This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
This problem is harder for audio because audio data is far more information-dense than text. A joint audio-language model trained on suitably expansive datasets of audio and text could learn more universal representations to transfer robustly across both modalities.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categorical data effectively. CatBoost automatically transforms them, making it ideal for datasets with many categorical variables.
The Ministry of Justice in Baden-Württemberg recommended using AI with natural language understanding (NLU) and other capabilities to help categorize each case into the different case groups they were handling. Explainability will play a key role. The courts needed a transparent, traceable system that protected data.
Content creators like bloggers and social media managers can use HARPA AI to generate content ideas, optimize posts for SEO, and summarize information from various sources. E-commerce professionals can use HARPA AI to track prices and products across platforms to stay informed about market trends and competitor offerings.
Scope 3 emissions disclosure Envizi’s Scope 3 GHG Accounting and Reporting module enables the capture of upstream and downstream GHG emissions data, calculates emissions using a robust analytics engine and categorizes emissions by value chain supplier, data type, intensities and other metrics to support auditability.
Services like OpenAIs Deep Research are very good at internet-based research projects like, say, digging up background information for a Vox piece. Generative AIs like Dall-E, Sora, or Midjourney are actively competing with human visual artists; theyve already noticeably reduced demand for freelance graphic design.
In a world where decisions are increasingly data-driven, the integrity and reliability of information are paramount. In this post, we explore why GraphRAG is more comprehensive and explainable than vector RAG alone, and how you can use this approach using AWS services and Lettria.
There are major worries about data traceability and reproducibility because, unlike code, data modifications do not always provide enough information about the exact source data used to create the published data and the transformations made to each source. This information will then be indexed as part of a data catalog.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information.
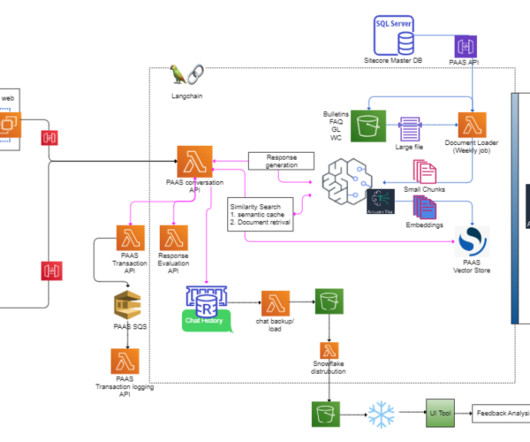
Verisks Premium Audit Advisory Service (PAAS) is the leading source of technical information and training for premium auditors and underwriters. Verisk needed to make sure its responses are based on the most current information.
With the large amounts of data generated daily, effective data visualization helps visualize patterns and relationships, easily share information, and explore opportunities. Fundamentals of Data Visualization This book provides a guide to making informative and compelling figures that help convey a compelling story.
Through a practical use case of processing a patient health package at a doctors office, you will see how this technology can extract and synthesize information from all three document types, potentially improving data accuracy and operational efficiency. For more information, see Create a guardrail.
It is known that, similar to the human brain, AI systems employ strategies for analyzing and categorizing images. Thus, there is a growing demand for explainability methods to interpret decisions made by modern machine learning models, particularly neural networks.
These fingerprints can then be analyzed by a neural network, unveiling previously inaccessible information about material behavior. As Argonne postdoctoral researcher James (Jay) Horwath explains, “The way we understand how materials move and change over time is by collecting X-ray scattering data.”
Lucena attributes its dominance to the way gradient boosted decision trees (GBDTs) handle structured information. Lucena explained how random forests first introduced the power of ensembles, but gradient boosting takes it a step further by focusing on the residual errors from previous trees. seasons, time ofday).
It turns out that almost all of these LLMs (open-sourced) and projects deal with major security concerns, which the experts have categorized as follows: 1. This malicious act aims to compromise the integrity and reliability of the LLM by injecting misleading or harmful information during the training process.
In this video, he breaks down how you can benefit from an AI voice Gatekeeper, which will answer for you and record the information of the caller. It explains how GNNs interpret nodes and edges, using examples like cities connected by roads. You can also get the blueprint and prompts to make it yourself. AI poll of the week!
In this post, I will discuss the common problems with existing solutions, explain why I am no longer a fan of Kaggle, propose a better solution, and outline a personalized prediction approach. This information is essential for feature engineering, model selection, and evaluation downstream. All three are labelled with numbers.
One-hot encoding is a process by which categorical variables are converted into a binary vector representation where only one bit is “hot” (set to 1) while all others are “cold” (set to 0). It results in sparse and high-dimensional vectors that do not capture any semantic or syntactic information about the words.
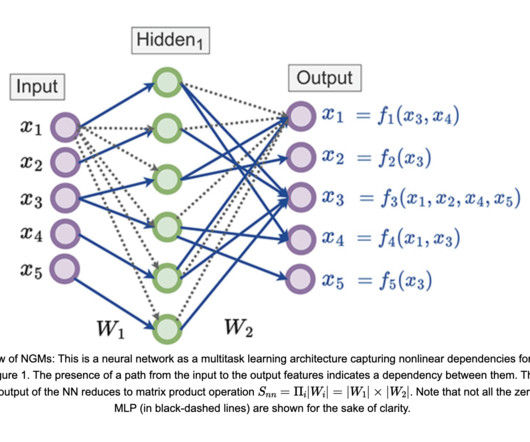
Many graphical models are designed to work exclusively with continuous or categorical variables, limiting their applicability to data that spans different types. Moreover, specific restrictions, such as continuous variables not being allowed as parents of categorical variables in directed acyclic graphs (DAGs), can hinder their flexibility.
