This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Akeneo's Supplier Data Manager (SDM) is designed to streamline the collection, management, and enrichment of supplier-provided product information and assets by offering a user-friendly portal where suppliers can upload product data and media files, which are then automatically mapped to the retailer's and/or distributors data structure.
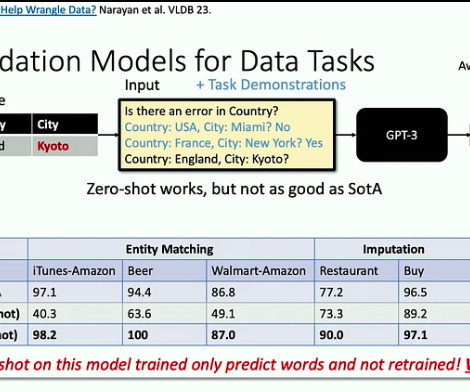
The emergence of large language models (LLMs) such as Llama, PaLM, and GPT-4 has revolutionized naturallanguageprocessing (NLP), significantly advancing text understanding and generation. These causes can be broadly categorized into three parts: 1.
Developing and refining Large Language Models (LLMs) has become a focal point of cutting-edge research in the rapidly evolving field of artificial intelligence, particularly in naturallanguageprocessing. A significant innovation in this domain is creating a specialized tool to refine the dataset compilation process.
Defining AI Agents At its simplest, an AI agent is an autonomous software entity capable of perceiving its surroundings, processingdata, and taking action to achieve specified goals. Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches.
They serve as a core building block in many naturallanguageprocessing (NLP) applications today, including information retrieval, question answering, semantic search and more. With further research intoprompt engineering and synthetic dataquality, this methodology could greatly advance multilingual text embeddings.
Amazon Comprehend is a natural-languageprocessing (NLP) service that uses machine learning to uncover valuable insights and connections in text. Knowledge management – Categorizing documents in a systematic way helps to organize an organization’s knowledge base. This allows for better monitoring and auditing.
Challenges of building custom LLMs Building custom Large Language Models (LLMs) presents an array of challenges to organizations that can be broadly categorized under data, technical, ethical, and resource-related issues. Ensuring dataquality during collection is also important.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. It isn't easy to collect a good amount of qualitydata. How Machine Learning Works?
In this article, we’ll talk about what named entity recognition is and why it holds such an integral position in the world of naturallanguageprocessing. Introduction about NER Named entity recognition (NER) is a fundamental aspect of naturallanguageprocessing (NLP). Disadvantages 1.Data
Pixability is a data and technology company that allows advertisers to quickly pinpoint the right content and audience on YouTube. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos. Using AI to help customers optimize ad spending and maximize their reach on YouTube.
But what if there was a technique to quickly and accurately solve this language puzzle? Enter NaturalLanguageProcessing (NLP) and its transformational power. But what if there was a way to unravel this language puzzle swiftly and accurately? However, in this sea of complexity, NLP offers a ray of hope.
As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional naturallanguageprocessing (NLP)-based analytics.
Deep learning is a branch of machine learning that makes use of neural networks with numerous layers to discover intricate data patterns. Deep learning models use artificial neural networks to learn from data. NaturalLanguageProcessing (NLP) : Question answering, language modeling, sentiment analysis, machine translation, and more.
The high-level steps involved in the solution are as follows: Use AWS Step Functions to orchestrate the health data anonymization pipeline. Use Amazon Athena queries for the following: Extract non-sensitive structured data from Amazon HealthLake. Perform one-hot encoding with Amazon SageMaker Data Wrangler.
AlexNet was created to categorize photos in the ImageNet dataset, which contains approximately 1 million images divided into 1,000 categories. NaturalLanguageProcessing : CNNs have been implemented for sentiment analysis and text categorization in naturallanguageprocessing jobs.
NaturalLanguageProcessing (NLP) models rely heavily on bias to function effectively. In fact, a certain degree of bias is essential for these models to make accurate predictions and decisions based on patterns within the data they have been trained on. harness.generate().run().report()
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Assigning complaints to staff.
