This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categoricaldata effectively. But what if we could predict a student’s engagement level before they begin?
In just about any organization, the state of information quality is at the same low level – Olson, DataQualityData is everywhere! As data scientists and machinelearning engineers, we spend the majority of our time working with data. Join thousands of data leaders on the AI newsletter.
Summary: Dataquality is a fundamental aspect of MachineLearning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in MachineLearning?
Download the MachineLearning Project Checklist. Planning MachineLearning Projects. Machinelearning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. More organizations are investing in machinelearning than ever before.
Recently, we posted the first article recapping our recent machinelearning survey. There, we talked about some of the results, such as what programming languages machinelearning practitioners use, what frameworks they use, and what areas of the field they’re interested in. As the chart shows, two major themes emerged.
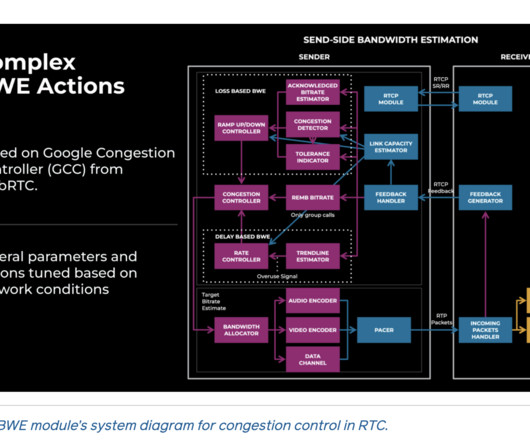
Researchers from Meta developed a machinelearning (ML)-based approach to address the challenges of optimizing bandwidth estimation (BWE) and congestion control for real-time communication (RTC) across Meta’s family of apps.
Beginner’s Guide to ML-001: Introducing the Wonderful World of MachineLearning: An Introduction Everyone is using mobile or web applications which are based on one or other machinelearning algorithms. You might be using machinelearning algorithms from everything you see on OTT or everything you shop online.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machinelearning (ML) solutions without writing code. Analyze data using generative AI. Prepare data for machinelearning.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights. A new data flow is created on the Data Wrangler console. Choose Create.
Some components are categorized in groups based on the type of functionality they exhibit. The AWS managed offering ( SageMaker Ground Truth Plus ) designs and customizes an end-to-end workflow and provides a skilled AWS managed team that is trained on specific tasks and meets your dataquality, security, and compliance requirements.
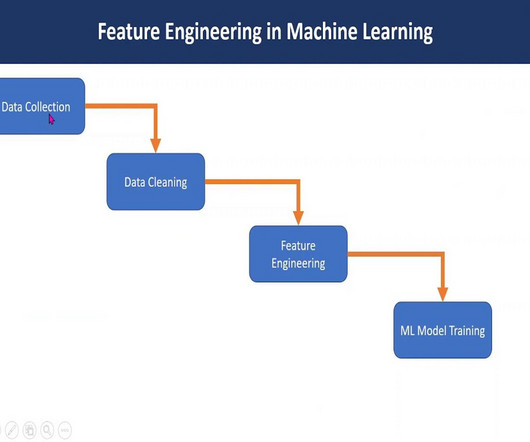
The ability to quickly build and deploy machinelearning (ML) models is becoming increasingly important in today’s data-driven world. From data collection and cleaning to feature engineering, model building, tuning, and deployment, ML projects often take months for developers to complete.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
By adopting technologies like artificial intelligence (AI) and machinelearning (ML), companies can give a boost to their customer segmentation efforts. In those cases, a traditional approach run by humans can work better, especially if you mainly have qualitative data. Here’s a guide to help you accomplish that.
In the early days of online shopping, ecommerce brands were categorized as online stores or “multichannel” businesses operating both ecommerce sites and brick-and-mortar locations. To ensure the success of this approach, it is crucial to maintain a strong focus on dataquality, security and ethical considerations.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machinelearning (ML) models across your AWS accounts. Model risk : Risk categorization of the model version. Madhubalasri B.
Feature engineering in machinelearning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through Exploratory Data Analysis , imputation, and outlier handling, robust models are crafted. Hence, it is important to discuss the impact of feature engineering in MachineLearning.
Our experiments demonstrate that careful attention to dataquality, hyperparameter optimization, and best practices in the fine-tuning process can yield substantial gains over base models. She innovates and applies machinelearning to help AWS customers speed up their AI and cloud adoption.
.” For example, synthetic data represents a promising way to address the data crisis. This data is created algorithmically to mimic the characteristics of real-world data and can serve as an alternative or supplement to it. In this context, dataquality often outweighs quantity.
Summary: The blog provides a comprehensive overview of MachineLearning Models, emphasising their significance in modern technology. It covers types of MachineLearning, key concepts, and essential steps for building effective models. The global MachineLearning market was valued at USD 35.80
Amazon Comprehend is a natural-language processing (NLP) service that uses machinelearning to uncover valuable insights and connections in text. Knowledge management – Categorizing documents in a systematic way helps to organize an organization’s knowledge base. They can search within specific categories to narrow down results.
Summary: The UCI MachineLearning Repository, established in 1987, is a crucial resource for MachineLearning practitioners. It supports various learning tasks, including classification and regression, and is organised by type and domain, facilitating easy access for users worldwide.
Artificial intelligence (AI) and machinelearning (ML) have rapidly become key drivers of business transformation. In general, machinelearning engineers and data scientists use the term “last mile” to describe the process of preparing an AI solution for broad and universal use. Here are just a few: Dataquality.
Summary: The blog discusses essential skills for MachineLearning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding MachineLearning algorithms and effective data handling are also critical for success in the field. billion by 2031, growing at a CAGR of 34.20%.
