This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Natural Language Processing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. The introduction of word embeddings, most notably Word2Vec, was a pivotal moment in NLP. One-hot encoding is a prime example of this limitation.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
Natural language processing ( NLP ), while hardly a new discipline, has catapulted into the public consciousness these past few months thanks in large part to the generative AI hype train that is ChatGPT. ‘Data-centric’ NLP With NLP one of the hot AI trends of the moment, Kern AI today announced that it has raised €2.7
We have used machine learning models and natural language processing (NLP) to train and identify distress signals. We have categorized the posts into two main categories– those seeking help and those that do not. This advanced application of data science for humanitarian aid would bring us closer to society and change the world.
Beyond the simplistic chat bubble of conversational AI lies a complex blend of technologies, with natural language processing (NLP) taking center stage. NLP translates the user’s words into machine actions, enabling machines to understand and respond to customer inquiries accurately. What makes a good AI conversationalist?
In this post, we explore why GraphRAG is more comprehensive and explainable than vector RAG alone, and how you can use this approach using AWS services and Lettria. Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect.
It turns out that almost all of these LLMs (open-sourced) and projects deal with major security concerns, which the experts have categorized as follows: 1. Anyone can inject any malicious nlp masked command, which can cross multiple channels and severely affect the entire software chain.
Consequently, there’s been a notable uptick in research within the natural language processing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations.
Snorkel AI has thoroughly explained weak supervision elsewhere, but I will explain the concept briefly here. Expanding weak supervision to new frontiers Addressing non-categorical problems through weak supervision, particularly in ranking scenarios, underscores the versatility and power of this approach.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. Natural Language Processing (NLP) is a subfield of artificial intelligence.
This article will delve into the significance of NER (Named Entity Recognition) detection in OCR (Optical Character Recognition) and showcase its application through the John Snow Labs NLP library with visual features installed. How does Visual NLP come into action? What are the components that will be used for NER in Visual NLP?
Introducing Natural Language Processing (NLP) , a branch of artificial intelligence (AI) specifically designed to give computers the ability to understand text and spoken words in much the same way as human beings. Text Classification : Categorizing text into predefined categories based on its content. So, how do they do that?
This post explains a generative artificial intelligence (AI) technique to extract insights from business emails and attachments. It examines how AI can optimize financial workflow processes by automatically summarizing documents, extracting data, and categorizing information from email attachments. pip install unstructured !pip
The researchers emphasized that transformers utilize an old-school method similar to support vector machines (SVM) to categorize data into relevant and non-relevant information. This study explains the underlying process of information retrieval within the attention mechanism.
SA is a very widespread Natural Language Processing (NLP). Hence, whether general domain ML models can be as capable as domain-specific models is still an open research question in NLP. So, to make a viable comparison, I had to: Categorize the dataset scores into Positive , Neutral , or Negative labels. First, I must be honest.
Natural language processing (NLP) can help with this. In this post, we’ll look at how natural language processing (NLP) may be utilized to create smart chatbots that can comprehend and reply to natural language requests. What is NLP? Sentiment analysis, language translation, and speech recognition are a few NLP applications.
A practical guide on how to perform NLP tasks with Hugging Face Pipelines Image by Canva With the libraries developed recently, it has become easier to perform deep learning analysis. Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more.
Voice-based queries use Natural Language Processing (NLP) and sentiment analysis for speech recognition. This communication can involve speech recognition, speech-to-text conversion, NLP, or text-to-speech. Google Translate uses NLP to translate words across more than 130 languages.
Enter Natural Language Processing (NLP) and its transformational power. This is the promise of NLP: to transform the way we approach legal discovery. The seemingly impossible chore of sorting through mountains of legal documents can be accomplished with astonishing efficiency and precision using NLP.
In this article, I am going to explain in detail step-by-step approaches or stages of the machine learning project lifecycle. NLP Project: Speech recognition, chatbots, …. Also, we need to handle any missing values present if any, and make sure that we should normalize the numerical data or encode the categorical data.
Achieving these feats is accomplished through a combination of sophisticated algorithms, natural language processing (NLP) and computer science principles. NLP techniques help them parse the nuances of human language, including grammar, syntax and context. Most experts categorize it as a powerful, but narrow AI model.
Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging. In this post, we explain how to integrate different AWS services to provide an end-to-end solution that includes data extraction, management, and governance. We explain this in detail later in this post.
Summary: This tutorial provides a comprehensive guide on Softmax Regression, explaining its principles and implementation using NumPy and PyTorch. Some of its key applications include image classification, text categorization, and more. It handles scenarios where data points can belong to more than two classes. cars, trees, buildings).Recognizing
Only a small portion of the improvement made by self-supervised models in NLP and CV has yet been produced by low-data modeling attempts by fine-tuning from these models. They comprise jobs at the graph level and node level, as well as quantum, chemical, and biological aspects, categorical and continuous data points.
In this blog post, I’m going to discuss some of the biggest challenges for applied NLP and translating business problems into machine learning solutions. This blog post is based on talks I gave at the “Teaching NLP” workshop at NAACL 2021 and the L3-AI online conference. I call this “Applied NLP Thinking”. So where do you start?
