This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Built with responsibleAI, Amazon Bedrock Data Automation enhances transparency with visual grounding and confidence scores, allowing outputs to be validated before integration into mission-critical workflows. Extract sentiment insights and categorize customer complaints for proactive issue resolution.
It’s ideal for workloads that aren’t latency sensitive, such as obtaining embeddings, entity extraction, FM-as-judge evaluations, and text categorization and summarization for business reporting tasks. It stores information such as job ID, status, creation time, and other metadata.
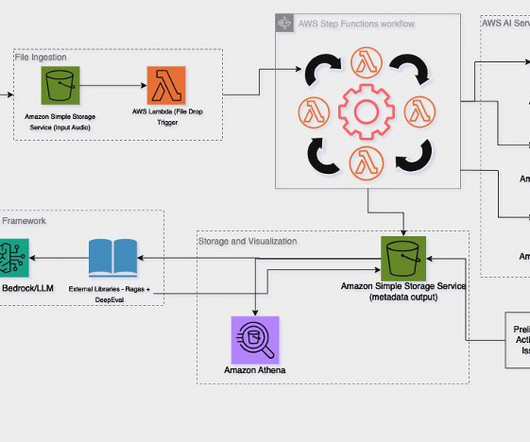
In this post, we explore why Asure used the Amazon Web Services (AWS) post-call analytics (PCA) pipeline that generated insights across call centers at scale with the advanced capabilities of generative AI-powered services such as Amazon Bedrock and Amazon Q in QuickSight. and Anthropics Claude Haiku 3.
In this second part, we expand the solution and show to further accelerate innovation by centralizing common Generative AI components. We also dive deeper into access patterns, governance, responsibleAI, observability, and common solution designs like Retrieval Augmented Generation. This logic sits in a hybrid search component.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Today, generative AI can help bridge this knowledge gap for nontechnical users to generate SQL queries by using a text-to-SQL application. Weve added one dropdown menu with four choices.
Set up the policy documents and metadata in the data source for the knowledge base We use Amazon Bedrock Knowledge Bases to manage our documents and metadata. Upload a few insurance policy documents and metadata documents to the S3 bucket to mimic the naming conventions as shown in the following screenshot.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. Model risk : Risk categorization of the model version.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. With Amazon Bedrock, developers can experiment, evaluate, and deploy generative AI applications without worrying about infrastructure management.
Recent Progress Recent progress in this area can be categorized into two categories: 1) new groups, communities, support structures, and initiatives that have enabled broader work; and 2) high-level research contributions such as new datasets and models that allow others to build on them. Joshi et al. [92] Lucassen, T.,
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
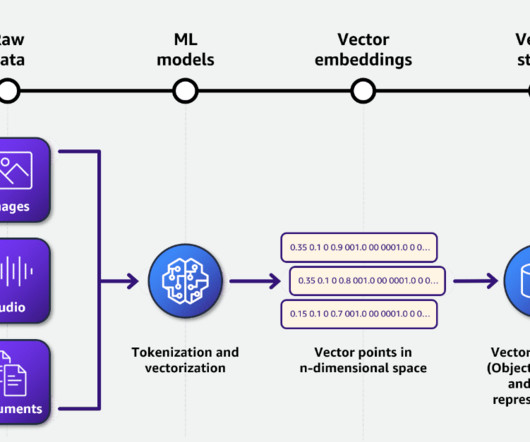
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. Content categorization – Metadata can provide information about the content or category of a document, such as the subject matter, domain, or topic.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) along with a broad set of capabilities to build generative AI applications, simplifying development with security, privacy, and responsibleAI. This allows you to categorize and filter your interactions later.
This post explores how 123RF used Amazon Bedrock, Anthropic’s Claude 3 Haiku, and a vector store to efficiently translate content metadata, significantly reduce costs, and improve their global content discovery capabilities. Metadata such as the content type, domain, and any relevant tags. The corresponding translation chunk.
Common patterns for filtering data include: Filtering on metadata such as the document name or URL. Instruction fine tuning dataset format The columns in the table that follows represent the key components of the instruction-tuning paradigm: Type categorizes the task or instruction type. Output shows the expected or desired response.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content