This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For a multiclass classification problem such as support case root cause categorization, this challenge compounds many fold.
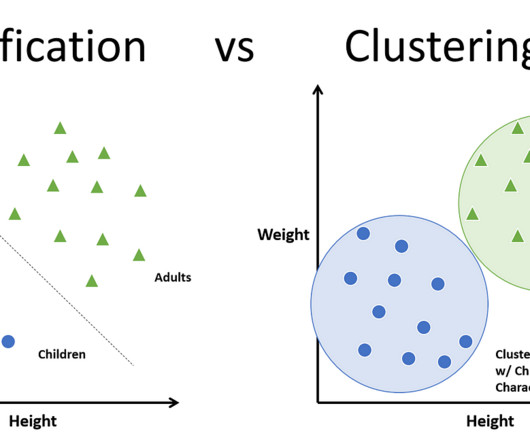
Definitely not. This is where the organization part comes in— by categorizing the brands as a whole or taking a more […] The post Classification vs. Clustering- Which One is Right for Your Data? Introduction Imagine walking into a shopping mall with hundreds of brands and products, all jumbled up and randomly placed in the shops.
This is exactly what happens when you try to feed categorical data into a machine-learning model. Image generated by Dall-E In this hands-on tutorial, we’ll unravel the mystery of encoding categorical data so your models can process it with ease. Before we start transforming data, let’s get our definitions straight.
2) Inductive/ Inferential Statisticsformal definition: Inferential statistics involves drawing conclusions or making inferences about a population based on data collected from a sample of that population.In-short Mean Definition: The average value. Median Definition: The middle value when data is sorted. Ordinal data (e.g.,
Real-time analysis: AI tools can instantly analyze and categorize content, allowing brands to respond quickly to emerging trends, crises, or opportunities. Beyond identifying mentions, it should be able to reliably categorize information and determine the sentiment. Real-time analysis: Timing is everything.
In this collaboration, the Generative AI Innovation Center team created an accurate and cost-efficient generative AIbased solution using batch inference in Amazon Bedrock , helping GoDaddy improve their existing product categorization system. Moreover, employing an LLM for individual product categorization proved to be a costly endeavor.
The Three Pillars of the Product Alchemist To understand the evolution of a product manager, we can categorize their responsibilities into three distinct pillars: Ideation, Execution, and Alignment and Leading with Influence. This affects everything from ideation and execution to alignment with stakeholders and leading with influence.
Lettrias in-house team manually assessed the answers with a detailed evaluation grid, categorizing results as correct, partially correct (acceptable or not), or incorrect. At query time, user intent is turned into an efficient graph query based on domain definition to retrieve the relevant entities and relationship.
The APIs standardized approach to tool definition and function calling provides consistent interaction patterns across different processing stages. When a document is uploaded through the Streamlit interface, Haiku analyzes the request and determines the sequence of tools needed by consulting the tool definitions in ToolConfig.
Real-time object detection in smart cities for pedestrian detection with different types of objects One-stage vs. two-stage deep learning object detectors As you can see in the list above, state-of-the-art object detection methods can be categorized into two main types: One-stage vs. two-stage object detectors.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests.
In their paper, the researchers aim to propose a theory that explains how transformers work, providing a definite perspective on the difference between traditional feedforward neural networks and transformers. Despite their widespread usage, the theoretical foundations of transformers have yet to be fully explored.
Definition and Types of Hallucinations Hallucinations in LLMs are typically categorized into two main types: factuality hallucination and faithfulness hallucination. These causes can be broadly categorized into three parts: 1.
There is an increasing need for a formal framework to categorize and comprehend the behavior of AGI models and their precursors as the capabilities of machine learning models advance. The team has analyzed previous definitions of AGI to create this framework, distilling six ideas they thought were necessary for a practical AGI ontology.
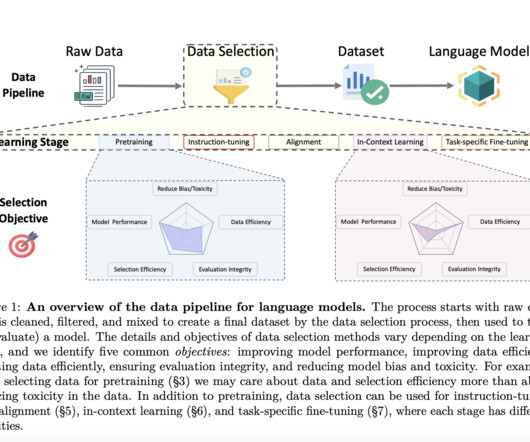
By categorizing these methods and creating a taxonomy, they aim to offer a comprehensive resource on data selection practices for language model training. They organized the survey as follows: The taxonomy of data selection includes basic definitions of terms related to the dataset, such as data point, dataset, and dataset distribution.
