This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
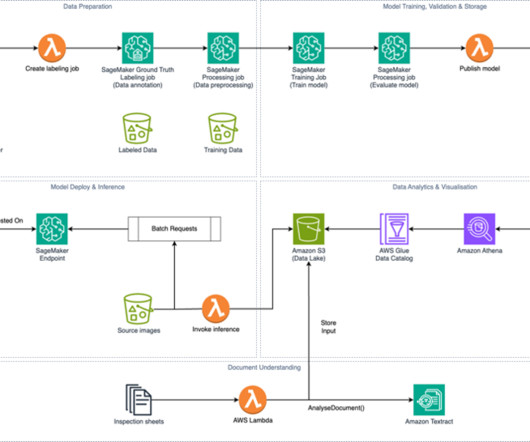
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. Next, Amazon Comprehend or custom classifiers categorize them into types such as W2s, bank statements, and closing disclosures, while Amazon Textract extracts key details.
These datasets encompass millions of hours of music, over 10 million recordings and compositions accompanied by comprehensive metadata, including key, tempo, instrumentation, keywords, moods, energies, chords, and more, facilitating training and commercial usage. GCX provides datasets with over 4.4
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. This tagging structure categorizes costs and allows assessment of usage against budgets.
The Ministry of Justice in Baden-Württemberg recommended using AI with natural language understanding (NLU) and other capabilities to help categorize each case into the different case groups they were handling. The courts needed a transparent, traceable system that protected data. Explainability will play a key role.
In this collaboration, the Generative AI Innovation Center team created an accurate and cost-efficient generative AIbased solution using batch inference in Amazon Bedrock , helping GoDaddy improve their existing product categorization system. Moreover, employing an LLM for individual product categorization proved to be a costly endeavor.
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
It’s ideal for workloads that aren’t latency sensitive, such as obtaining embeddings, entity extraction, FM-as-judge evaluations, and text categorization and summarization for business reporting tasks. It stores information such as job ID, status, creation time, and other metadata.
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information. The embeddings are stored in the Amazon OpenSearch Service owner manuals index.
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies. Ethereum is a decentralized blockchain platform that upholds a shared ledger of information collaboratively using multiple nodes.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Text, images, audio, and videos are common examples of unstructured data.
Self-managed content refers to the use of AI and neural networks to simplify and strengthen the content creation process via smart tagging, metadata templates, and modular content. Role of AI and neural networks in self-management of digital assets Metadata is key in the success of self-managing content.
Organize, Categorize, and Annotate for Deeper Insights Searchable media enables better organization and archiving of research data, allowing researchers to tag and categorize audio segments based on topics or keywords. This creates a well-organized repository that is easily accessible for future studies or follow-up research.
Asure chose this approach because it provided in-depth consumer analytics, categorized call transcripts around common themes, and empowered contact center leaders to use natural language to answer queries. The original PCA post linked previously shows how Amazon Transcribe and Amazon Comprehend are used in the metadata generation pipeline.
Some components are categorized in groups based on the type of functionality they exhibit. Some applications may need to access data with personal identifiable information (PII) while others may rely on noncritical data. For more information, see Using API Gateway with Amazon Cognito user pools.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. RAG works by using a retriever module to find relevant information from an external data store in response to a users prompt. This can be overwhelming for nontechnical users who lack proficiency in SQL.
By using prompt instructions and API descriptions, agents collect essential information from API schemas to solve specific problems efficiently. This flexibility is achieved by chaining domain-specific agents like the insurance orchestrator agent, policy information agent, and damage analysis notification agent.
The challenge here is to retrieve the relevant data source to answer the question and correctly extract information from that data source. Use cases we have worked on include: Technical assistance for field engineers – We built a system that aggregates information about a company’s specific products and field expertise.
Neglecting this preliminary stage may result in inaccurate tokenization, impacting subsequent tasks such as sentiment analysis, language modeling, or text categorization. Document Extraction: Unstructured is excellent at extracting metadata and document elements from a wide range of document types.
