This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The managed service offers a simple and cost-effective method of categorizing and managing big data in an enterprise. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process.
These datasets encompass millions of hours of music, over 10 million recordings and compositions accompanied by comprehensive metadata, including key, tempo, instrumentation, keywords, moods, energies, chords, and more, facilitating training and commercial usage. GCX provides datasets with over 4.4
The authors categorize traceable artifacts, propose key features for observability platforms, and address challenges like decision complexity and regulatory compliance. These metrics are visualized across dimensions such as user sessions, prompts, and workflows, enabling real-time interventions.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. This tagging structure categorizes costs and allows assessment of usage against budgets.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
In this collaboration, the Generative AI Innovation Center team created an accurate and cost-efficient generative AIbased solution using batch inference in Amazon Bedrock , helping GoDaddy improve their existing product categorization system. Moreover, employing an LLM for individual product categorization proved to be a costly endeavor.
The Ministry of Justice in Baden-Württemberg recommended using AI with natural language understanding (NLU) and other capabilities to help categorize each case into the different case groups they were handling. The courts needed a transparent, traceable system that protected data. Explainability will play a key role.
Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details. With growing content libraries, media companies need efficient ways to categorize, search, and repurpose assets for production, distribution, and monetization.
It’s ideal for workloads that aren’t latency sensitive, such as obtaining embeddings, entity extraction, FM-as-judge evaluations, and text categorization and summarization for business reporting tasks. It stores information such as job ID, status, creation time, and other metadata.
Self-managed content refers to the use of AI and neural networks to simplify and strengthen the content creation process via smart tagging, metadata templates, and modular content. Role of AI and neural networks in self-management of digital assets Metadata is key in the success of self-managing content.
Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging. Solution overview Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis.
Asure chose this approach because it provided in-depth consumer analytics, categorized call transcripts around common themes, and empowered contact center leaders to use natural language to answer queries. The original PCA post linked previously shows how Amazon Transcribe and Amazon Comprehend are used in the metadata generation pipeline.
First, Reader, an object that receives task type and raw data as input, performs crucial metadata calculations, cleans the initial data, and figures out the data manipulations to be performed before fitting different models. The third component are the multiple machine learning pipelines stacked and/or blended to get a single prediction.
Organize, Categorize, and Annotate for Deeper Insights Searchable media enables better organization and archiving of research data, allowing researchers to tag and categorize audio segments based on topics or keywords. This creates a well-organized repository that is easily accessible for future studies or follow-up research.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies.
Neglecting this preliminary stage may result in inaccurate tokenization, impacting subsequent tasks such as sentiment analysis, language modeling, or text categorization. Document Extraction: Unstructured is excellent at extracting metadata and document elements from a wide range of document types.
The embeddings, along with metadata about the source documents, are indexed for quick retrieval. Through a runtime process that includes preprocessing and postprocessing steps, the agent categorizes the user’s input. The embeddings are stored in the Amazon OpenSearch Service owner manuals index.
Set up the policy documents and metadata in the data source for the knowledge base We use Amazon Bedrock Knowledge Bases to manage our documents and metadata. Upload a few insurance policy documents and metadata documents to the S3 bucket to mimic the naming conventions as shown in the following screenshot.
The structure is loaded using the pydicom.dcmread function, from which metadata (such as the patient’s name) and studies containing the images can be extracted. I also found a notebook with a neural network that can categorize the images with perfect accuracy. To read the DICOM files, we use the Pydicom library.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. To increase the accuracy, we categorized the tables in four different types based on the schema and created four JSON files to store different tables. Weve added one dropdown menu with four choices.
is its enriched problem metadata, which includes: Final answers for word problems. Problem types are categorized into multiple-choice questions (MCQs), proof-based problems, and word problems. Structured metadata, including problem type, question format, and verified solutions, ensures precise categorization and analysis.
