This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate? This is where LLMs come into play.
King’s College London researchers have highlighted the importance of developing a theoretical understanding of why transformer architectures, such as those used in models like ChatGPT, have succeeded in naturallanguageprocessing tasks.
In this post, we explore why GraphRAG is more comprehensive and explainable than vector RAG alone, and how you can use this approach using AWS services and Lettria. Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect.
We have used machine learning models and naturallanguageprocessing (NLP) to train and identify distress signals. We have categorized the posts into two main categories– those seeking help and those that do not.
Source: Author The field of naturallanguageprocessing (NLP), which studies how computer science and human communication interact, is rapidly growing. By enabling robots to comprehend, interpret, and produce naturallanguage, NLP opens up a world of research and application possibilities.
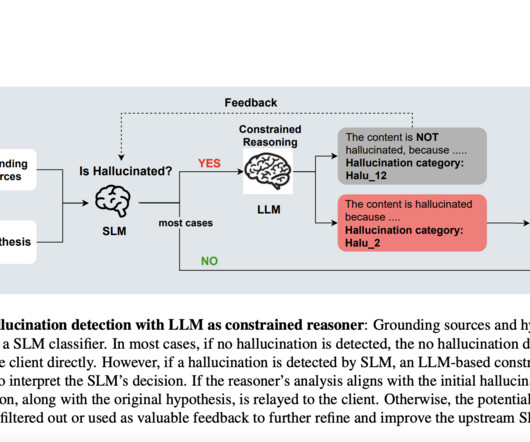
Large Language Models (LLMs) have demonstrated remarkable capabilities in various naturallanguageprocessing tasks. ” The SLM performs initial hallucination detection, while the LLM module explains the detected hallucinations. The methodology focuses on three primary approaches: 1.
Consequently, there’s been a notable uptick in research within the naturallanguageprocessing (NLP) community, specifically targeting interpretability in language models, yielding fresh insights into their internal operations. Recent approaches automate circuit discovery, enhancing interpretability.
The attention mechanism has played a significant role in naturallanguageprocessing and large language models. The researchers emphasized that transformers utilize an old-school method similar to support vector machines (SVM) to categorize data into relevant and non-relevant information. Check out the Paper.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. No explanation is required.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. NaturalLanguageProcessing (NLP) is a subfield of artificial intelligence.
NaturalLanguageProcessing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. GPT : Is generative in nature and can be prompted to perform tasks with minimal changes to its structure. One-hot encoding is a prime example of this limitation.
A foundation model is built on a neural network model architecture to process information much like the human brain does. They can also perform self-supervised learning to generalize and apply their knowledge to new tasks. The platform comprises three powerful products: The watsonx.ai
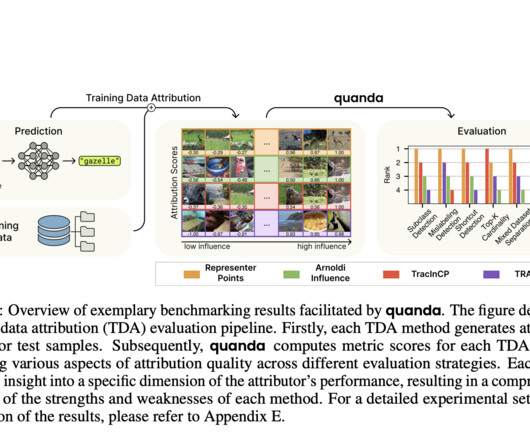
XAI, or Explainable AI, brings about a paradigm shift in neural networks that emphasizes the need to explain the decision-making processes of neural networks, which are well-known black boxes. Quanda differs from its contemporaries, like Captum, TransformerLens, Alibi Explain, etc.,
Defining AI Agents At its simplest, an AI agent is an autonomous software entity capable of perceiving its surroundings, processing data, and taking action to achieve specified goals. Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches.
Summary: This tutorial provides a comprehensive guide on Softmax Regression, explaining its principles and implementation using NumPy and PyTorch. It covers the softmax function, cross-entropy loss, and training process, making it suitable for beginners and experienced learners alike. cars, trees, buildings).Recognizing
SA is a very widespread NaturalLanguageProcessing (NLP). So, to make a viable comparison, I had to: Categorize the dataset scores into Positive , Neutral , or Negative labels. Interestingly, ChatGPT tended to categorize most of these neutral sentences as positive. finance, entertainment, psychology).
Naturallanguageprocessing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., rely on Language Models as their foundation. Unigrams, N-grams, exponential, and neural networks are valid forms for the Language Model.
Introducing NaturalLanguageProcessing (NLP) , a branch of artificial intelligence (AI) specifically designed to give computers the ability to understand text and spoken words in much the same way as human beings. Text Classification : Categorizing text into predefined categories based on its content. How it works?
Beyond the simplistic chat bubble of conversational AI lies a complex blend of technologies, with naturallanguageprocessing (NLP) taking center stage. Also, conversational AI systems can manage and categorize support tickets, prioritizing them based on urgency and relevance.
In this use case, we have a set of synthesized product reviews that we want to analyze for sentiments and categorize the reviews by product type, to make it easy to draw patterns and trends that can help business stakeholders make better informed decisions. Next, we explain how to review the trained model for performance.
