This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
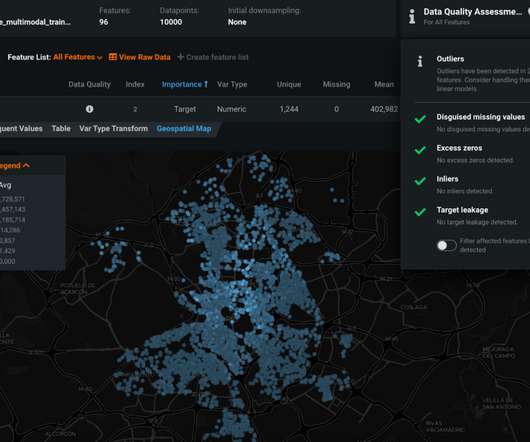
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
Risk-Based Categorization of AI Technologies Central to the Act is its innovative risk-based framework, which categorizes AI systems into four distinct levels: unacceptable, high, medium, and low risk. In the realm of high-risk AI, the legislation imposes obligations for risk assessment, dataquality control, and human oversight.
Documentcategorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizingdocuments into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. This allows for better monitoring and auditing.
It offers both open-source and enterprise/paid versions and facilitates big data management. Key Features: Seamless integration with cloud and on-premise environments, extensive dataquality, and governance tools. Pros: Scalable, strong data governance features, support for big data.
More crucially, they include 40+ quality annotations — the result of multiple ML classifiers on dataquality, minhash results that may be used for fuzzy deduplication, or heuristics. Along with these minhash signatures, the team also do exact deduplication by applying a Bloom filter to the document’s sha1 hash digest.
It offers both open-source and enterprise/paid versions and facilitates big data management. Key Features: Seamless integration with cloud and on-premise environments, extensive dataquality, and governance tools. Pros: Scalable, strong data governance features, support for big data. Visit Hevo Data → 7.
We also detail the steps that data scientists can take to configure the data flow, analyze the dataquality, and add data transformations. Finally, we show how to export the data flow and train a model using SageMaker Autopilot. Data Wrangler creates the report from the sampled data.
Text embeddings are vector representations of words, sentences, paragraphs or documents that capture their semantic meaning. Synthetic Data Generation: Prompt the LLM with the designed prompts to generate hundreds of thousands of (query, document) pairs covering a wide variety of semantic tasks across 93 languages.
Our experiments demonstrate that careful attention to dataquality, hyperparameter optimization, and best practices in the fine-tuning process can yield substantial gains over base models. This decision should be based either on the provided context or your general knowledge and memory.
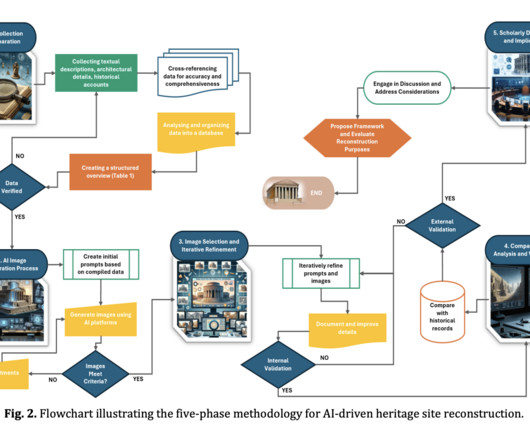
Artificial intelligence (AI) presents a potent solution, providing sophisticated tools to document, analyze, and safeguard cultural heritage. Addressing dataquality and algorithm refinement challenges is crucial for enhancing AI’s precision in heritage conservation. Urgent action is needed to protect these sites.
Inquire whether there is sufficient data to support machine learning. Document assumptions and risks to develop a risk management strategy. Data aggregation such as from hourly to daily or from daily to weekly time steps may also be required. Perform dataquality checks and develop procedures for handling issues.
While effective in creating a base for model training, this foundational approach confronts substantial challenges, notably in ensuring dataquality, mitigating biases, and adequately representing lesser-known languages and dialects. A recent survey by researchers from South China University of Technology, INTSIG Information Co.,
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. On the Analyses tab, choose DataQuality and Insights Report. For Imputing strategy , choose Mean. Choose Add.
