This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text. Unlike sequential models, LLMs optimize resource distribution, resulting in accelerated data extraction tasks.
As you already know, we recently launched our 8-hour Generative AI Primer course, a programming language-agnostic 1-day LLM Bootcamp designed for developers like you. Finally, it discusses PII masking for cloud-based LLM usage when local deployment isnt feasible. Author(s): Towards AI Editorial Team Originally published on Towards AI.
Industry Anomaly Detection and Large Vision Language Models Existing IAD frameworks can be categorized into two categories. These approaches indicate that LLM frameworks might have some applications for visual tasks. Finally, the model feeds the embeddings and original image information to the LLM. Reconstruction-based IAD.
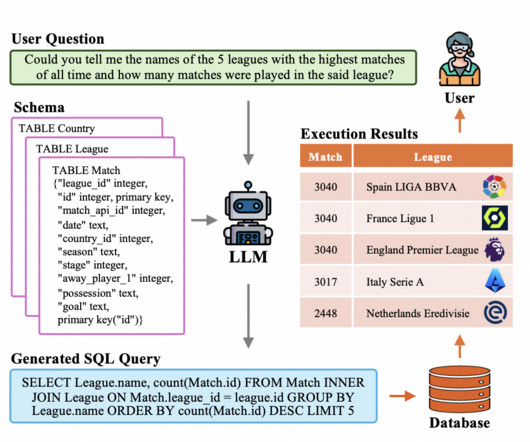
Traditional text-to-SQL systems using deep neuralnetworks and human engineering have succeeded. The LLMs have demonstrated the ability to execute a solid vanilla implementation thanks to the improved semantic parsing capabilities made possible by the larger training corpus. Join our Telegram Channel and LinkedIn Gr oup.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. No training examples are needed in LLM Development but it’s needed in Traditional Development.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests.
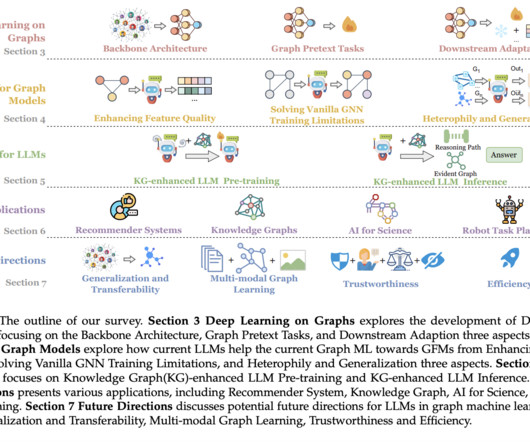
Graphs are important in representing complex relationships in various domains like social networks, knowledge graphs, and molecular discovery. Provide a thorough investigation of the potential of graph structures to address the limitations of LLMs. Alongside topological structure, nodes often possess textual features providing context.
NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience. link] The process can be categorized into three agents: Execution Agent : The heart of the system, this agent leverages OpenAI’s API for task processing.
While these large language model (LLM) technologies might seem like it sometimes, it’s important to understand that they are not the thinking machines promised by science fiction. Most experts categorize it as a powerful, but narrow AI model. Current AI advancements demonstrate impressive capabilities in specific areas.
In this hands-on session, youll start with logistic regression and build up to categorical and ordered logistic models, applying them to real-world survey data. Youll learn how to use LLMs for initial labeling, extract embeddings with models like Sentence Transformers, and build a fast, cost-effective classifier using Keras.
On our website, users can subscribe to an RSS feed and have an aggregated, categorized list of the new articles. Language embeddings are high dimensional vectors that learn their relationships with each other through the training of a neuralnetwork. Embedding vectors allow computers to model the world from language.
Studies on model-to-brain alignment suggest that certain artificial neuralnetworks encode representations that resemble those in the human brain. Their results suggest that current brain alignment benchmarks remain unsaturated, emphasizing opportunities to refine LLMs for improved alignment with human language processing.
The first component involves a neuralnetwork that evaluates the relevancy of each retrieved piece of data to the user query. The second component implements an algorithm that segments and categorizes the RAG output into scorable (objective) and non-scorable (subjective) spans. Dont Forget to join our 65k+ ML SubReddit.
A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018.
LLMs are a class of artificial intelligence systems that have been trained on massive text corpora, allowing them to generate remarkably human-like text and engage in natural conversations. Modern LLMs like OpenAI's GPT-3 contain upwards of 175 billion parameters, several orders of magnitude more than previous models.
