This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
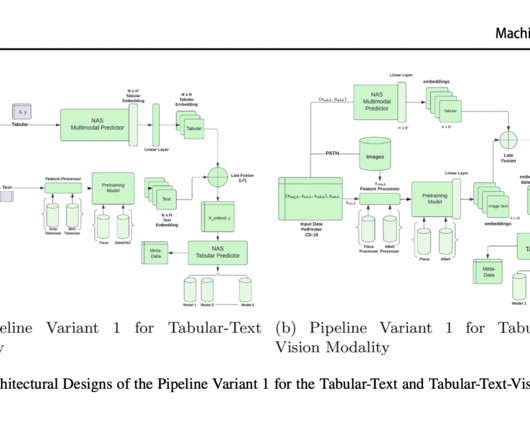
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details. Additional processing is needed to standardize formats, manage JSON outputs, and align data fields, often requiring manual integration and multiple API calls.
Third, the NLP Preset is capable of combining tabular data with NLP or NaturalLanguageProcessing tools including pre-trained deep learning models and specific feature extractors. Next, the LightAutoML inner datasets contain CV iterators and metadata that implement validation schemes for the datasets.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
In NaturalLanguageProcessing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies.
Therefore, the data needs to be properly labeled/categorized for a particular use case. In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. The model must be taught to identify specific entities to make accurate predictions.
Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. The text of the transcript is broken down into either paragraphs or sentences, along with additional metadata such as start and end timestamps or speaker information.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. No explanation is required.
Using naturallanguageprocessing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. Set up the policy documents and metadata in the data source for the knowledge base We use Amazon Bedrock Knowledge Bases to manage our documents and metadata.
By leveraging MLLM, these agents can process and synthesize vast amounts of information from various modalities, enabling them to offer personalized assistance and enhance user experiences in ways previously unimaginable. Mobile-Agent introduces Mobile-Eval, a benchmark designed to evaluate mobile-device agents.
Addressing this challenge, researchers from Eindhoven University of Technology have introduced a novel method that leverages the power of pre-trained Transformer models, a proven success in various domains such as Computer Vision and NaturalLanguageProcessing.
Images can often be searched using supplemented metadata such as keywords. However, it takes a lot of manual effort to add detailed metadata to potentially thousands of images. Generative AI (GenAI) can be helpful in generating the metadata automatically. This helps us build more refined searches in the image search process.
OCR The first step of document processing is usually a conversion of scanned PDFs to text information. The documentation can also include DICOM or other medical images, where both metadata and text information shown on the image needs to be converted to plain text.
As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional naturallanguageprocessing (NLP)-based analytics.
Named Entity Recognition (NER) is a naturallanguageprocessing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. So, to make sure you get the data that is right for you (without the fluff!),
The capability of AI to execute complex tasks efficiently is determined by image annotation, which is a key determinant of its success and is defined as the process of labeling images with descriptive metadata. A company usually uses this process when it needs to process a large number of images quickly and efficiently.
Whether you’re looking to classify documents, extract keywords, detect and redact personally identifiable information (PIIs), or parse semantic relationships, you can start ideating your use case and use LLMs for your naturallanguageprocessing (NLP). Intents are categorized into two levels: main intent and sub intent.
Photo by Oleg Laptev on Unsplash By improving many areas of content generation, optimization, and analysis, naturallanguageprocessing (NLP) plays a crucial role in content marketing. Artificial intelligence (AI) has a subject called naturallanguageprocessing (NLP) that focuses on how computers and human language interact.
However, you can use the asynchronous StartDocumentAnalysis API to process multi-page documents (with up to 3,000 pages). He specializes in NaturalLanguageProcessing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
Operationalization journey per generative AI user type To simplify the description of the processes, we need to categorize the main generative AI user types, as shown in the following figure. They have deep end-to-end ML and naturallanguageprocessing (NLP) expertise and data science skills, and massive data labeler and editor teams.
All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item. This model acts as a container for the artifacts and metadata necessary to serve predictions. Use the create_model method of the AutoML job object to complete this step.
Retrieval-augmented generation (RAG) represents a leap forward in naturallanguageprocessing. Enriching chunks with metada enables hybrid approaches that leverage categorical information as well as vector embeddings. Well-crafted RAG systems deliver meaningful business value in a user-friendly form factor.
Sentiment analysis, also known as opinion mining, is the process of computationally identifying and categorizing the subjective information contained in naturallanguage text. An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it.
Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to extract insights from text. LLMs are helpful in document classification because they can analyze the text, patterns, and contextual elements in the document using naturallanguage understanding.
Developing models that work for more languages is important in order to offset the existing language divide and to ensure that speakers of non-English languages are not left behind, among many other reasons. The distribution of resources in the world's languages. Transfer learning in naturallanguageprocessing.
These techniques can be applied to a wide range of data types, including numerical data, categorical data, text data, and more. NoSQL databases are often categorized into different types based on their data models and structures. It runs on top of your existing data lake and is fully compatible with Apache Spark APIs.
Methods for continual learning can be categorized as regularization-based, architectural, and memory-based, each with specific advantages and drawbacks. The code is set up to track all experiment metadata in Neptune. It is designed for PyTorch and can be used in various domains like Computer Vision and NaturalLanguageProcessing.
Parallel computing Parallel computing refers to carrying out multiple processes simultaneously, and can be categorized according to the granularity at which parallelism is supported by the hardware. The following table shows the metadata of three of the largest accelerated compute instances. 32xlarge 0 16 0 128 512 512 4 x 1.9
") print(prompt.format(subject=" NaturalLanguageProcessing ")) As we advance in complexity, we encounter more sophisticated patterns in LangChain, such as the Reason and Act (ReAct) pattern. LangChain categorizes its chains into three types: Utility chains, Generic chains, and Combine Documents chains.
Running BERT models on smartphones for on-device naturallanguageprocessing requires much less energy due to resource constrained in smartphones than server deployments. It also enables running sophisticated models on resource-constrained devices. Lower precision computations consume significantly less energy.
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. Content categorization – Metadata can provide information about the content or category of a document, such as the subject matter, domain, or topic.
Text classification : Build faster models for categorizing high volumes of concurrent support tickets, emails, or customer feedback at scale; or for efficiently routing requests to larger models when necessary. You can optionally add request metadata to these inference requests to filter your invocation logs for specific use cases.
Vision Transformers(ViT) ViT is a type of machine learning model that applies the transformer architecture, originally developed for naturallanguageprocessing, to image recognition tasks. Unite files and metadata together into persistent, versioned, columnar datasets. 🧠 Data Enrichment and Processing.
Common patterns for filtering data include: Filtering on metadata such as the document name or URL. join(full_text) Deduplication After the preprocessing step, it is important to process the data further to remove duplicates (deduplication) and filter out low-quality content. Instruction contains the specific directive for the model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content