Some components are categorized in groups based on the type of functionality they exhibit. Hybrid search – In RAG, you may also optionally want to implement and expose different templates for performing hybrid search that help improve the quality of the retrieved documents. This logic sits in a hybrid search component.
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Model risk : Risk categorization of the model version. These stages are applicable to both use case and model stages. For example, pending or approved.
Taxonomy of Hallucination Mitigation Techniques Researchers have introduced diverse techniques to combat hallucinations in LLMs, which can be categorized into: 1. Heavily depend on training dataquality and external knowledge sources. Retrieval augmentation – Retrieving external evidence to ground content.
Starting with a dataset that has details about loan default data in Amazon Simple Storage Service (Amazon S3), we use SageMaker Canvas to gain insights about the data. We then perform feature engineering to apply transformations such as encoding categorical features, dropping features that are not needed, and more.
The goal of NER is to automatically identify and categorize specific information from vast amounts of text. In AI, entities refer to tangible and intangible elements like people, organizations, locations, and dates embedded in text data. Data Mining : NER is used to identify key entities in large datasets, extracting valuable insights.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. Aggregation : Combining multiple data points into a single summary (e.g.,
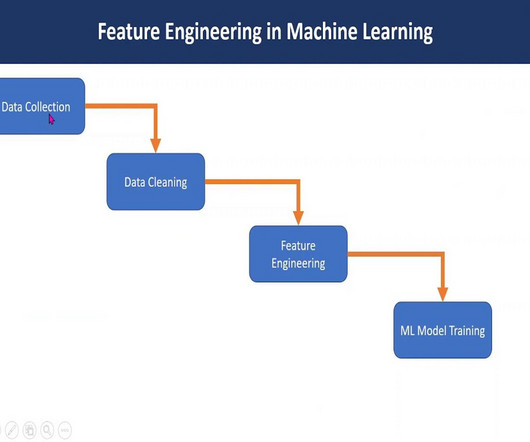
Feature Engineering enhances model performance, and interpretability, mitigates overfitting, accelerates training, improves dataquality, and aids deployment. Feature Engineering is the art of transforming raw data into a format that Machine Learning algorithms can comprehend and leverage effectively.
image source: stoodnt Time is important in the broad domain of legal discovery, where mountains of documents hide the answers to difficult cases. Every minute spent digesting jargon-filled texts and searching through mountains of legal documents delays justice and incurs significant costs.
Scaling clinical trial screening with document classification Memorial Sloan Kettering Cancer Center, the world’s oldest and largest private cancer center, provides care to increase the quality of life of more than 150,000 cancer patients annually. Watch this and many other sessions on-demand at future.snorkel.ai.
The SST2 dataset is a text classification dataset with two labels (0 and 1) and a column of text to categorize. We use a test data preparation notebook as part of this step, which is a dependency for the fine-tuning and batch inference step. Refer to SageMaker documentation for detailed instructions.
Steps were taken to de-identify sensitive data and ensure that all datasets met strict ethical and legal standards. Models were categorized into three groups: real-world use cases, long-context processing, and general domain tasks. Benchmark Evaluations: Unparalleled Performance of EXAONE 3.5
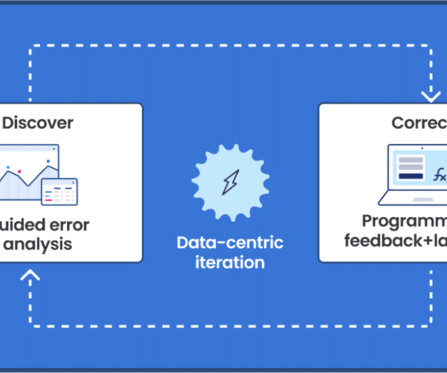
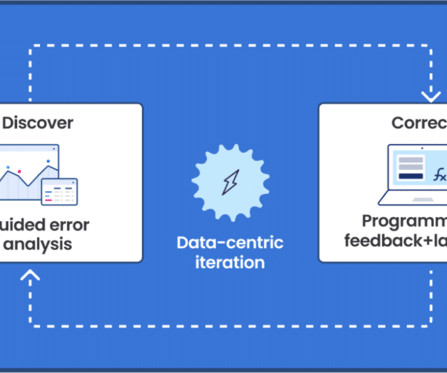
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Causes of hallucinations include insufficient training data, misalignment, attention limitations, and tokenizer issues. Effective mitigation strategies involve enhancing dataquality, alignment, information retrieval methods, and prompt engineering. The idea is to build a search engine over a private set of data (e.g.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Assigning complaints to staff.
