This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
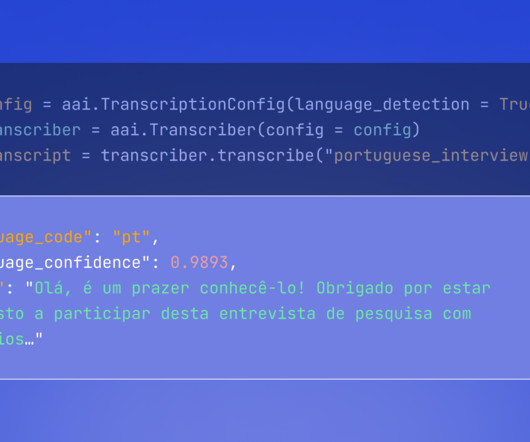
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
Stphan Donz is the founder and CEO of AODocs, a cloud-native document management platform that transforms enterprise content into actionable intelligence. Unlike legacy systems limited to basic storage, AODocs combines robust document control with workflow automation, enabling businesses to streamline complex processes across industries.
For instance, AI can streamline the organization and categorization of files needed for review by investors or buyers, reducing human error and ensuring compliance with regulatory requirements. AI and and generative AI can automate many of the manual, time-consuming tasks that are critical to the due diligence process.
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
Tennr is using artificial intelligence (AI) to revolutionize how healthcare organizations manage and process the mountains of documents that flow through their practices daily. These models read, categorize, and respond to the complex, often messy documents that pass between healthcare providers.
Here’s an example of a workflow a company could build to use these models together: Take a customer support call: The system transcribes the conversation, identifies the customer's issue through NLP, detects frustration through sentiment analysis, categorizes the problem type, and flags important moments for review.
I have included a mix of project management, brainstorming, document, and coding collaboration platforms to give a full view. ClickUp All-in-One Collaboration with AI Brain ClickUp is an all-in-one workspace that combines project management, documents, whiteboards, and chat. Visit Miro 2. Visit Teamwork 5.
The platform is great for how it structures meeting content—automatically categorizing discussions, flagging action items, and making sure nothing falls through the cracks. Smart tagging system : Automatically categorizes support interactions by topic, sentiment, and urgency to help teams prioritize effectively.
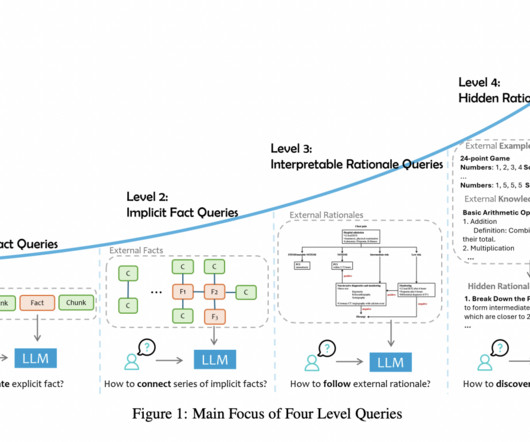
Researchers at Microsoft Research Asia introduced a novel method that categorizes user queries into four distinct levels based on the complexity and type of external data required. The categorization helps tailor the model’s approach to retrieving and processing data, ensuring it selects the most relevant information for a given task.
The judiciary, like the legal system in general, is considered one of the largest “text processing industries” Language, documents, and texts are the raw material of legal and judicial work. As such, the judiciary has long been a field ripe for the use of technologies like automation to support the processing of documents.
With AI-powered features like text recognition, content categorization, and smart search, Evernote ensures that users can quickly locate notes, even within images or scanned documents. Users can create notebooks, categorize content, and collaborate in real time with colleagues.
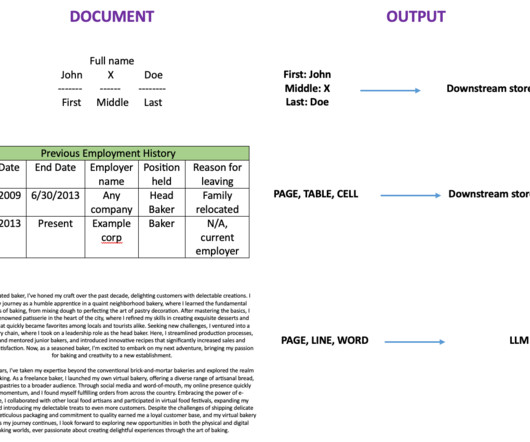
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizingdocuments is an important first step in IDP systems.