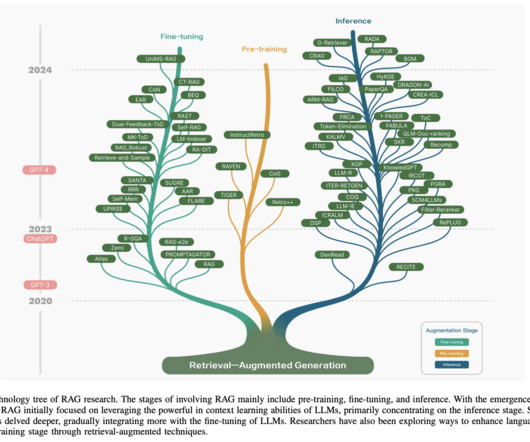
The RAG research paradigm is continuously evolving, and RAG is categorized into three stages: Naive RAG, Advanced RAG, and Modular RAG. To tackle the indexing issues, Advanced RAG refines its indexing techniques through a sliding window approach, fine-grained segmentation, and the incorporation of metadata.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. Model risk : Risk categorization of the model version.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. We provide a prompt example for feedback categorization. Extracting valuable insights from customer feedback presents several significant challenges.
The Mobile-Agent framework differs from existing solutions since it does not rely on mobile system metadata or XML files of the mobile applications, allowing room for enhanced adaptability across diverse mobile operating environments in a vision centric way.
Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. The text of the transcript is broken down into either paragraphs or sentences, along with additional metadata such as start and end timestamps or speaker information.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Categorizing documents is an important first step in IDP systems. An S3 prefix or S3 object metadata can be used to classify gallery images.
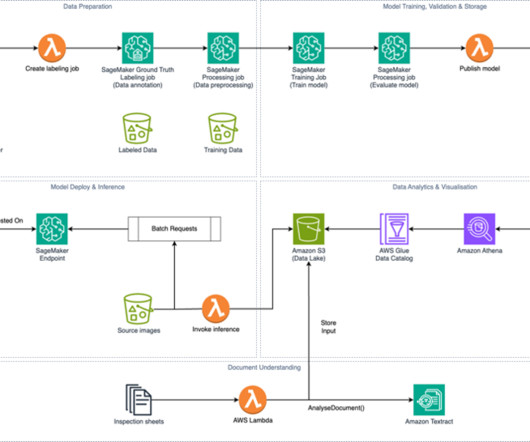
Some components are categorized in groups based on the type of functionality they exhibit. With AWS Glue Data Catalog, a centralized metadata repository, and Amazon Athena, an interactive query service, you can run one-time SQL queries directly on the data stored in Amazon S3.
The study involved a global participant pool to obtain validated labels and metadata for the perceived race and gender of each avatar. The research team discussed implications for virtual avatar applications, emphasizing the potential for in-group and out-group categorization leading to stereotyping and social judgments.
Images can often be searched using supplemented metadata such as keywords. However, it takes a lot of manual effort to add detailed metadata to potentially thousands of images. Generative AI (GenAI) can be helpful in generating the metadata automatically. This helps us build more refined searches in the image search process.
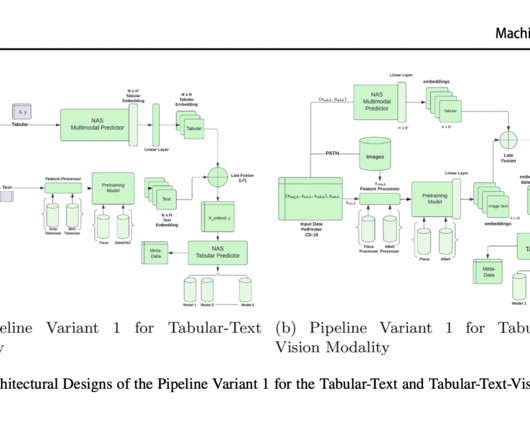
A flexible search space (pipeline) for multimodal data is designed, pre-trained models are strategically incorporated into the pipeline topologies, and warm-starting for SMAC using metadata from previous evaluations is implemented. This collection was chosen after the pipeline variants had been designed.
Identify the Designated Market Areas (DMAs) OfferUp categorizes its DMAs into high density and low density. These databases typically use k-nearest (k-NN) indexes built with advanced algorithms such as Hierarchical Navigable Small Worlds (HNSW) and Inverted File (IVF) systems.
