This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview Presenting 11 data science videos that will enhance and expand your current skillset We have categorized these videos into three fields – Natural. The post 11 Superb Data Science Videos Every DataScientist Must Watch appeared first on Analytics Vidhya.
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categoricaldata effectively. But what if we could predict a student’s engagement level before they begin? What is CatBoost?
These are typical data science interview questions every aspiring datascientist. What is One-Hot Encoding? When should you use One-Hot Encoding over Label Encoding? The post One-Hot Encoding vs. Label Encoding using Scikit-Learn appeared first on Analytics Vidhya.
Likewise, businesses must improve data literacy across the organization. Companies need to make changes at every level, not just with technical people, like engineers or datascientists. Start with a data maturity assessment, evaluating the data security competencies across different roles.
It achieves this through various functions that categorize statements based on the context pools LLMs are trained on, such as Wikipedia, Common Crawl, and Books3. Unpacking the veryLLM Toolkit At its core, the veryLLM toolkit allows for a deeper comprehension of each LLM-generated sentence.
For instance, if datascientists were building a model for tornado forecasting, the input variables might include date, location, temperature, wind flow patterns and more, and the output would be the actual tornado activity recorded for those days. the target or outcome variable is known). temperature, salary).
The LightAutoML framework is deployed across various applications, and the results demonstrated superior performance, comparable to the level of datascientists, even while building high-quality machine learning models. The LightAutoML framework attempts to make the following contributions.
Batch inference in Amazon Bedrock efficiently processes large volumes of data using foundation models (FMs) when real-time results aren’t necessary. Ishan Singh is a Generative AI DataScientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products.
As datascientists and machine learning engineers, we spend the majority of our time working with data. In machine learning, the path from raw data to a well-tuned model is paved with preprocessing techniques that set the way for success. Join thousands of data leaders on the AI newsletter.
It creates a trove of historical data that can be retrieved, analyzed, and reported to provide insight or predictive analysis into an organization’s performance and operations. Data warehousing solutions drive business efficiency, build future analysis and predictions, enhance productivity, and improve business success.
A cheat sheet for DataScientists is a concise reference guide, summarizing key concepts, formulas, and best practices in Data Analysis, statistics, and Machine Learning. It serves as a handy quick-reference tool to assist data professionals in their work, aiding in data interpretation, modeling , and decision-making processes.
Many graphical models are designed to work exclusively with continuous or categorical variables, limiting their applicability to data that spans different types. This means they can handle various input data types, including categorical, continuous, images, and embeddings.
But how can machine learning practitioners improve the reliability of their models, particularly when dealing with tabular data? CatBoost : Specialized in handling categorical variables efficiently. LightGBM : Optimized for speed and scalability, making it useful for large datasets. seasons, time ofday).
Instead of spending time and effort on training a model from scratch, datascientists can use pretrained foundation models as starting points to create or customize generative AI models for a specific use case. They can also perform self-supervised learning to generalize and apply their knowledge to new tasks.
Training Sessions Bayesian Analysis of Survey Data: Practical Modeling withPyMC Allen Downey, PhD, Principal DataScientist at PyMCLabs Alexander Fengler, Postdoctoral Researcher at Brown University Bayesian methods offer a flexible and powerful approach to regression modeling, and PyMC is the go-to library for Bayesian inference in Python.
Users can review different types of events such as security, connectivity, system, and management, each categorized by specific criteria like threat protection, LAN monitoring, and firmware updates. Daniel Pienica is a DataScientist at Cato Networks with a strong passion for large language models (LLMs) and machine learning (ML).
DataScientists are highly in demand across different industries for making use of the large volumes of data for analysisng and interpretation and enabling effective decision making. One of the most effective programming languages used by DataScientists is R, that helps them to conduct data analysis and make future predictions.
Learning Path to Building LLM-Based Solutions — For Practitioner DataScientists As everyone would agree, the advent of LLM has transformed the technology industry, and technocrats have had a huge surge of interest in learning about LLMs. link] Again, datascientists have limited scope here.
Intro to Deep Learning with PyTorch and TensorFlow Dr. Jon Krohn | Chief DataScientist | Nebula.io In recent years, Deep Learning has become ubiquitous across a wide range of data-driven applications.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
To make sure that words are properly segmented before feeding them into NLP models, cleaning text data includes adding, deleting, or changing these symbols. Neglecting this preliminary stage may result in inaccurate tokenization, impacting subsequent tasks such as sentiment analysis, language modeling, or text categorization.
Introduction In today’s data-driven world, the ability to interact with databases is no longer a niche skillit’s a fundamental requirement for developers, analysts, datascientists, and even marketers. SQL Functions SQL provides built-in functions to perform operations on data. Often used without an ON clause.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for datascientists to select and clean data, create features, and automate data preparation in ML workflows without writing any code.