Instead of applying uniform regulations, it categorizes AI systems based on their potential risk to society and applies rules accordingly. Document the level of impact for each system. A key aspect of the AI Act is its risk-based approach. This helps determine risk levels, a key aspect of the Act. Does it recommend treatment plans?
The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data. The objective is to enhance the dataquality and prepare the data sets for the analysis. What is Data Manipulation? Data manipulation is crucial for several reasons.
Methods of Data Collection Data collection methods vary widely depending on the field of study, the nature of the data needed, and the resources available. Here are some common methods: Surveys and Questionnaires Researchers use structured tools like surveys to collect numerical or categoricaldata from many participants.
One reason for this bias is the data used to train these models, which often reflects historical gender inequalities present in the text corpus. To address gender bias in AI, it’s crucial to improve the dataquality by including diverse perspectives and avoiding the perpetuation of stereotypes. harness.generate().run().report()
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
Data Transformation Transforming data prepares it for Machine Learning models. Encoding categorical variables converts non-numeric data into a usable format for ML models, often using techniques like one-hot encoding. This includes scaling numerical values, especially when models are sensitive to feature magnitudes.
Applications : Forecasting sales or revenue trends Estimating the impact of marketing campaigns Predicting housing prices based on features such as location, size, and amenities Logistic Regression Unlike linear regression, logistic regression is used when the dependent variable is categorical.
We can categorize the types of AI for the blind and their functions. This is essential for reading signs, labels, menus, and documents, giving visually impaired individuals access to critical information. Data Collection and Annotation Deep learning models are highly dependent on dataquality and volume.
In this educated example , the aim is to predict home prices at the property level in the city of Madrid and the training dataset contains 5 different data types (numerical, categorical, text, location, and images) and +90 variables that are related to these 5 different groups: Market performance. Property performance.
For example, GDPR requires your organization to collect and keep track of metadata about the datasets and to document and report how the resulting model(s) from experiments work. This layer is where you encode the rules of the experiment tracking domain and determine how data is created, stored, and modified.
Sounds crazy, but Wei Shao (Data Scientist at Hortifrut) and Martin Stein (Chief Product Officer at G5) both praised the solution. launched an initiative called ‘ AI 4 Good ‘ to make the world a better place with the help of responsible AI.
To evaluate privacy, the team performed a linkage attack by identifying outliers using the z-score method and then attempting to link synthetic data points with the original data based on quasi-identifiers. The study also showed a trade-off between privacy and dataquality. Don’t Forget to join our 55k+ ML SubReddit.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























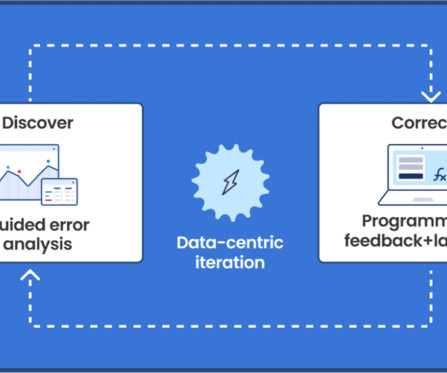
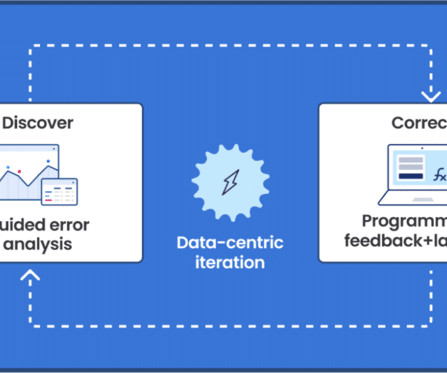
















Let's personalize your content