This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These agents perform tasks ranging from customer support to softwareengineering, navigating intricate workflows that combine reasoning, tool use, and memory. The authors categorize traceable artifacts, propose key features for observability platforms, and address challenges like decision complexity and regulatory compliance.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. Model risk : Risk categorization of the model version.
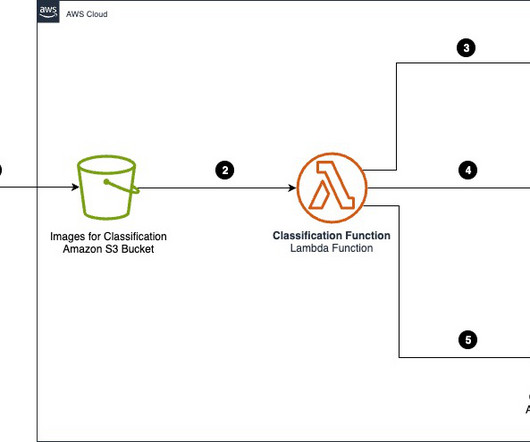
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Categorizing documents is an important first step in IDP systems. An S3 prefix or S3 object metadata can be used to classify gallery images. George Belsian is a Senior Cloud Application Architect at AWS.
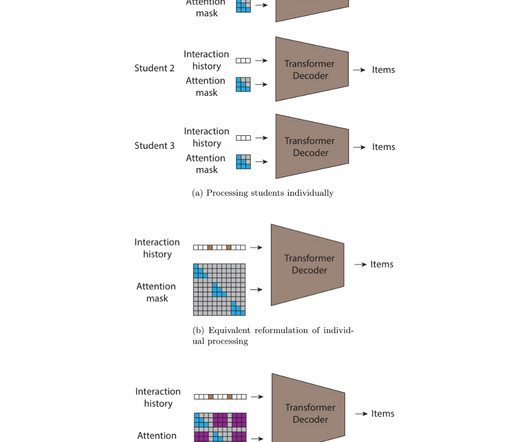
Furthermore all potentially identifiable metadata was only shared in an aggregated form, to protect students and institutions from being re-identified. Acknowledgements This work involved collaborative efforts from a multidisciplinary team of researchers, softwareengineers and educational subject matter experts.
Igor Tsvetkov Former Senior Staff SoftwareEngineer, Cruise AI teams automating error categorization and correlation can significantly reduce debugging time in hyperscale environments, just as Cruise has done. GPU memory leaks, network latency) or software bugs (e.g.,
This issue becomes even more difficult when code is passed between different roles, such as from a data scientist to a softwareengineer for deployment. Local Tracking with Database: You can use a local database to manage experiment metadata for a cleaner setup compared to local files. Can have tags for tracking attributes (e.g.,
This post explores how 123RF used Amazon Bedrock, Anthropic’s Claude 3 Haiku, and a vector store to efficiently translate content metadata, significantly reduce costs, and improve their global content discovery capabilities. Metadata such as the content type, domain, and any relevant tags. The corresponding translation chunk.
Common patterns for filtering data include: Filtering on metadata such as the document name or URL. Instruction fine tuning dataset format The columns in the table that follows represent the key components of the instruction-tuning paradigm: Type categorizes the task or instruction type. Input provides the context or data to work with.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content