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machinelearning (ML), retail, and data and analytics. Add another step and choose Encode categorical.
Defining AI Agents At its simplest, an AI agent is an autonomous software entity capable of perceiving its surroundings, processing data, and taking action to achieve specified goals. Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches.
Data engineering is crucial in today’s digital landscape as organizations increasingly rely on data-driven insights for decision-making. Learningdata engineering ensures proficiency in designing robust data pipelines, optimizing data storage, and ensuring dataquality.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Then there’s dataquality, and then explainability. I’m a product manager at Arize.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Then there’s dataquality, and then explainability. I’m a product manager at Arize.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Then there’s dataquality, and then explainability. I’m a product manager at Arize.
The researchers have taken a step further by releasing RedPajama-V2, a vast, 30 trillion token online dataset, the largest publicly available dataset dedicated to learning-based machine-learning systems. They assert its coverage of CommonCrawl (84 processed dumps) is unparalleled. Check out the Github and Reference Blog.
While effective in creating a base for model training, this foundational approach confronts substantial challenges, notably in ensuring dataquality, mitigating biases, and adequately representing lesser-known languages and dialects. A recent survey by researchers from South China University of Technology, INTSIG Information Co.,
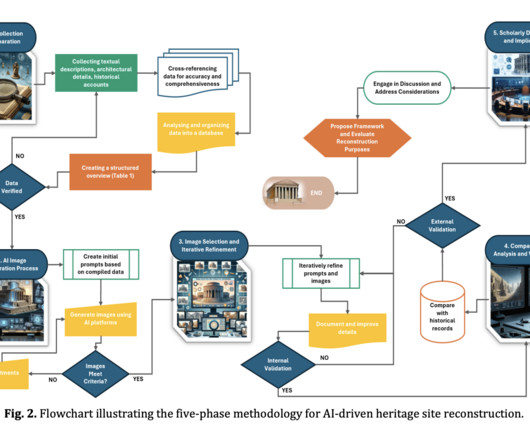
ArchiCAD, AutoCAD), generative adversarial networks (GANs) for image super-resolution, and machinelearning algorithms are transforming the preservation and reconstruction of cultural heritage. Addressing dataquality and algorithm refinement challenges is crucial for enhancing AI’s precision in heritage conservation.
Challenges of building custom LLMs Building custom Large Language Models (LLMs) presents an array of challenges to organizations that can be broadly categorized under data, technical, ethical, and resource-related issues. Ensuring dataquality during collection is also important.
It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality. Introduction Data preprocessing is a critical step in the MachineLearning pipeline, transforming raw data into a clean and usable format.
Almost half of AI projects are doomed by poor dataquality, inaccurate or incomplete datacategorization, unstructured data, and data silos. Avoid these 5 mistakes
In today’s highly competitive market, performing data analytics using machinelearning (ML) models has become a necessity for organizations. It enables them to unlock the value of their data, identify trends, patterns, and predictions, and differentiate themselves from their competitors.
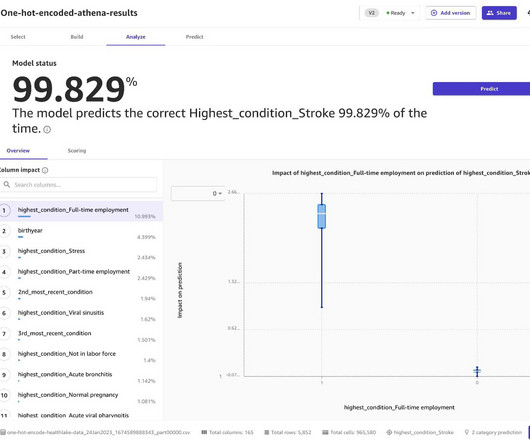
Although machinelearning (ML) can provide valuable insights, ML experts were needed to build customer churn prediction models until the introduction of Amazon SageMaker Canvas. This is enabled by setting aside a portion of the historical training data so it can be compared with what the model predicts for those values.
Photo by Bruno Nascimento on Unsplash Introduction Data is the lifeblood of MachineLearning Models. The dataquality is critical to the performance of the model. The better the data, the greater the results will be. Many MachineLearning algorithms don’t work with missing data.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like MachineLearning. Why Are Data Transformation Tools Important?
Therefore, when the Principal team started tackling this project, they knew that ensuring the highest standard of data security such as regulatory compliance, data privacy, and dataquality would be a non-negotiable, key requirement.
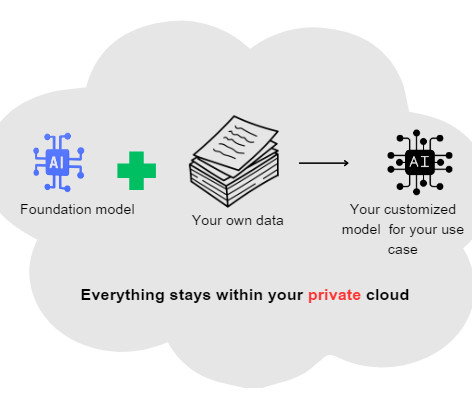
In a recent episode of ODSCs AiX podcast , we had the pleasure of speaking with Chip Huyen , an AI expert and bestselling author of Designing MachineLearning Systems and AI Engineering: Building Applications with Foundation Models. Focus on dataquality over quantity. What is AI Engineering?
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machinelearning (ML) models.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Pixability is a data and technology company that allows advertisers to quickly pinpoint the right content and audience on YouTube. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos. Using AI to help customers optimize ad spending and maximize their reach on YouTube.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content