We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation. One of the most critical aspects of fine-tuning is selecting the right hyperparameters, particularly learning rate multiplier and batch size (see the appendix in this post for definitions).
Tableau Data Types: Definition, Usage, and Examples Tableau has become a game-changer in the world of data visualization. Is it a number used for calculations, a text description for categorization, or a date for tracking trends? today. The post Tableau Data Types: Definition, Usage, and Examples appeared first on Pickl.AI.
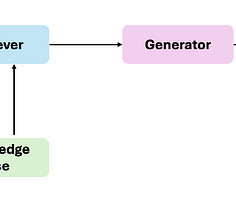
Understanding RAG Definition and Core Concepts RAG is an AI framework that enhances LLMs by integrating an external knowledge retrieval component. In this article, Ill break down how RAG works, its key components, and why it remains essential as we move toward truly intelligent, real-time, and context-aware AI systems.
Through a runtime process that includes preprocessing and postprocessing steps, the agent categorizes the user’s input. It provides constructs to help developers build generative AI applications using pattern-based definitions for your infrastructure.
It is important to consider data access policy definition and encryption which will enable users with permissions and rights as per the separation of duties. Data classification and categorization : Data needs to be handled according to its importance as all data are not created equally.
Summary: This blog explains the differences between one-way ANOVA vs two-way ANOVA, their definitions, assumptions, and applications. Step 3: Organise Your Data Structure your data with: One categorical independent variable (e.g., Step 3: Organise Your Data Set up your dataset with: Two categorical independent variables (e.g.,
This distinction is essential for a variety of uses, such as building playlists for particular objectives, concentration, or relaxation, and even as a first step in language categorization for singing, which is crucial in marketplaces with numerous languages. Check out the Paper.
Definition, Types & How to Create Ever felt overwhelmed by data but unsure how to translate it into actionable insights? Cash Flow Statement Track the movement of cash through a company, categorized into operating, investing, and financing activities. Definition, Types & How to Create appeared first on Pickl.AI.
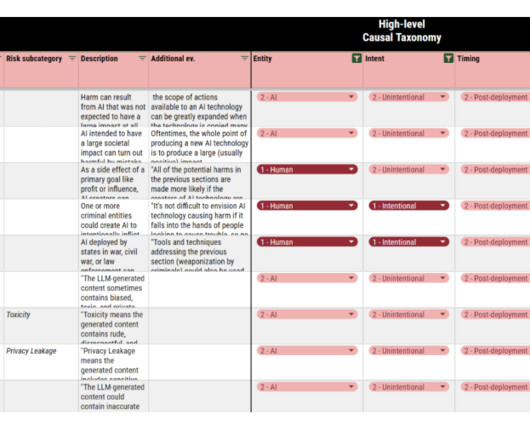
Although substantial research has identified and categorized these risks, a unified framework is needed to be consistent with terminology and clarity. Two taxonomies were developed: the Causal Taxonomy, categorizing risks by responsible entity, intent, and timing, and the Domain Taxonomy, classifying risks into specific domains.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. You are only allowed to output text in JSON format.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. The definition of our end-to-end orchestration is detailed in the GitHub repo. We provide a prompt example for feedback categorization.
The team has shared how Semantic-SAM tackles the problem of semantic awareness by using a decoupled categorization strategy for parts and objects. This strategy guarantees that the model can handle data from the SAM dataset, which lacks some categorization labels, as well as data from general segmentation data. A stunning 2.3
Rather, the definition is constantly evolving in the AI-detection scene, where (currently, at least) excessively clear language or the use of certain words (such as ‘ Delve' ) can cause an association with AI-generated text.
The AI Act takes a risk-based approach, meaning that it categorizes applications according to their potential risk to fundamental rights and safety. “The AI Act defines different rules and definitions for deployers, providers, importers. The European Union (EU) is the first major market to define new rules around AI.
