This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
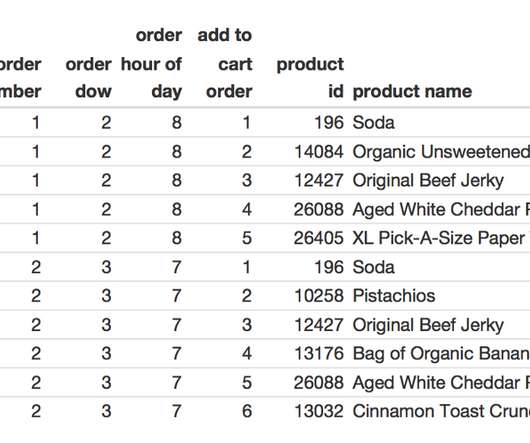
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
In this post, we explore why GraphRAG is more comprehensive and explainable than vector RAG alone, and how you can use this approach using AWS services and Lettria. Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect.
Summary: This blog explains the differences between one-way ANOVA vs two-way ANOVA, their definitions, assumptions, and applications. Step 3: Organise Your Data Structure your data with: One categorical independent variable (e.g., Step 3: Organise Your Data Set up your dataset with: Two categorical independent variables (e.g.,
In their paper, the researchers aim to propose a theory that explains how transformers work, providing a definite perspective on the difference between traditional feedforward neural networks and transformers. Despite their widespread usage, the theoretical foundations of transformers have yet to be fully explored.
The APIs standardized approach to tool definition and function calling provides consistent interaction patterns across different processing stages. When a document is uploaded through the Streamlit interface, Haiku analyzes the request and determines the sequence of tools needed by consulting the tool definitions in ToolConfig.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests.
By caching the system prompts and complex tool definitions, the time to process each step in the agentic flow can be reduced. n - Use clear and simple language, avoiding jargon unless it's necessary and explained." "nn4. Explains different logging configuration practices for AWS Network Firewall [1]n2. Specifically, it:nn1.
Through a runtime process that includes preprocessing and postprocessing steps, the agent categorizes the user’s input. It provides constructs to help developers build generative AI applications using pattern-based definitions for your infrastructure. Assist with partial information.
The AI Act takes a risk-based approach, meaning that it categorizes applications according to their potential risk to fundamental rights and safety. “The AI Act defines different rules and definitions for deployers, providers, importers. The European Union (EU) is the first major market to define new rules around AI.
Before explaining data sovereignty, let us understand a broader concept—digital sovereignty—first. It is important to consider data access policy definition and encryption which will enable users with permissions and rights as per the separation of duties. First, we must understand how data sovereignty came to be.
When it comes to implementing any ML model, the most difficult question asked is how do you explain it. Suppose, you are a data scientist working closely with stakeholders or customers, even explaining the model performance and feature selection of a Deep learning model is quite a task. How can we explain it in simple terms?
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process.
Text Classification : Categorizing text into predefined categories based on its content. It is used to automatically detect and categorize posts or comments into various groups such as ‘offensive’, ‘non-offensive’, ‘spam’, ‘promotional’, and others. It’s ‘trained’ on labeled data and then used to categorize new, unseen data.
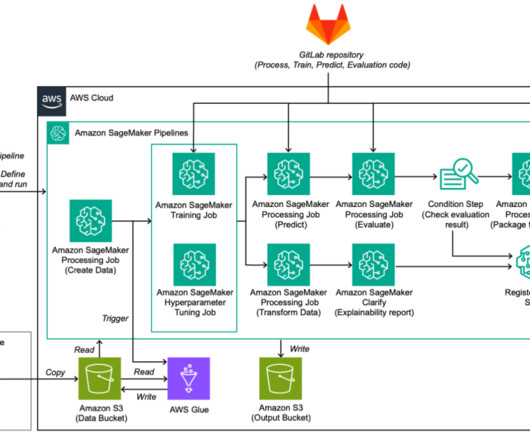
Essential ML capabilities such as hyperparameter tuning and model explainability were lacking on premises. In both cases, the evaluation and explainability report, if generated, are recorded in the model registry. Explain – SageMaker Clarify generates an explainability report. AWS_ACCOUNT] region = eu-central-1.