Well-known examples of virtual assistants include Apple’s Siri, Amazon Alexa and Google Assistant, primarily used for personal assistance, home automation, and delivering user-specific information or services. It aids businesses in gathering and analyzing data to inform strategic decisions. What makes a good AI conversationalist?
The challenge here is to retrieve the relevant data source to answer the question and correctly extract information from that data source. Use cases we have worked on include: Technical assistance for field engineers – We built a system that aggregates information about a company’s specific products and field expertise.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process.
However, the challenge lies in integrating and explaining multimodal data from various sources, such as sensors and images. AI models are often sensitive to small changes, necessitating a focus on trustworthy AI that emphasizes explainability and robustness.
For more information, see AWS managed policy: AmazonSageMakerCanvasAIServicesAccess. For more information, see Model access. Linear categorical to categorical correlation is not supported. Features that are not either numeric or categorical are ignored.
Sparks of concern To start with, let me explain how AI models such as ChatGPT function. And sometimes that data includes sensitive information about people and organizations. This sparks public concerns about privacy, transparency, and control over personal information on the internet.
Before explaining data sovereignty, let us understand a broader concept—digital sovereignty—first. The Digital India Bill 2023 aims to replace India’s existing Information Technology Act of 2000 and provide comprehensive oversight of the digital landscape. First, we must understand how data sovereignty came to be.
This tutorial will explain how to quickly transcribe audio or video files in Python applications using the Best and Nano tiers with our Speech-to-Text API. Next, there are many further features that AssemblyAI offers beyond transcription to explore, such as: Entity detection to automatically identify and categorize key information.
To extract key information from high volumes of documents from emails and various sources, companies need comprehensive automation capable of ingesting emails, file uploads, and system integrations for seamless processing and analysis. Finding relevant information that is necessary for business decisions is difficult.
Existing surveys detail a range of techniques utilized in Explainable AI analyses and their applications within NLP. The LM interpretability approaches discussed are categorized based on two dimensions: localizing inputs or model components for predictions and decoding information within learned representations.
But, unlike humans, AGIs don’t experience fatigue or have biological needs and can constantly learn and process information at unimaginable speeds. Most experts categorize it as a powerful, but narrow AI model. The AGI would need to handle uncertainty and make decisions with incomplete information.
What’s different is that generative AI can provide relevant information for the search query in the users’ language of choice, minimizing effort for translation services. Watsonx.governance is providing an end-to-end solution to enable responsible, transparent and explainable AI workflows. Watsonx.ai
However, while it is well known that the attention mechanism enables models to focus on the most relevant information, the intricacies and specific mechanisms underlying this process of focusing on the most relevant input part are yet unknown. In the case of transformers, the categories are relevant and irrelevant information within the text.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests. A temperature of 0.0
A foundation model is built on a neural network model architecture to process information much like the human brain does. The term “foundation model” was coined by the Stanford Institute for Human-Centered Artificial Intelligence in 2021. The platform comprises three powerful products: The watsonx.ai
Evaluate and categorize the components of procurement costs, from direct costs—such as the costs of goods and services—to indirect costs—such as administrative expenses and overhead. Communicate the opportunities these changes bring and explain their benefits for stakeholders. Be flexible.
In the ever-evolving landscape of machine learning and artificial intelligence, understanding and explaining the decisions made by models have become paramount. Enter Comet , that streamlines the model development process and strongly emphasizes model interpretability and explainability. Why Does It Matter?
Transparency and explainability : Making sure that AI systems are transparent, explainable, and accountable. However, explaining why that decision was made requires next-level detailed reports from each affected model component of that AI system. Model risk : Risk categorization of the model version.
For example, AssemblyAI’s Conversational Summarization Model is informed by an innovative area of research called Reinforcement Learning (RL). From Stable Diffusion to Large Language Models to Poisson Flow Generative Models, powerful AI models are behind some of today’s most exciting and cutting-edge technology.
This explains the existence of both incident and problem management, two important processes for issue and error control, maintaining uptime, and ultimately, delivering a great service to customers and other stakeholders. Problem logging and categorization: The IT team now must log the identified problem and track each occurrence.
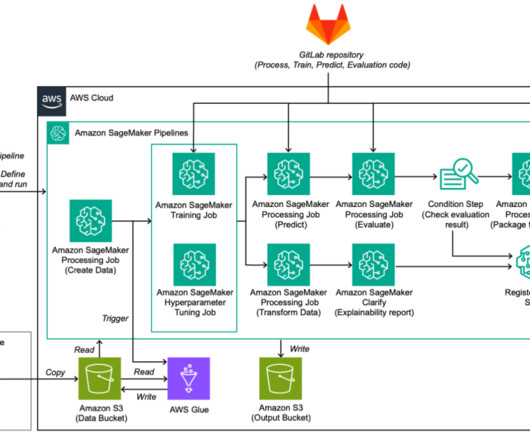
Essential ML capabilities such as hyperparameter tuning and model explainability were lacking on premises. In both cases, the evaluation and explainability report, if generated, are recorded in the model registry. Explain – SageMaker Clarify generates an explainability report. AWS_ACCOUNT] region = eu-central-1.
Text Classification : Categorizing text into predefined categories based on its content. Similarly, review websites and e-commerce platforms use it to automatically analyze and summarize customer feedback, allowing potential customers to make informed decisions. Machine Translation : Translating text from one language to another.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content