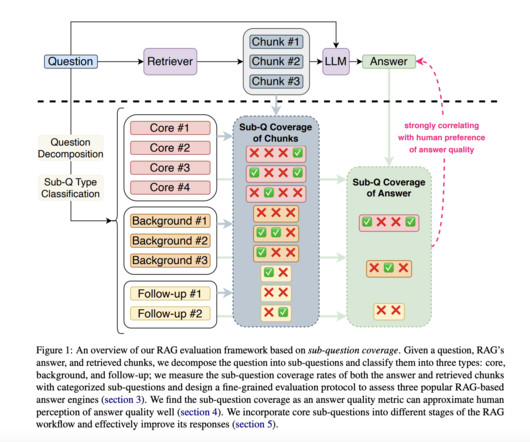
Evaluating the effectiveness of RAG systems presents unique challenges, as they often need to answer non-factoid questions that need more than a single definitive response. Instead of general relevance scores, the researchers propose decomposing a question into specific sub-questions, categorized as core, background, or follow-up.
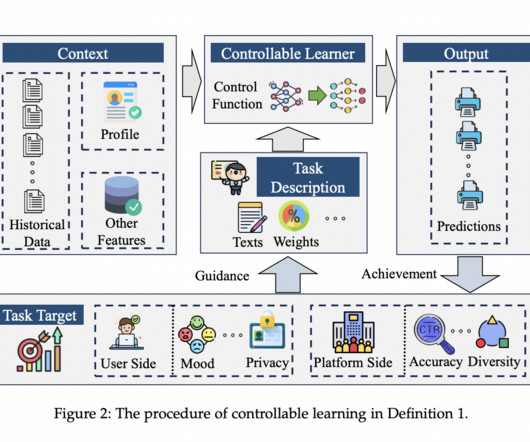
Definition and Importance of Controllable Learning Controllable Learning is formally defined as the ability of a learning system to adapt to various task requirements without requiring retraining. retrieval objectives, user behaviors, environmental adaptation), how control is implemented (e.g.,
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. They can search within specific categories to narrow down results.
Categorizing expenses This is the process of organizing a company’s spending into specific categories, such as office supplies, IT hardware or marketing services. Each spending, if categorized properly, can be recorded in the books under the right header and then reported.
These variables often involve complex sequences of events, combinations of occurrences and non-occurrences, as well as detailed numeric calculations or categorizations that accurately reflect the diverse nature of patient experiences and medical histories.
In supervised image classification and self-supervised learning, there’s a trend towards using richer pointwise Bernoulli conditionals parameterized by sigmoid functions, moving away from output conditional categorical distributions typically parameterized by softmax.
Existing approaches to 3D generation can be broadly categorized into auto-regressive models and score-distillation methods. The text-based OBJ file format encodes 3D meshes in plain text, consisting of vertex coordinates and face definitions.
This set of 3 numbers is a 3-dimensional representation or embedding for the visual quality (based on our definition) of the images. These are used when working with categorical values such as text. They are essentially a lookup table that converts a categorical value to a dense representation or embedding.
The APA Dictionary of Psychology provides a comprehensive definition of social norms as socially determined standards that indicate typical and appropriate behaviors within a specific social context. By leveraging this labeled data, they trained the models to automatically identify social norms and categorize them into top-level groups.
They provide three comprehensive and rigorously maintained multi-label datasets, the largest currently, with approximately 100 million molecules and over 3000 activities with sparse definitions. They comprise jobs at the graph level and node level, as well as quantum, chemical, and biological aspects, categorical and continuous data points.
The identification of regularities in data can then be used to make predictions, categorize information, and improve decision-making processes. While explorative pattern recognition aims to identify data patterns in general, descriptive pattern recognition starts by categorizing the detected patterns.
JSONs inherently structured format allows for clear and organized representation of complex data such as table schemas, column definitions, synonyms, and sample queries. To increase the accuracy, we categorized the tables in four different types based on the schema and created four JSON files to store different tables.
In this presentation, I’ll demonstrate how the BioGPT generative language model, along with some fine-tuning, can be used for tasks like extracting biomedical relationships, addressing queries, categorizing documents, and creating definitions for biomedical terms.
They identify 14 failure modes, categorized into system design flaws, inter-agent misalignment, and task verification issues, forming the Multi-Agent System Failure Taxonomy (MASFT). The study explores failure patterns in MAS and categorizes them into a structured taxonomy.
Definition says, machine learning is the ability of computers to learn without explicit programming. If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. How Machine Learning Works?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content