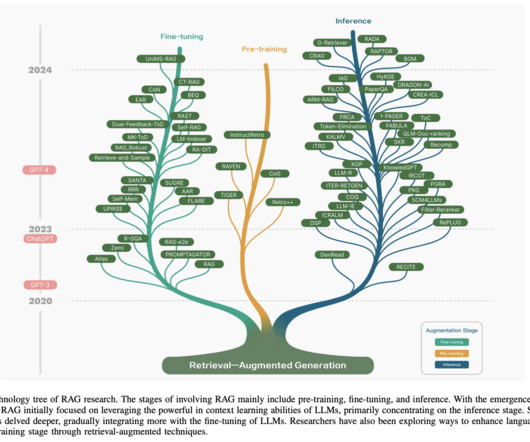
This enhances the accuracy and credibility of the generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information. The RAG research paradigm is continuously evolving, and RAG is categorized into three stages: Naive RAG, Advanced RAG, and Modular RAG.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training. No explanation is required.
By leveraging MLLM, these agents can process and synthesize vast amounts of information from various modalities, enabling them to offer personalized assistance and enhance user experiences in ways previously unimaginable. This expansion ensures that more information is preserved, aiding in decision-making.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. Model risk : Risk categorization of the model version.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. The text of the transcript is broken down into either paragraphs or sentences, along with additional metadata such as start and end timestamps or speaker information.
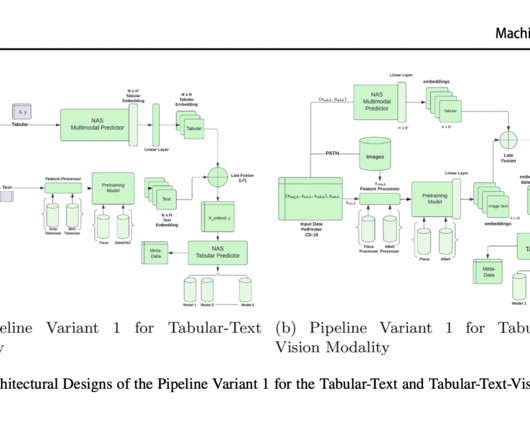
There are currently no systematic comparisons between different information fusion approaches and no generalized frameworks for multi-modality processing; these are the main obstacles to multimodal AutoML. Nevertheless, a major obstacle that many current AutoML systems encounter is the efficient and correct handling of multimodal data.
Images can often be searched using supplemented metadata such as keywords. However, it takes a lot of manual effort to add detailed metadata to potentially thousands of images. Generative AI (GenAI) can be helpful in generating the metadata automatically. This helps us build more refined searches in the image search process.
Exploring Linear Regression for Spatial Analysis Linear regression provides insightful information about spatial relationships, patterns, and trends and is a flexible and essential tool in Geographic Information Systems (GIS). This article introduces its capabilities in more detail.
Content redaction: Each customer audio interaction is recorded as a stereo WAV file, but could potentially include sensitive information such as HIPAA-protected and personally identifiable information (PII). Scalability: This architecture needed to immediately scale to thousands of calls per day and millions of calls per year.
The Pain Point: Information Overload and Missed Opportunities Every AI researcher, developer, and enthusiast has faced the frustration of missing a critical deadline be it for a conference submission or a grant application. You no longer need to worry about missed updates or outdated information. title, abstract, authors).
SageMaker Studio runs custom Python code to augment the training data and transform the metadata output from SageMaker Ground Truth into a format supported by the computer vision model training job. Northpower categorized 1,853 poles as high priority risks, 3,922 as medium priority, 36,260 as low priority, and 15,195 as the lowest priority.
It allows the model to learn from any collection of images without needing labels or metadata. This enables the model to learn more in-depth information about images, such as spatial relationships and depth estimation. This could improve product quality control and reduce the risk of defective products reaching customers.