A Unified Work Management Platform for Every Industry SmartSuite delivers an all-in-one solution that combines project management, process automation, document collaboration, and real-time team coordination. SmartSuites no-code approach is reshaping how teams collaborate, plan, and executeall within a single, intuitive platform.
Customer Service and Support Speech AI technology provides more accurate, insightful call analysis by automatically categorizing, summarizing, and extracting actionable insights from customer calls—such as flagging questions and complaints.
Enterprise documents like contracts, reports, invoices, and receipts come with intricate layouts. These documents may be automatically interpreted and analyzed, which is useful and can result in the creation of AI-driven solutions. Visual documents frequently have fragmented text sections, erratic layouts, and varied information.
The following use cases are well-suited for prompt caching: Chat with document By caching the document as input context on the first request, each user query becomes more efficient, enabling simpler architectures that avoid heavier solutions like vector databases. Please follow these detailed instructions:" "nn1.
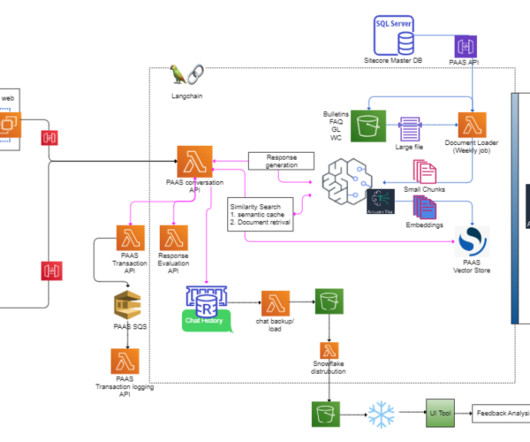
PAAS now includes PAAS AI, the first commercially available interactive generative-AI chats specifically developed for premium audit, which reduces research time and empower users to make informed decisions by answering questions and quickly retrieving and summarizing multiple PAAS documents like class guides, bulletins, rating cards, etc.
It would take weeks to filter and categorize all of the information to identify common issues or patterns. By using Audio Intelligence, LLMs and frameworks, companies can build on top of ASR to create tools that categorize content, increase searchability, aid in podcast or video editing, and intelligently synthesize this information.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
Based on this, it makes an educated guess about the importance of incoming emails, and categorizes them into specific folders. In addition to the smart categorization of emails, SaneBox also comes with a feature named SaneBlackHole, designed to banish unwanted emails.
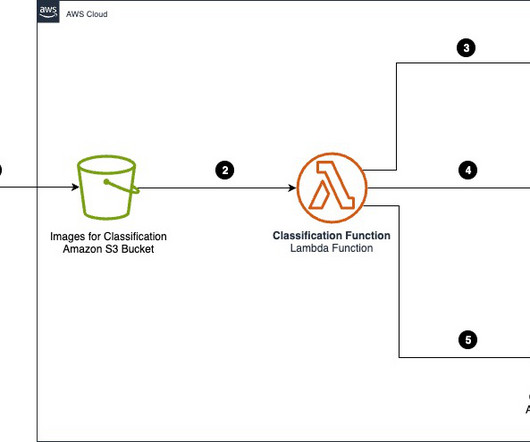
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
The way it categorizes incoming emails automatically has also helped me maintain that elusive “inbox zero” I could only dream about. It also supports 18 different writing styles categorized into four groups. For example, HARPA can quickly translate emails and documents without leaving the browser.
Once AI integrates with a data ecosystem, it can help automate the processing of complex assets, such as legal documents, contracts, call center interactions, etc. Moreover, Gen AI enables companies to collect and categorize data based on shared similarities, uncovering missing dependencies.
The Risks in Technicolor Researchers have painstakingly categorized these risks into neat little buckets. For example, researchers have documented Broken Hill tools that craft devious prompts to trick LLMs into bypassing their safeguards. Theres violence, hate speech, sexual content, and even criminal planning. The result?
Also, end-user queries are not always aligned semantically to useful information in provided documents, leading to vector search excluding key data points needed to build an accurate answer. Translating natural language into vectors reduces the richness of the information, potentially leading to less accurate answers.