We can categorize multimodal text and image RAG questions in three categories: Image retrieval based on text input – For example: “Show me a diagram to repair the compressor on the ice cream machine.” Amazon Titan Embedding Text v2 ) and stored in a vector store along with the image as metadata.
They can categorize nodes and relationships into types with associated metadata, treat your graph as a superset of a vector database for hybrid search, and express complex queries using the Cypher graph query language. LlamaIndex Launches a Framework for Building Knowledge Graphs with LLMs LlamaIndex recently launched Property Graphs.
SageMaker Studio runs custom Python code to augment the training data and transform the metadata output from SageMaker Ground Truth into a format supported by the computer vision model training job. Northpower categorized 1,853 poles as high priority risks, 3,922 as medium priority, 36,260 as low priority, and 15,195 as the lowest priority.
Key Features That Make a Difference: Clear Categorization: Deadlines are organized by type conferences, grants, workshops, and more making it easy to filter and focus on whats most relevant to you. Browse through the well-categorized deadlines for events such as conferences, workshops, and grants. title, abstract, authors).
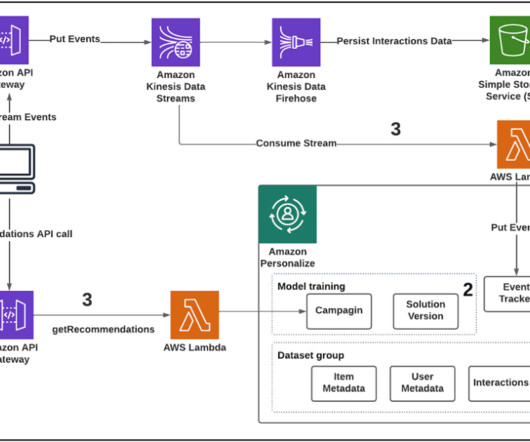
Using a user’s contextual metadata such as location, time of day, device type, and weather provides personalized experiences for existing users and helps improve the cold-start phase for new or unidentified users. Why is context important? The USER_ID , ITEM_ID , and TIMESTAMP fields are required by Amazon Personalize for this dataset.
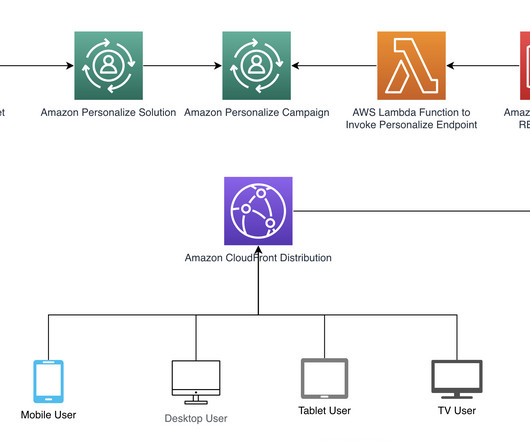
If a user has engaged with movies categorized as Drama in the item dataset, Amazon Personalize will suggest movies (items) with the same genre. Setup your development environment – Install the AWS Command Line Interface (AWS CLI). You can find the campaign ARN in the Amazon Personalize console menu.
It allows the model to learn from any collection of images without needing labels or metadata. Image object classification in manufacturing can be used to detect and categorize defects in products during production, leading to improved quality control and efficiency.
Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
Named Entity Recognition (NER) is a natural language processing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. NER is an essential step in many NLP tasks, such as information extraction and text summarization.
Papers were annotated with metadata such as author affiliations, publication year, and citation count and were categorized based on methodological approaches, specific safety concerns addressed, and risk mitigation strategies. Most studies address issues related to noise and outliers, affecting model robustness and generalization.
The capability of AI to execute complex tasks efficiently is determined by image annotation, which is a key determinant of its success and is defined as the process of labeling images with descriptive metadata. AI and machine learning applications require image annotation partners to label and categorize images.
The documentation can also include DICOM or other medical images, where both metadata and text information shown on the image needs to be converted to plain text. Named entity recognition is a natural language processing technology that automatically scans full documents, extracts fundamental elements from the text, and categorizes them.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content