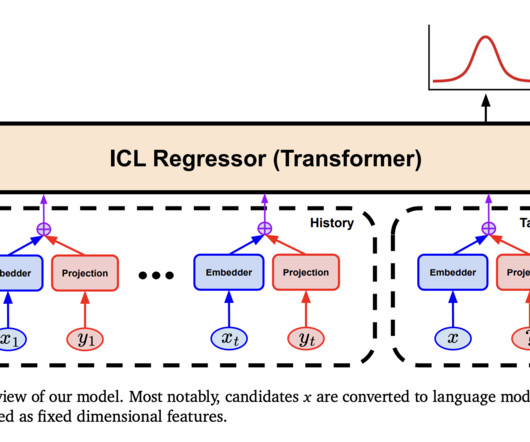
While neuralnetwork approaches like Transformers offer more flexibility, they are limited by fixed input dimensions, restricting their application to tasks with structured inputs. Their framework uses LLM-based embeddings to map strings to fixed-length vectors for tensor-based regressors, such as Transformer models.
It easily handles a mix of categorical, ordinal, and continuous features. Yet, I haven’t seen a practical implementation tested on real data in dimensions higher than 3, combining both numerical and categorical features. All categorical features are jointly encoded using an efficient scheme (“smart encoding”).
What happened this week in AI by Louie While there was plenty of newsflow in the LLM world again this week, we are also interested in how the LLM-fueled boom in AI research and AI compute capacity can accelerate other AI models. Author(s): Towards AI Editorial Team Originally published on Towards AI. Why should you care?
The same concept can be extended to other more complex models — like “neuralnetworks” (that you might have heard in the context of deep learning) or Large Language Models (often abbreviated to LLMs and are the underlying models for all text-based AI products such as Google Search, ChatGPT and Google Bard).
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Unigrams, N-grams, exponential, and neuralnetworks are valid forms for the Language Model. rely on Language Models as their foundation.
This architecture allows different parts of a neuralnetwork to specialize in different tasks, effectively dividing the workload among multiple experts. To address these challenges, parent document retrievers categorize and designate incoming documents as parent documents. Mixtral-8x7B uses an MoE architecture.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., Image processing : Predictive image processing models, such as convolutional neuralnetworks (CNNs), can classify images into predefined labels (e.g.,
If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a Large Language Model (LLM). An easy way to describe LLM is an AI algorithm capable of understanding and generating human language.
This technique combines learning capabilities and logical reasoning from neuralnetworks and symbolic AI. In contrast, the neural aspect of neuro-symbolic programming involves deep neuralnetworks like LLMs and vision models , which thrive on learning from massive datasets and excel at recognizing patterns within them.
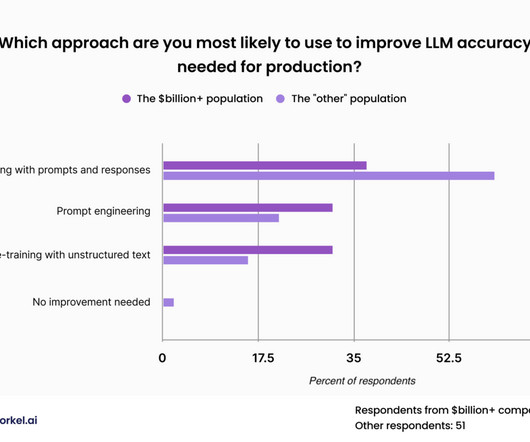
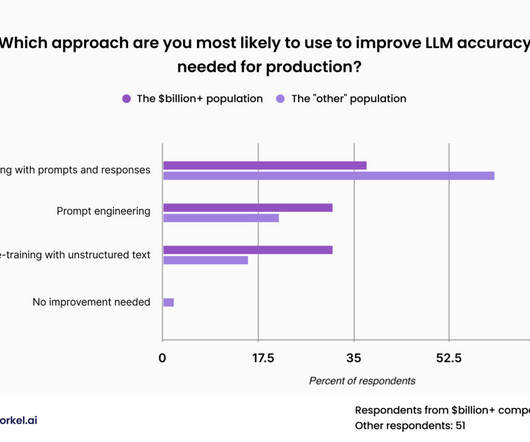
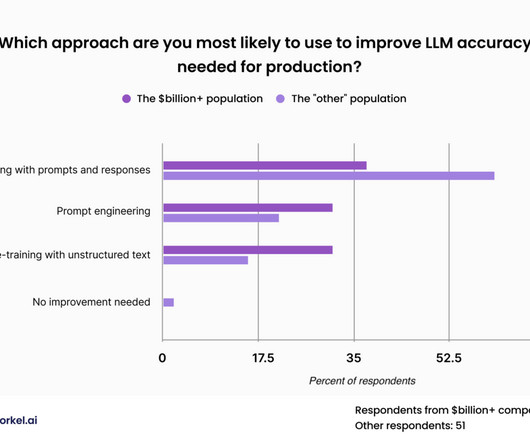
As indicated in the previous section, a majority of our respondents—and all of the respondents from companies worth at least a billion dollars—believe that off-the-shelf LLMs won’t be up to their enterprise-specific tasks and will require fine-tuning or pre-training.