During a live meeting, Avoma can create live bookmarks or tags that categorize the conversation (for example, marking when a specific topic or agenda item is being discussed). Supernormal Supernormal is an AI note-taking app that aims to automate your meeting documentation completely. Visit Avoma 6.
Companies in sectors like healthcare, finance, legal, retail, and manufacturing frequently handle large numbers of documents as part of their day-to-day operations. These documents often contain vital information that drives timely decision-making, essential for ensuring top-tier customer satisfaction, and reduced customer churn.
The Risks in Technicolor Researchers have painstakingly categorized these risks into neat little buckets. For example, researchers have documented Broken Hill tools that craft devious prompts to trick LLMs into bypassing their safeguards. Theres violence, hate speech, sexual content, and even criminal planning. The result?
On the other hand, for less critical applications, like preliminary content categorization of user-submitted audio files, you might set a lower threshold. You can then use this initial categorization to guide further processing or manual review where needed. . "status":
Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text. By accessing a vast corpus of documents during the generation process, RAG transforms basic language models into dynamic tools tailored for both business and consumer applications.
Data classification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. FMs are transforming the way you can solve traditionally complex document processing workloads.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests.
They can write this article better than me, make YouTube videos more popular than Mr. Beasts, do the work of an army of accountants, and review millions of discovery documents for a multibillion-dollar lawsuit, all in a matter of minutes. A task, notably, is not the same as a job or occupation. But is it possible to be more systematic?
Categorical Searches: Users can search within categories such as tweets, papers, or blogs for more targeted and effective searching. Features Coding Assistance: Firstly, Phind is optimized for code generation and trained on extended code datasets and documentation. This AI search engine is free for basic use, or you can pay $10.00
Building an On-Premise Document Intelligence Stack with Docling, Ollama, Phi-4 | ExtractThinker By Jlio Almeida This article details building an on-premise document intelligence solution using open-source tools. It concludes by emphasizing Smolagents efficiency and ease of use for developing sophisticated AI agents.
The results produced through OpenCLIP provide label probabilities that indicate how relevant a given image or text input is to specific product labels, aiding in the accurate categorization and recommendation of products. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. In sequential single interaction, retrievers identify relevant documents, which the language model then uses to predict the output.
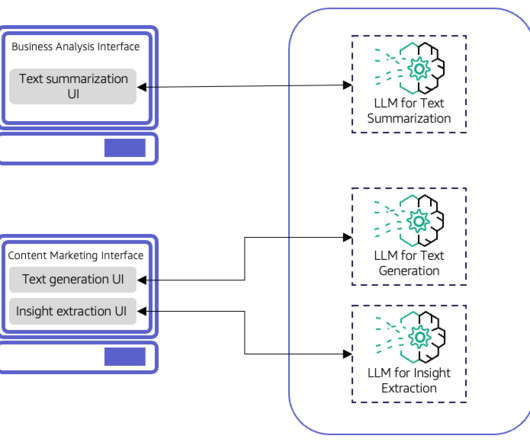
For instance, consider an AI-driven legal document analysis system designed for businesses of varying sizes, offering two primary subscription tiers: Basic and Pro. Meanwhile, the business analysis interface would focus on text summarization for analyzing various business documents. This is illustrated in the following figure.
Whether it's in eDiscovery, case building, or document review, Cecilia AI gives lawyers advanced tools to get to the facts of their case more quickly, which ultimately empowers them to provide better service to their clients. For our eDiscovery users, a key focus is on evidence investigation and document production.
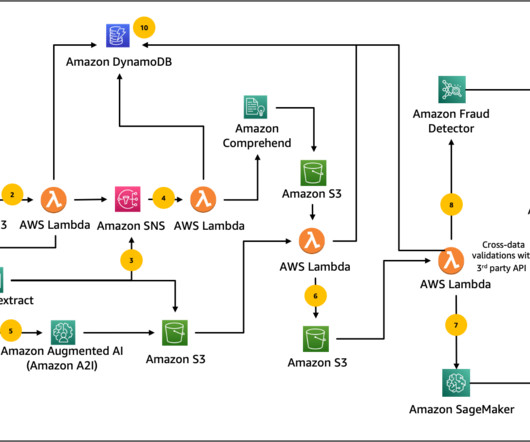
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Fraudsters range from blundering novices to near-perfect masters when creating fraudulent loan application documents.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content