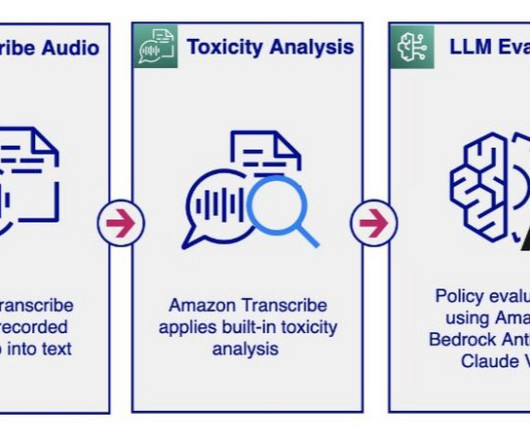
The LLM analysis provides a violation result (Y or N) and explains the rationale behind the model’s decision regarding policy violation. The Anthropic Claude V2 model delivers responses in the instructed format (Y or N), along with an analysis explaining why it thinks the message violates the policy.
In the ever-evolving landscape of machine learning and artificial intelligence, understanding and explaining the decisions made by models have become paramount. Enter Comet , that streamlines the model development process and strongly emphasizes model interpretability and explainability. Why Does It Matter?
Surprisingly, recent developments in self-supervised learning, foundation models for computer vision and naturallanguageprocessing, and deep understanding have significantly increased data efficiency. However, most training datasets in the present literature on treatments have small sample sizes.
Naturallanguageprocessing ( NLP ), while hardly a new discipline, has catapulted into the public consciousness these past few months thanks in large part to the generative AI hype train that is ChatGPT. million ($2.9
In this solution, we train and deploy a churn prediction model that uses a state-of-the-art naturallanguageprocessing (NLP) model to find useful signals in text. In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields.
While these large language model (LLM) technologies might seem like it sometimes, it’s important to understand that they are not the thinking machines promised by science fiction. Achieving these feats is accomplished through a combination of sophisticated algorithms, naturallanguageprocessing (NLP) and computer science principles.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. Naturallanguageprocessing: Helps computers understand and generate human language, powering chatbots, and machine translation.
Voice-based queries use NaturalLanguageProcessing (NLP) and sentiment analysis for speech recognition. For instance, email management automation tools such as Levity use ML to identify and categorize emails as they come in using text classification algorithms. The platform has three powerful components: the watsonx.ai
From image and speech recognition to naturallanguageprocessing and predictive analytics, ML models have been applied to a wide range of problems. If your predictors include categorical features, you can provide a JSON file named cat_index.json in the same location as your training data.
Explain The Concept of Supervised and Unsupervised Learning. It involves tasks such as handling missing values, removing outliers, encoding categorical variables, and scaling numerical features. Explain The Concept of Overfitting and Underfitting In Machine Learning Models.
Let me explain. Zero-Shot Classification Imagine you want to categorize unlabeled text. Transformers is a library in Hugging Face that provides APIs and tools. It allows you to easily download and train state-of-the-art pre-trained models. You may ask what pre-trained models are. Let’s have a look at a few of these.
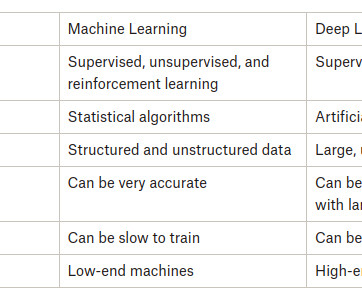
Supervised, unsupervised, and reinforcement learning : Machine learning can be categorized into different types based on the learning approach. Interpretability and Explainability: Deep neural networks are one machine learning model that can be very complex and difficult to assess.
Yet not all chatbots are made equal, and some are more adept than others in deciphering and answering naturallanguage questions. Naturallanguageprocessing (NLP) can help with this. Recognition of named entities , such as individuals, locations, and organizations, involves identifying and categorizing them.
This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy. This can make it challenging for businesses to explain or justify their decisions to customers or regulators.
Named Entity Recognition (NER) is a pivotal tool in understanding documents because it identifies and categorizes specific entities mentioned within the text. It streamlines tasks such as information retrieval, summarization, and knowledge extraction, enhancing the efficiency of various naturallanguageprocessing applications.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately? However, in this sea of complexity, NLP offers a ray of hope.
Visual Question Answering (VQA) stands at the intersection of computer vision and naturallanguageprocessing, posing a unique and complex challenge for artificial intelligence. is a significant benchmark dataset in computer vision and naturallanguageprocessing. or Visual Question Answering version 2.0,
Using causal graphs, LIME, Shapley, and the decision tree surrogate approach, the organization also provides various features to make it easier to develop explainability into predictive analytics models. When necessary, the platform also enables numerous governance and explainability elements.
While integrating deep learning into software development can be difficult, it has made significant progress in several fields, including computer vision, naturallanguageprocessing, and speech recognition. Speech and Audio Processing : Speaker identification, speech recognition, creation of music, etc.
In order to develop training data for AI and machine learning, there are several types of image annotation as explained below: Bounding Box Annotation As a type of image annotation technique, bounding box annotation is used to outline the boundaries of objects. In this process, a box is drawn around the object and a label is applied.
This enhances the interpretability of AI systems for applications in computer vision and naturallanguageprocessing (NLP). Furthermore, attention mechanisms work to enhance the explainability or interpretability of AI models. In a way, you can consider it offering a window into the “thought processes” of AI.
Unsupervised learning helps in finding the features which are useful for categorization It takes place in real-time, which implies that all the input data is essential to be analyzed and labeled in the presence of the users. It employs unsupervised learning to categorize articles on the same news story from different online news outlets.
Solution overview The following diagram is a high-level reference architecture that explains how you can further enhance an IDP workflow with foundation models. Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to extract insights from text.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content