Datascientists and engineers frequently collaborate on machine learning ML tasks, making incremental improvements, iteratively refining ML pipelines, and checking the model’s generalizability and robustness. Because it can handle numeric, textual, and categoricaldata, DATALORE normally beats EDV in every category.
Information retrieval The first step in the text-mining workflow is information retrieval, which requires datascientists to gather relevant textual data from various sources (e.g., The data collection process should be tailored to the specific objectives of the analysis. positive, negative or neutral).
Once you collect the data from any source, we need to ensure that the data is qualitative. As a datascientist, we will explore the entire data set to understand each characteristic and identify any patterns existing if any in it. This process is called Exploratory Data Analysis(EDA).
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Datascientists often spend up to 80% of their time on data engineering in data science projects.
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. They can search within specific categories to narrow down results.
Generative AI auto-summarization creates summaries that employees can easily refer to and use in their conversations to provide product, service or recommendations (and it can also categorize and track trends). In another instance, Lloyds Banking Group was struggling to meet customer needs with their existing web and mobile application.
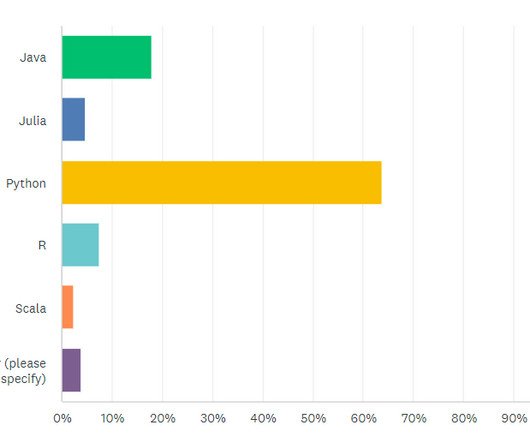
For the last part of the first blog in this series, we asked about what areas of the field datascientists are interested in as part of the machine learning survey. What areas of machine learning are you interested in? Stay tuned for that article soon!
Data Visualization: A Practical Introduction This book covers creating compelling visualizations using R programming language, specifically the ggplot2 library. Data Visualisation This book has everything students and scholars need to understand and create effective data visualizations.
Consequently, there is a pressing need for methods to exploit data’s relational nature without oversimplification fully. Existing methods for managing relational data largely rely on manual feature engineering. In this approach, datascientists painstakingly transform raw data into formats suitable for ML models.
To create NLP models, developers need not only algorithms, but bucketloads of quality training data that is accurately “labelled,” a technique that categorizes raw data to enable machines to understand and learn from it. million ($2.9 million ($2.9
Additionally, they can use NLP to categorize messages into words or phrases and rank which sections of the post were usually favorable. Datascientists engage with social groups, but they provide their services voluntarily. One option for businesses is to hire independent datascientists for short-term initiatives.
However, higher education institutions often lack ML professionals and datascientists. Amazon SageMaker Canvas is a low-code/no-code ML service that enables business analysts to perform data preparation and transformation, build ML models, and deploy these models into a governed workflow. International (CC BY 4.0)
link] The process can be categorized into three agents: Execution Agent : The heart of the system, this agent leverages OpenAI’s API for task processing. Deepnote AI Copilot Deepnote AI Copilot reshapes the dynamics of data exploration in notebooks. At its core, Deepnote AI aims to augment the workflow of datascientists.
In general, machine learning engineers and datascientists use the term “last mile” to describe the process of preparing an AI solution for broad and universal use. For example, we worked with a client to build a topic model to categorize all channels of customer feedback. Categorization models typically have some error rate.
MonkeyLearn’s use of machine learning to streamline business processes and analyze text eliminates the need for countless man-hours of data entry. The ability to automatically pull data from incoming requests is a popular feature in MonkeyLearn. In addition to datascientists and analysts, KNIME is also useful for engineers.
You don’t have to identify the people,” says datascientist Jonathan Weber of the University of Haute-Alsace , in Mulhouse, France, and coauthor of a review of video crowd analysis. Whether this is true is unclear; the fast evolution of the technologies involved makes it a difficult question to answer.
By the end, you’ll be equipped to design and manage complex data solutions on the Azure platform. Data Engineering This course teaches data engineering for datascientists, covering ETL, NLP, and machine learning pipelines using tools like Scikit-Learn.
Industrial datascientists need to run existing log analysis algorithms on their log data and select the best algorithm and configuration combination as their log analysis solution. It has four components: log parser, log vectorizer, categorical encoder, and feature extractor.
Machine learning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. Datascientists need to understand the business problem and the project scope to assess feasibility, set expectations, define metrics, and design project blueprints. debt to income ratio).
Whether you’re a seasoned datascientist or just starting your journey in AI, understanding how Softmax Regression works is crucial for building robust models that can accurately predict outcomes across multiple categories. It handles scenarios where data points can belong to more than two classes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content