The article also addresses challenges like dataquality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, data preparation, and algorithm selection. Dataquality significantly impacts model performance.
The Many Faces of Responsible AI In her presentation , Lora Aroyo, a Research Scientist at Google Research, highlighted a key limitation in traditional machine learning approaches: their reliance on binary categorizations of data as positive or negative examples. In safety evaluation tasks, experts disagree on 40% of examples.
The RedPajama project aims to create a set of leading, fully open-source models (LLMs) for naturallanguageprocessing, including not just open model weights, but also open training data. Background: what is RedPajama? For these experiments, we use the RedPajama family of LLMs.
The RedPajama project aims to create a set of leading, fully open-source models (LLMs) for naturallanguageprocessing, including not just open model weights, but also open training data. Background: what is RedPajama? For these experiments, we use the RedPajama family of LLMs.
The RedPajama project aims to create a set of leading, fully open-source models (LLMs) for naturallanguageprocessing, including not just open model weights, but also open training data. Background: what is RedPajama? For these experiments, we use the RedPajama family of LLMs.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
The RedPajama project aims to create a set of leading, fully open-source models (LLMs) for naturallanguageprocessing, including not just open model weights, but also open training data. Background: what is RedPajama? For these experiments, we use the RedPajama family of LLMs.
They achieve this by asking the user for input, seeking confirmation, and collecting essential data for back-end business systems, boosting dataquality and avoiding mistakes. IT helpdesk chatbots with AI capabilities may use conversation history and other factors to detect the employee’s purpose and categorize them accordingly.
These networks can learn from large volumes of data and are particularly effective in handling tasks such as image recognition and naturallanguageprocessing. Key Deep Learning models include: Convolutional Neural Networks (CNNs) CNNs are designed to process structured grid data, such as images.
We can categorize the types of AI for the blind and their functions. Object Recognition The process of detecting objects is necessary for daily activities. However, those models still hold drawbacks, things like font, language, and format are big challenges for OCR models. A conceptual framework for most assistive tools.
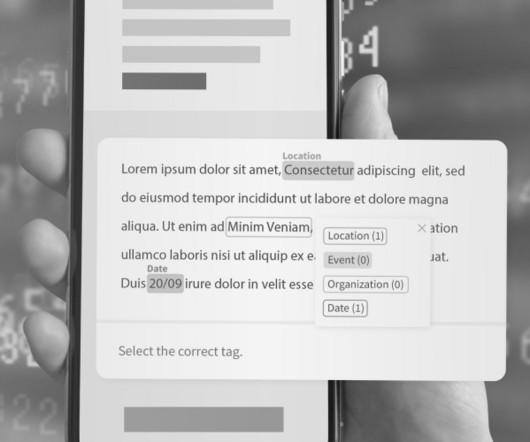
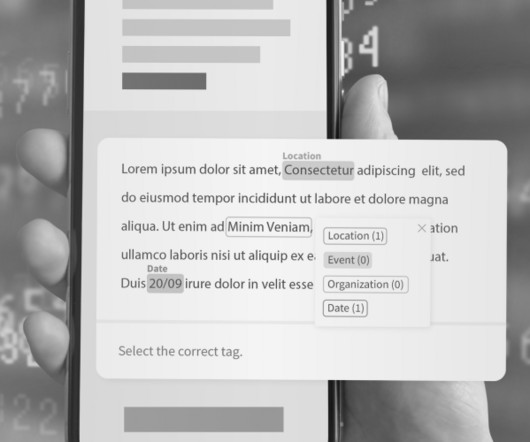
Named Entity Recognition (NER) is a naturallanguageprocessing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. What is Named Entity Recognition (NER)?
Named Entity Recognition (NER) is a naturallanguageprocessing (NLP) subtask that involves automatically identifying and categorizing named entities mentioned in a text, such as people, organizations, locations, dates, and other proper nouns. What is Named Entity Recognition (NER)?