Definition, Types & How to Create Ever felt overwhelmed by data but unsure how to translate it into actionable insights? Cash Flow Statement Track the movement of cash through a company, categorized into operating, investing, and financing activities. Interpretation and Insights Explain the meaning behind the data and visuals.
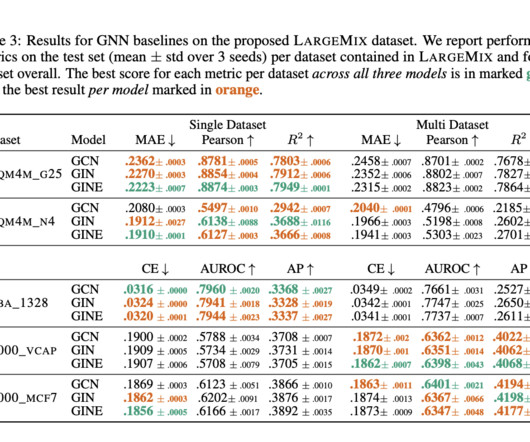
Since molecules’ and their conformers’ behavior depends on their environment and is primarily controlled by quantum physics, this is partially explained by the underspecification of molecules and their conformers as graphs. The “mixes” are designed to be anticipated concurrently while doing several tasks.
Definition says, machine learning is the ability of computers to learn without explicit programming. If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. How Machine Learning Works?
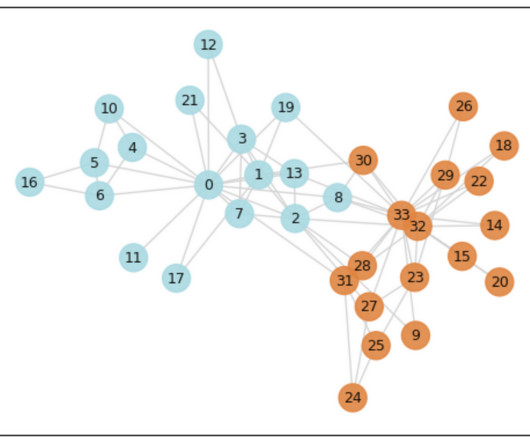
I will explain what these measures mean in plain english , so that you can at least grasp the intuition behind them. If our attribute is categorical (e.g., This definition produces an intuitive quantity that reaches to its maximum, i.e., r = 1, when interaction between nodes with the same attribute dominate the network.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. For more details, refer to the GitHub repo.
This article offers a measured exploration of AI agents, examining their definition, evolution, types, real-world applications, and technical architecture. Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches.
While we can only guess whether some powerful future AI will categorize us as unintelligent, what’s clear is that there is an explicit and concerning contempt for the human animal among prominent AI boosters. The scientific method has not figured out how to explain consciousness, as O’Gieblyn points out.
Photo by Guillaume Périgois on Unsplash EU AI Act: History and Timeline 2018 : EU Commission starts pilot project on ‘Explainable AI’. Paul Nemitz , a key contributor to GDPR and now actively involved in forming the EU AI Act, explains how unregulated AI can be a threat to Democracy. 2022 : Launch of first AI Regulatory Sandbox.
Instead, I will personally show you how to use each feature to see its effectiveness and explain everything in the clearest way possible. Flick allows you to easily manage and categorize your hashtag collections so you can always find the perfect hashtags for your posts. Flick is definitely worth the investment.
In 2014 I started working on spaCy , and here’s an excerpt of how I explained the motivation for the library: Computers don’t understand text. We want to aggregate it, link it, filter it, categorize it, generate it and correct it. That’s definitely new. We want to recommend people text based on other text they liked.
Grooming your backlog Let’s start with a quick working definition. You don’t need to label or categorize PBIs. If you’d like to learn how to groom or refine your backlog so you’re ready for your Sprint, just keep reading. You want to know these names and catagories so you can follow conversations about backlog.
