correctly.
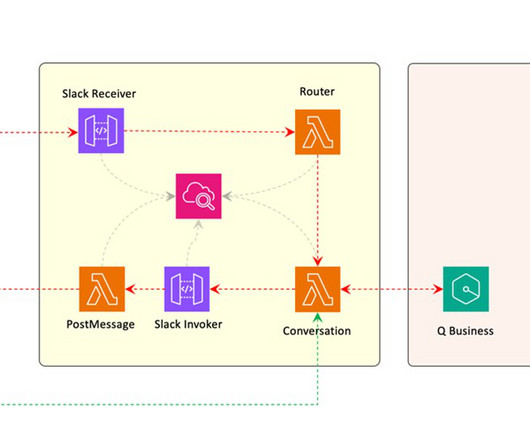
Document upload When users need to provide context of their own, the chatbot supports uploading multiple documents during a conversation. We deliver our chatbot experience through a custom web frontend, as well as through a Slack application.
Chatbot on custom knowledge base using LLaMA Index — Pragnakalp Techlabs: AI, NLP, Chatbot, Python Development LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (LargeLanguageModels).
In simple terms, RAG is a natural language processing (NLP) approach that blends retrieval and generation models to enhance the quality of generated content. It addresses challenges faced by LargeLanguageModels (LLMs), including limited knowledge access, lack of transparency, and hallucinations in answers.
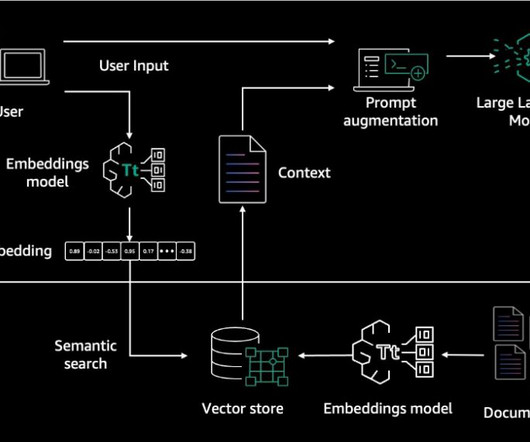
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. The first step is dataingestion, as shown in the following diagram. This structure can be used to optimize dataingestion.
Introduction LargeLanguageModels (LLMs) have opened up a new world of possibilities, powering everything from advanced chatbots to autonomous AI agents. However, to unlock their full potential, you often need robust frameworks that handle dataingestion, prompt engineering, memory storage, and tool usage.
This e-book focuses on adapting largelanguagemodels (LLMs) to specific use cases by leveraging Prompt Engineering, Fine-Tuning, and Retrieval Augmented Generation (RAG), tailored for readers with an intermediate knowledge of Python. Dianasanimals is looking for students to test several free chatbots.
LlamaIndex is an impressive data framework designed to support the development of applications utilizing LLMs (LargeLanguageModels). It offers a wide range of essential tools that simplify tasks such as dataingestion, organization, retrieval, and integration with different application frameworks.
You follow the same process of dataingestion, training, and creating a batch inference job as in the previous use case. Announcing LangChain integration to seamlessly integrate Amazon Personalize with the LangChain framework LangChain is a powerful open-source framework that allows for integration with largelanguagemodels (LLMs).
This integration uniquely bridges the gap between scalable data management and cutting-edge AI development, unlocking new efficiencies in dataingestion, labeling, model development, and deployment for our customers. Validate in Databricks: Ensure that the newly labeled dataset is loaded correctly.
Largelanguagemodels (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. For ingestion, data can be updated in an offline mode, whereas inference needs to happen in milliseconds.
However, the complexity and scale of data present significant challenges in processing, accuracy, and can stymie decisionmaking. This presentation will explore the role of FunctionalMind , an AIdriven chatbot and clinical research agent, in addressing these challenges.