They’re the perfect fit for: Image, video, text, data & lidar annotation Audio transcription Sentiment analysis Content moderation Product categorization Image segmentation iMerit also specializes in extraction and enrichment for Computer Vision , NLP , data labeling, and other technologies.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







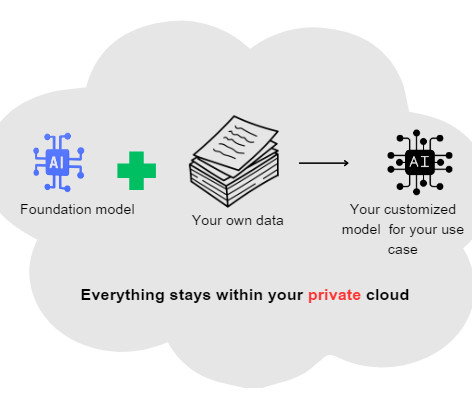







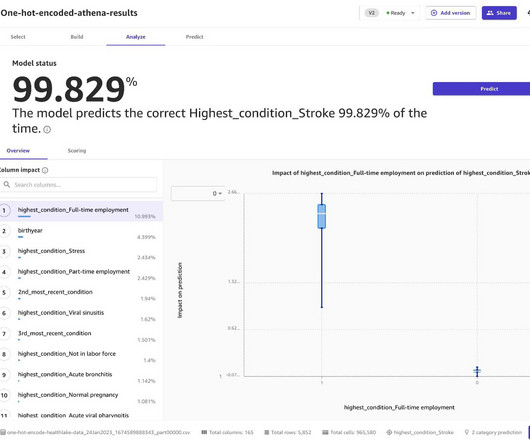
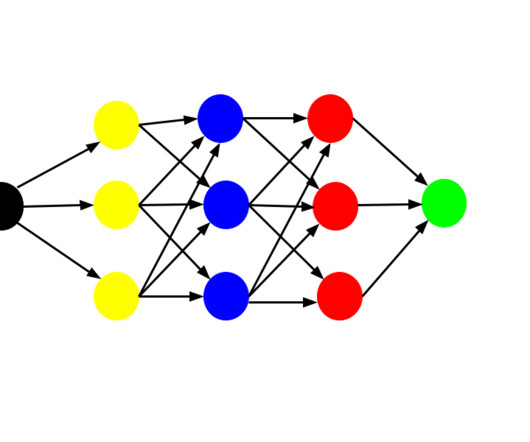

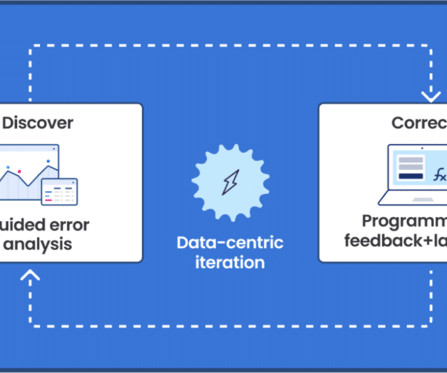
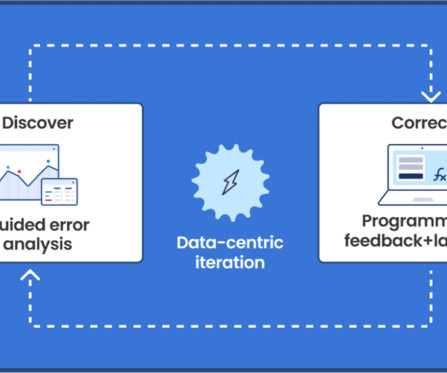
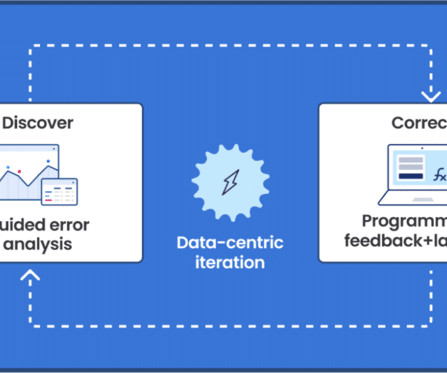












Let's personalize your content