This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article, we will discuss PowerInfer, a high-speed LLM inferenceengine designed for standard computers powered by a single consumer-grade GPU. The PowerInfer framework seeks to utilize the high locality inherent in LLM inference, characterized by a power-law distribution in neuron activations.
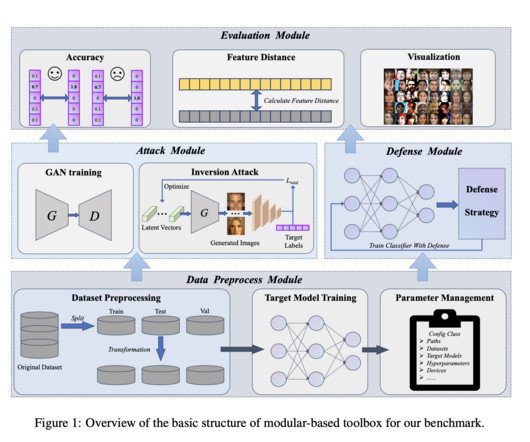
Although to defend against MI attacks, most existing methods can be categorized into two types: model output processing and robust model training. Based on the accessibility to the target model’s parameters, researchers categorized MI attacks into white-box and black-box attacks. If you like our work, you will love our newsletter.
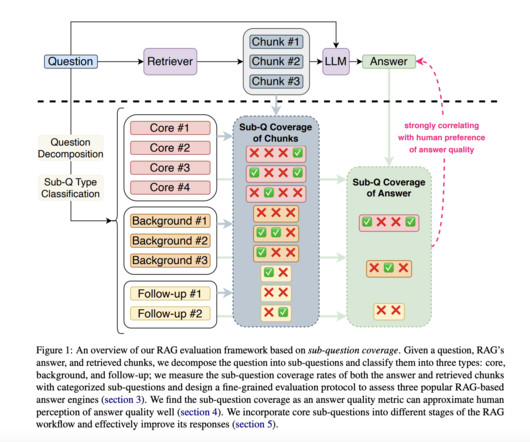
Instead of general relevance scores, the researchers propose decomposing a question into specific sub-questions, categorized as core, background, or follow-up. The Georgia Institute of Technology and Salesforce AI Research researchers introduce a new framework for evaluating RAG systems based on a metric called “sub-question coverage.”
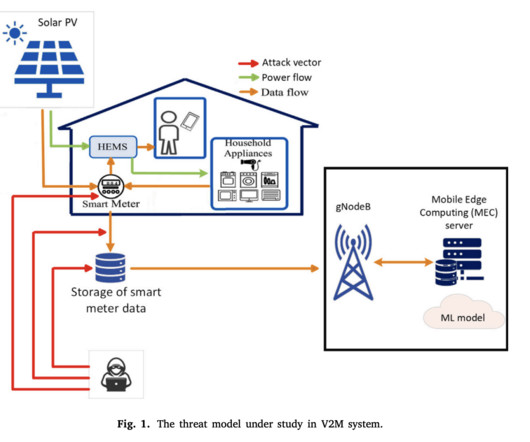
Classifier-1 only transmits authentic requests to Classifier-2, categorizing them as low, medium, or high priority. The research team then trains a binary classifier, classifier-1, using the enhanced dataset to detect valid samples while filtering out malicious material. If you like our work, you will love our newsletter.
Also, the system incorporates a co-designed grammar and inferenceengine, enabling it to overlap grammar computations with GPU-based LLM operations, thereby minimizing overhead. This separation significantly reduces the computational burden during output generation. XGrammar’s technical implementation includes several key innovations.
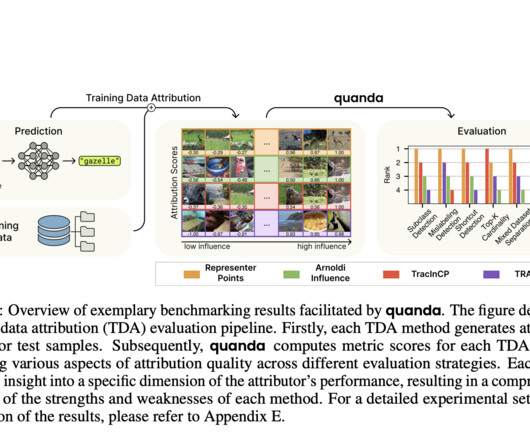
Additionally, a metric can be categorized into three types: ground_truth, downstream_evaluation, or heuristic. Metrics summarize the performance and reliability of a TDA method in a compact form.Quanda’s stateful Metric design includes an update method for accounting for new test batches. Don’t Forget to join our 50k+ ML SubReddit.
It uses formal languages, like first-order logic, to represent knowledge and an inferenceengine to draw logical conclusions based on user queries. Neuro-symbolic AI approaches can be broadly categorized into two main types: Compressing structured symbolic knowledge into a format that can be integrated with neural network patterns.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










Let's personalize your content