This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categoricaldata effectively. But what if we could predict a student’s engagement level before they begin? What is CatBoost?
Akeneo is the product experience (PX) company and global leader in Product Information Management (PIM). How is AI transforming product information management (PIM) beyond just centralizing data? Akeneo is described as the “worlds first intelligent product cloud”what sets it apart from traditional PIM solutions?
By recognizing emerging patterns in market data, these platforms help financial institutions adjust their strategies, make informed investment choices, and comply with regulatory requirements. Traditional customer segmentation methods are limited in scope, often categorizing customers into broad groups.
Definition and Types of Hallucinations Hallucinations in LLMs are typically categorized into two main types: factuality hallucination and faithfulness hallucination. It is further divided into: Factual Inconsistency: Occurs when the output contains factual information that contradicts known facts.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning?
In the early days of online shopping, ecommerce brands were categorized as online stores or “multichannel” businesses operating both ecommerce sites and brick-and-mortar locations. But in a channel-less world, data should be used to inform more than FAQ pages, content marketing tactics and email campaigns.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
A Comprehensive Data Science Guide to Preprocessing for Success: From Missing Data to Imbalanced Datasets This member-only story is on us. In just about any organization, the state of informationquality is at the same low level – Olson, DataQualityData is everywhere!
Risk-Based Categorization of AI Technologies Central to the Act is its innovative risk-based framework, which categorizes AI systems into four distinct levels: unacceptable, high, medium, and low risk. In the realm of high-risk AI, the legislation imposes obligations for risk assessment, dataquality control, and human oversight.
Compiling data from these disparate systems into one unified location. This is where data integration comes in! Data integration is the process of combining information from multiple sources to create a consolidated dataset. Data integration tools consolidate this data, breaking down silos. The challenge?
Because its segmentation process is run only by data, we can then learn about customer segments that we hadn’t thought about, and this uncovers unique information about our customers. In those cases, a traditional approach run by humans can work better, especially if you mainly have qualitative data.
.” “When we think about applications of AI to solve real business problems, what we find is that these specialty models are becoming more important,” says Brent Smolinksi, IBM’s Global Head of Tech, Data and AI Strategy. In this context, dataquality often outweighs quantity.
Compiling data from these disparate systems into one unified location. This is where data integration comes in! Data integration is the process of combining information from multiple sources to create a consolidated dataset. Data integration tools consolidate this data, breaking down silos. The challenge?
Some components are categorized in groups based on the type of functionality they exhibit. Here you also have the data sources, processing pipelines, vector stores, and data governance mechanisms that allow tenants to securely discover, access, andthe data they need for their specific use case.
We also detail the steps that data scientists can take to configure the data flow, analyze the dataquality, and add data transformations. Finally, we show how to export the data flow and train a model using SageMaker Autopilot. For more information about prerequisites, see Get Started with Data Wrangler.
These tasks include summarization, classification, information retrieval, open-book Q&A, and custom language generation such as SQL. If the answer contradicts the information in context, it's incorrect. I'll check the table for information. Sonnet across various tasks.
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. They can search within specific categories to narrow down results.
While effective in creating a base for model training, this foundational approach confronts substantial challenges, notably in ensuring dataquality, mitigating biases, and adequately representing lesser-known languages and dialects. A recent survey by researchers from South China University of Technology, INTSIG Information Co.,
Context Awareness: They are often equipped to understand the context in which they operate, using that information to tailor their responses and actions. Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. Remarkably, even without using any labeled data and training solely on synthetic data, it achieved competitive accuracy – only 3.5 Clustering 46.1
Without creating and maintaining data pipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB. Your mobile app stores information about restaurants in Amazon DocumentDB because of its scalability and flexible schema capabilities. For more information, see Add model access.
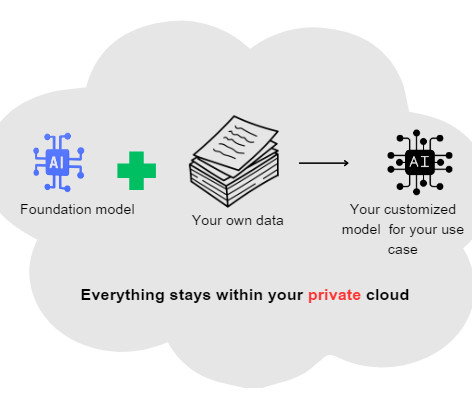
With AI on a private cloud, organizations can ensure that everything, including custom Language Models (LLMs), remains within their secure cloud environment, preserving data privacy and allowing for complete control over their proprietary models and sensitive information. Ensuring dataquality during collection is also important.
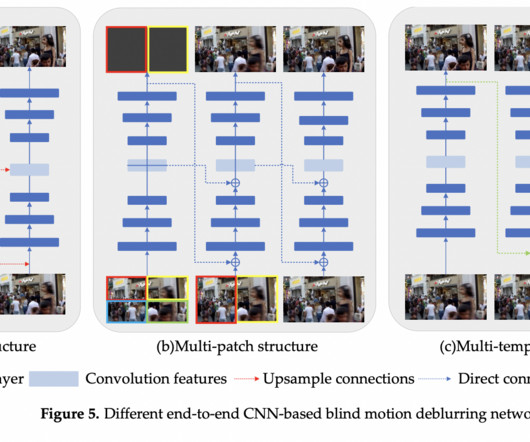
The researchers present a categorization system that uses backbone networks to organize these methods. CNN-based Blind Motion Deblurring CNN is extensively utilized in image processing to capture spatial information and local features. In addition, RNN struggles to grasp spatial information regarding image deblurring tasks.