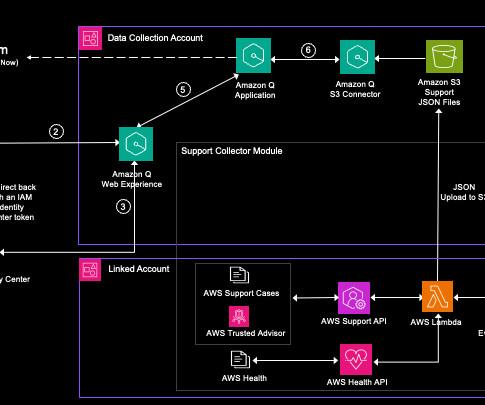
Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data. By default, Amazon Q Business will only produce responses using the data you’re indexing. This behavior is aligned with the use cases related to our solution.
Unlocking accurate and insightful answers from vast amounts of text is an exciting capability enabled by largelanguagemodels (LLMs). When building LLM applications, it is often necessary to connect and query external data sources to provide relevant context to the model.
TL;DR LLMOps involves managing the entire lifecycle of LargeLanguageModels (LLMs), including data and prompt management, model fine-tuning and evaluation, pipeline orchestration, and LLM deployment. What is LargeLanguageModel Operations (LLMOps)? What the future of LLMOps looks like.
Content ingestion into vector db Select the optimal LLM for your use case Selecting the right LLM for any use case is essential. Every use case has different requirements for context length, token size, and the ability to handle various tasks like summarization, task completion, chatbot applications, and so on.
The AI Paradigm Shift: Under the Hood of a LargeLanguageModels Valentina Alto | Azure Specialist — Data and Artificial Intelligence | Microsoft Develop an understanding of Generative AI and LargeLanguageModels, including the architecture behind them, their functioning, and how to leverage their unique conversational capabilities.
One of the most common applications of generative AI and largelanguagemodels (LLMs) in an enterprise environment is answering questions based on the enterprise’s knowledge corpus. Amazon Lex provides the framework for building AI based chatbots. Amazon SageMaker Studio for hosting the Streamlit application.
In order to train transformer models on internet-scale data, huge quantities of PBAs were needed. In November 2022, ChatGPT was released, a largelanguagemodel (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom. Firstly, to train a FM from scratch.
In the rapidly evolving AI landscape, LargeLanguageModels (LLMs) have emerged as powerful tools, driving innovation across various sectors. From enhancing customer service experiences to providing insightful data analysis, the applications of LLMs are vast and varied.
1] The typical application familiar to readers is much more recent, when AI operates as chatbots, enhancing or at least facilitating the user experience on many websites. Whether that happens with many largelanguagemodels is largely, but not entirely, up to you. [5] Data center career paths (techtarget.com) 10.
It allows beginners and expert practitioners to develop and deploy Gen AI applications for various use cases beyond simple chatbots, including agentic, multi-agentic, Generative BI, and batch workflows. DataIngestion Pipeline Ingestingdata from diverse sources is essential for executing Retrieval Augmented Generation (RAG).
Hallucinations in largelanguagemodels (LLMs) refer to the phenomenon where the LLM generates an output that is plausible but factually incorrect or made-up. Imagine this to be a simpler implementation of calling a customer service agent when the chatbot is unable to answer the customer query.
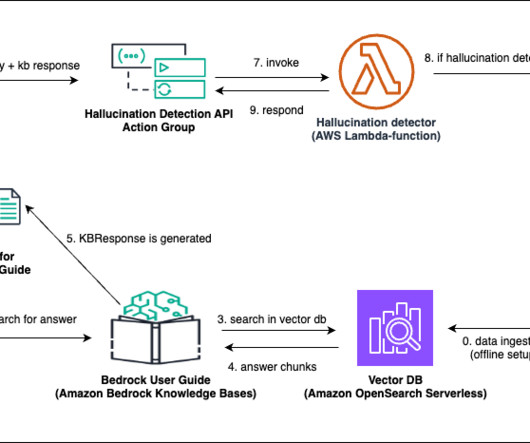
This post dives deep into Amazon Bedrock Knowledge Bases , which helps with the storage and retrieval of data in vector databases for RAG-based workflows, with the objective to improve largelanguagemodel (LLM) responses for inference involving an organization’s datasets. The LLM response is passed back to the agent.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content