In this use case, we have a set of synthesized product reviews that we want to analyze for sentiments and categorize the reviews by product type, to make it easy to draw patterns and trends that can help business stakeholders make better informed decisions. Next, we explain how to review the trained model for performance.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., ” Even for seasoned programmers, the syntax of shell commands might need to be explained. rely on Language Models as their foundation.
But if you’re working on the same sort of Natural Language Processing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them? In 2014 I started working on spaCy , and here’s an excerpt of how I explained the motivation for the library: Computers don’t understand text.
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art natural language processing (NLP) model to find useful signals in text. In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. Solution overview.
Excel VBA Script Explainer uses AI to explain Excel VBA code, while the Excel VBA Script Generator creates VBA scripts. The Google Sheets Formula Generator and the Google Apps Script Explainer use artificial intelligence to analyze and clarify scripts. The use of AI hopes to speed up the process of formula creation.
Photo by Oleg Laptev on Unsplash By improving many areas of content generation, optimization, and analysis, natural language processing (NLP) plays a crucial role in content marketing. Artificial intelligence (AI) has a subject called natural language processing (NLP) that focuses on how computers and human language interact.
This post explains the components of this new approach, and shows how they’re put together in two recent systems. Most NLP problems can be reduced to machine learning problems that take one or more texts as input. However, most NLP problems require understanding of longer spans of text, not just individual words.
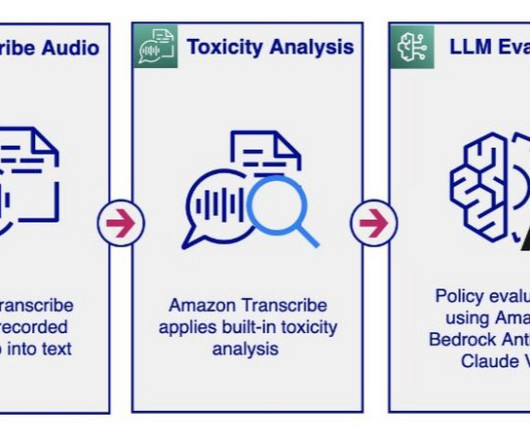
The LLM analysis provides a violation result (Y or N) and explains the rationale behind the model’s decision regarding policy violation. The Anthropic Claude V2 model delivers responses in the instructed format (Y or N), along with an analysis explaining why it thinks the message violates the policy.
Explain The Concept of Supervised and Unsupervised Learning. It involves tasks such as handling missing values, removing outliers, encoding categorical variables, and scaling numerical features. Explain The Concept of Overfitting and Underfitting In Machine Learning Models.
Advances in Natural Language Processing: Improvements in NLP have made it possible for AI agents to better understand and respond to human language, particularly useful in interactive applications. Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches.
Solution overview The following diagram is a high-level reference architecture that explains how you can further enhance an IDP workflow with foundation models. Amazon Comprehend is a natural language processing (NLP) service that uses ML to extract insights from text. You can also fine-tune them for specific document classes.
Source: Author Introduction Text classification, which involves categorizing text into specified groups based on its content, is an important natural language processing (NLP) task. It also provides a wide range of packages and features designed specifically for NLP and text classification. Curious to see how Comet works?
Source: Author The field of natural language processing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce natural language, NLP opens up a world of research and application possibilities.
This can make it challenging for businesses to explain or justify their decisions to customers or regulators. The company is best known for NLP tools, but also enables the use of computer vision, audio, and multimodal models. The cloud-based NLP platform enables developers to create and deploy custom NLP models for use in applications.
Algorithms like AdaBoost, XGBoost, and LightGBM power real-world finance, healthcare, and NLP applications. Boosting is widely used in finance, healthcare, NLP, and fraud detection applications. CatBoost (Categorical Boosting) CatBoost handles categorical data , like names, colours, or product types, without requiring extra processing.
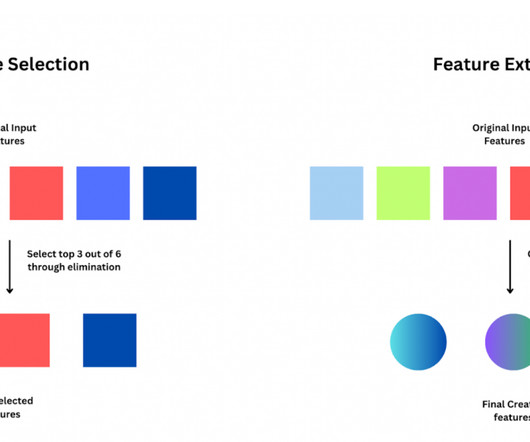
Age, No of products, and categorical features (Gender, Country, etc). In NLP models based on text datasets, features can be the frequency of specific terms, sentence similarity, etc. Improved explainability makes it easier to justify compliance and data privacy regulations in financial and healthcare models.
In order to develop training data for AI and machine learning, there are several types of image annotation as explained below: Bounding Box Annotation As a type of image annotation technique, bounding box annotation is used to outline the boundaries of objects. There are multiple ways to annotate images, each using a different approach.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content