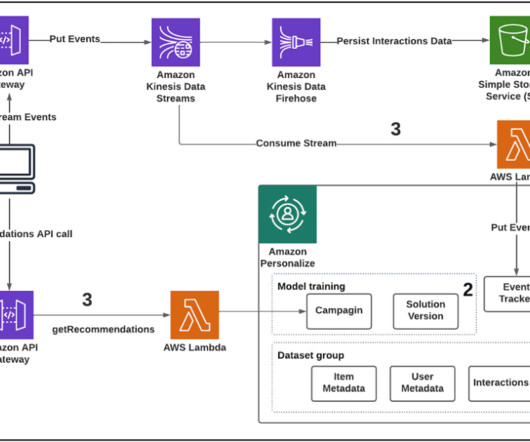
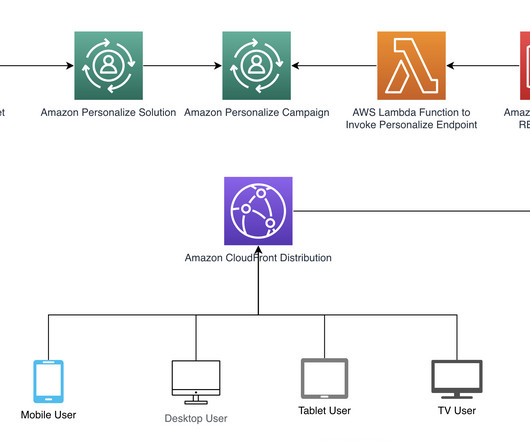
For more information, refer to Architecting near real-time personalized recommendations with Amazon Personalize. If a user has engaged with movies categorized as Drama in the item dataset, Amazon Personalize will suggest movies (items) with the same genre. The following diagram illustrates the solution architecture.
Using a user’s contextual metadata such as location, time of day, device type, and weather provides personalized experiences for existing users and helps improve the cold-start phase for new or unidentified users. Why is context important? The USER_ID , ITEM_ID , and TIMESTAMP fields are required by Amazon Personalize for this dataset.
Named Entity Recognition (NER) is a natural language processing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. NER is an essential step in many NLP tasks, such as information extraction and text summarization.
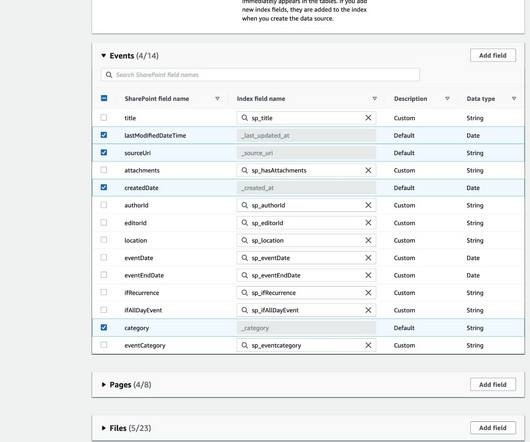
You can filter the search results based on the user and group information to ensure your search results are only shown based on user access rights. For more information, see Overview of access management: Permissions and policies. For more information, refer to SharePoint Configuration. You can now also choose OAuth 2.0
What is Clinical Data Abstraction Creating large-scale structured datasets containing precise clinical information on patient itineraries is a vital tool for medical care providers, healthcare insurance companies, hospitals, medical research, clinical guideline creation, and real-world evidence.
In AI and machine learning, data provides the ability to identify patterns and relationships between variables, and these patterns and relationships allow models to make informed decisions. Models based on AI and machine learning must have this information for them to be successful and accurate.
Highly specialized distributed learning algorithms and efficient serving mechanisms are required to process and serve such massive information in the user base and video corpus. Noise: The metadata associated with the content doesn’t have a well-defined ontology. The network uses both categorical and continuous features.
For more information about this process, refer to New — Introducing Support for Real-Time and Batch Inference in Amazon SageMaker Data Wrangler. For more information, refer to Creating roles and attaching policies (console). Use a custom transform step to create categorical values for state__c , case_count__c , and tenure features.
This allows our model to benefit from live information about what is currently trending within the student’s localized social group, in this case, their classroom. Furthermore all potentially identifiable metadata was only shared in an aggregated form, to protect students and institutions from being re-identified.
In this post, we discuss the improvements made to the Tables feature and how it makes it easier to extract information in tabular structures from a wide variety of documents. In such cases, custom postprocessing logic to identify such information or extract it separately from the API’s JSON output was necessary.
This dataset contains continuous, integer, and categorical variables that are used to predict whether the client will subscribe to a term deposit. You can view the metadata and schema of the banking dataset to understand the data attributes and columns. The following diagram illustrates the workflow. For Analysis name , enter a name.
For more information about prerequisites, see Getting started with using Amazon SageMaker Canvas. You can add metadata to the policy by attaching tags as key-value pairs, then choose Next: Review. For more information about using tags in IAM, see Tagging IAM resources. We start by getting some high-level information.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content