As indicated in the previous section, a majority of our respondents—and all of the respondents from companies worth at least a billion dollars—believe that off-the-shelf LLMs won’t be up to their enterprise-specific tasks and will require fine-tuning or pre-training.
Fine-tuning is a process of adjusting the weights of a neuralnetwork to improve its performance on a specific task. LARs are a type of embedding that can be used to represent high-dimensional categorical data in a lower-dimensional continuous space. Dolma is a dataset of 3 trillion tokens that can be used to LLMs.
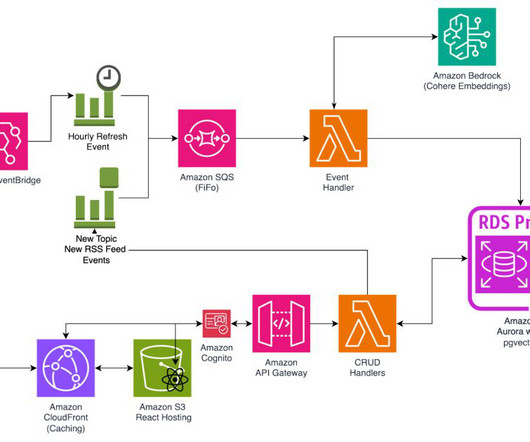
It uses neuralnetworks like BERT to measure semantic similarity beyond just exact word or phrase matching. The FMEval library provides built-in support for Amazon SageMaker endpoints and Amazon SageMaker JumpStart LLMs. You can also extend the ModelRunner interface for any LLMs hosted anywhere.
It differs from other approaches like LLMs on Graphs, which primarily focus on integrating LLMs with Graph NeuralNetworks for graph data modeling. Graph NeuralNetworks (GNNs) model this graph data using message-passing techniques to obtain node and graph-level representations.
Since the public unveiling of ChatGPT, large language models (or LLMs) have had a cultural moment. The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment.
Since the public unveiling of ChatGPT, large language models (or LLMs) have had a cultural moment. The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment.
We showcase two different sentence transformers, paraphrase-MiniLM-L6-v2 and a proprietary Amazon large language model (LLM) called M5_ASIN_SMALL_V2.0 , and compare their results. M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. Operationalization journey per generative AI user type To simplify the description of the processes, we need to categorize the main generative AI user types, as shown in the following figure.
As indicated in the previous section, a majority of our respondents—and all of the respondents from companies worth at least a billion dollars—believe that off-the-shelf LLMs won’t be up to their enterprise-specific tasks and will require fine-tuning or pre-training.
Whether it’s the original fully connected neuralnetworks, recurrent or convolutional architectures, or the transformer behemoths of the early 2020s, their performance across tasks is unparalleled. A neuralnetwork’s structure before and after pruning. What is model optimization?
In ChatGPT announcement, this end to end experience/product development is also broken as the software/logic/model for Siri and LLM will be a 3rd party and it is not clear how this experience can play into this Apple’s strength. xLSTM is a new Recurrent NeuralNetwork architecture based on ideas of the original LSTM.
Recent advancements in neuralnetwork-based tools have enabled more accurate functional annotation of proteins, identifying corresponding labels for given sequences. Descriptive data from UniProt subsections were categorized into sequence-level (e.g., function descriptions) and residue-level (e.g.,
LaMDA is built on Transformer , a neuralnetwork architecture that Google Research invented and open-sourced in 2017. The second pre-training stage performs vision-to-language generative learning by connecting the output of the Q-Former to a frozen LLM. How is the problem approached? What are the results?
TabTransformer uses Transformers to generate robust data representations — embeddings — for categorical variables, or variables that take on a finite set of discrete values, such as months of the year. The ELM approach shows that an LLM trained on code can suggest intelligent mutations for genetic programming (GP) algorithms.
Model architectures that qualify as “supervised learning”—from traditional regression models to random forests to most neuralnetworks—require labeled data for training. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks Radford et al. What are some examples of Foundation Models?
There were 2 major developments in this field, one of them was predictive modeling which relies on statistical models like Artificial NeuralNetworks (ANNs). It allowed for the development of popular LLMs like ChatGPT, allowing for better Chatbots. LLMs are thus becoming the basic building block for Large Action Models (LAMs).
Classification techniques, such as image recognition and document categorization, remain essential for a wide range of industries. From classic statistical techniques to cutting-edge neuralnetwork architectures, algorithms are essential for extracting insights from complex datasets. There wasnt a huge shift from previous years.
In this example figure, features are extracted from raw historical data, which are then are fed into a neuralnetwork (NN). In November 2022, ChatGPT was released, a large language model (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom.
Methods for continual learning can be categorized as regularization-based, architectural, and memory-based, each with specific advantages and drawbacks. Architectural methods like Progressive NeuralNetworks could be a good choice if you prioritize preserving past data over learning new concepts.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content