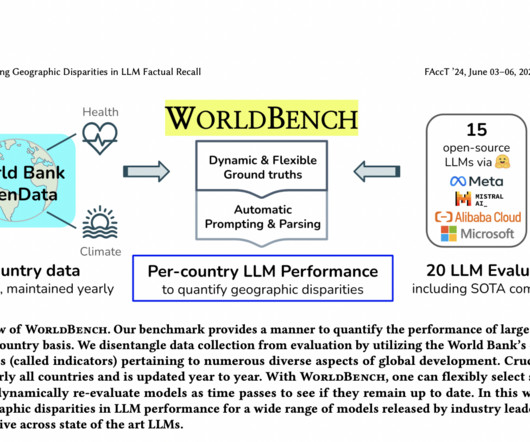
While some researchers have explored geographic information recall, these efforts have been limited in scope. This approach offers several unique advantages: equitable representation of all countries, assured dataquality from a reputable source, and flexibility in indicator selection. and most models near 0.4.
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Model risk : Risk categorization of the model version. The final step is to register the candidate model to the model group as a new model version.
This phenomenon arises because LLMs are trained on vast amounts of online text data. While this allows them to attain strong language modeling capabilities, it also means they learn to extrapolate information, make logical leaps, and fill in gaps in a manner that seems convincing but may be misleading or erroneous.
Starting with a dataset that has details about loan default data in Amazon Simple Storage Service (Amazon S3), we use SageMaker Canvas to gain insights about the data. We then perform feature engineering to apply transformations such as encoding categorical features, dropping features that are not needed, and more.
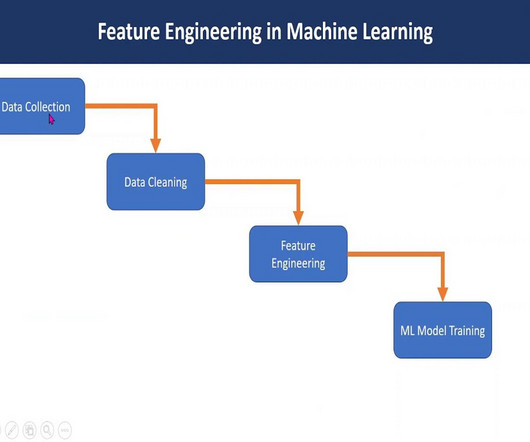
If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. It isn't easy to collect a good amount of qualitydata. How Machine Learning Works? Models […]
The data scientist discovers and subscribes to data and ML resources, accesses the data from SageMaker Canvas, prepares the data, performs feature engineering, builds an ML model, and exports the model back to the Amazon DataZone catalog. A new data flow is created on the Data Wrangler console.
Introduction The presence of large volumes of data within organisations requires effective sorting and analysing ensuring that decision-making is highly credible. Almost all organisations nowadays make informed decisions by leveraging data and analysing the market effectively. What is Data Profiling in ETL?
The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation. For more information, refer to Creating roles and attaching policies (console). Choose Manage Consumer Details.
Content redaction: Each customer audio interaction is recorded as a stereo WAV file, but could potentially include sensitive information such as HIPAA-protected and personally identifiable information (PII). Scalability: This architecture needed to immediately scale to thousands of calls per day and millions of calls per year.
Feature Engineering enhances model performance, and interpretability, mitigates overfitting, accelerates training, improves dataquality, and aids deployment. Feature Engineering is the art of transforming raw data into a format that Machine Learning algorithms can comprehend and leverage effectively.
Photo by Bruno Nascimento on Unsplash Introduction Data is the lifeblood of Machine Learning Models. The dataquality is critical to the performance of the model. The better the data, the greater the results will be. Before we feed data into a learning algorithm, we need to make sure that we pre-process the data.
The article is filled with vital information such as the name of the rocket Falcon 9, the launch site of Kennedy Space Center, the time of the launch Friday morning, and the mission goal to resupply the International Space Station. Now, suppose we want to design a computer program to read this article and extract the same information.
This is what data processing pipelines do for you. Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions. This ensures that the data is accurate, consistent, and reliable.
While gathering operational and consumer information can benefit businesses, they often face obstacles. Some of the top data challenges in the retail industry involve collection and application. Gathering massive amounts of information can be relatively easy, but properly utilizing it can be complex, leading to these data challenges.
These challenges include a limited number of data science experts, the complexity of ML, and the low volume of data due to restricted Protected Health Information (PHI) and infrastructure capacity. No special permissions are required because the data doesn’t contain any sensitive information.
Pixability is a data and technology company that allows advertisers to quickly pinpoint the right content and audience on YouTube. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos. Using AI to help customers optimize ad spending and maximize their reach on YouTube.
These figures underscore the significance of comprehending data methodologies for anyone navigating the digital landscape. Understanding Data Science Data Science involves analysing and interpreting complex data sets to uncover valuable insights that can inform decision-making and solve real-world problems.
It’s about ensuring that this data is handled ethically and legally. Companies must be wary about data privacy, especially in sectors where sensitive data, like health or personal information, is prevalent. Format: determining the structure of your data and identifying any preprocessing needs.
LG AI Research conducted extensive reviews to address potential legal risks like copyright infringement and personal information protection to ensure data compliance. Steps were taken to de-identify sensitive data and ensure that all datasets met strict ethical and legal standards.
It’s about ensuring that this data is handled ethically and legally. Companies must be wary about data privacy, especially in sectors where sensitive data, like health or personal information, is prevalent. Format: determining the structure of your data and identifying any preprocessing needs.
Here are the primary types: Logistic Regression Models: These models use historical data to predict the probability of default. Decision Trees and Random Forests: These models categorize borrowers based on various risk factors. Only complete or updated data can lead to reliable predictions and informed decision-making.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content