We’ll walk through the data preparation process, explain the configuration of the time series forecasting model, detail the inference process, and highlight key aspects of the project. Throughout this blog post, we will be talking about AutoML to indicate SageMaker Autopilot APIs, as well as Amazon SageMaker Canvas AutoML capabilities.
This definition covers everything from the point of acquiring data to the point at which a data scientist exports a model for deployment. They normalize values, drop rows with missing data, and convert categorical columns into multiple boolean columns. What is AI data development?
This definition covers everything from the point of acquiring data to the point at which a data scientist exports a model for deployment. They normalize values, drop rows with missing data, and convert categorical columns into multiple boolean columns. What is AI data development?
This definition covers everything from the point of acquiring data to the point at which a data scientist exports a model for deployment. They normalize values, drop rows with missing data, and convert categorical columns into multiple boolean columns. What is AI data development?
We dig into a real-world dataset to search for stories worth telling and explain how common practices in data visualisation sometimes fail to convey the right message. Numbers are, by definition, objective. A model can only be perfect if it explains the whole complexity of our world, which is obviously impossible.
If you haven’t coded an image classification network before, the section is definitely for you! The Adam optimizer is used with the initial learning rate specified in the config file, and the loss function used is sparse categorical cross-entropy. the image classification network). So let’s get straight into the code.
Figure 1: Types of regression (own graphic) Definition of Simple Linear Regression The dependent variable is continuous. The independent, predictor variable can be either continuous or categorical. There are various types of regressions used in data science and machine learning. This assumption does not always hold.
The definition to calculate mAP can even vary from one object detection challenge to another (when we say “object detection challenge,” we are referring to competitions such as COCO, PASCAL VOC, etc.). All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms.
Explaining Complex Concepts: Data Visualization simplifies the communication of complex concepts and analytical methodologies. This can include explanations of data sources, definitions of terms, or notes on significant observations.
Key steps involve problem definition, data preparation, and algorithm selection. After cleaning, the data may need to be preprocessed, which includes scaling numerical features, encoding categorical variables, and transforming text or images into formats suitable for the model. Data quality significantly impacts model performance.
Explainability : Making sure they can explain their experiment results. This, of course, is not true in all situations, but in circumstances where they need to understand how and why your model makes predictions, “explainability” becomes crucial. Legal compliance is another reason why explainability is essential.
In addition, there are a few more variables in our data set that, although they have numerical values, are actually categorical variables according to the information they contain. For example, the postcode and Row ID columns are represented numerically, even though they actually have a categorical attribute.
If you are interested in getting a deeper understanding of the math and theory behind XGBoost, then you should definitely visit Here. Conclusion This article explains the basic theory of Decision Trees, Gradient Boosted Trees, and Xgboost. It was developed by Tianqi Chen, a data scientist and software engineer, during his Ph.D.
The following explains the two methods in detail. Precision vs. Recall Trade-off From the definition of both precision and recall, we can see an inherent trade-off between the two metrics. The threshold is the minimum probability for categorizing a prediction as positive. For a cat classification model, a threshold of 0.5
DOE: stands for the design of experiments, which represents the task design aiming to describe and explain information variation under hypothesized conditions to reflect variables. Define and explain selection bias? Explain it’s working. Explain Neural Network Fundamentals. Define confounding variables.
In this post, I’ll explain how to solve text-pair tasks with deep learning, using both new and established tips and technologies. The definition is block-scoped, so you can always read what the operators are being aliased to. This data set is large, real, and relevant — a rare combination.
The AI community categorizes N-shot approaches into few, one, and zero-shot learning. Auxiliary information can include text descriptions, summaries, definitions, etc., As the article explains, the N-shot learning paradigms address these data challenges. Let’s discuss each in more detail.
In this post, we highlight some of the things we’re especially pleased with, and explain some of the most challenging parts of preparing this big release. It helps most for text categorization and parsing, but is less effective for named entity recognition. Version 2.1 Even more recently, Li et al. You could have just walked around it.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content