This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
Data engineering is crucial in today’s digital landscape as organizations increasingly rely on data-driven insights for decision-making. Learning data engineering ensures proficiency in designing robust data pipelines, optimizing data storage, and ensuring dataquality.
Some of the issues make perfect sense as they relate to dataquality, with common issues being bad/unclean data and data bias. What are the biggest challenges in machine learning? select all that apply) Related to the previous question, these are a few issues faced in machine learning.
Add a new Amazon DocumentDB connection by choosing Import data , then choose Tabular for Dataset type. On the Import data page, for Data Source , choose DocumentDB and Add Connection. Enter a connection name such as demo and choose your desired Amazon DocumentDB cluster. Enter a user name, password, and database name.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
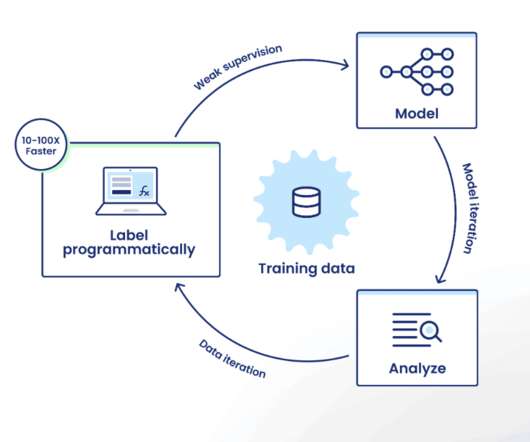
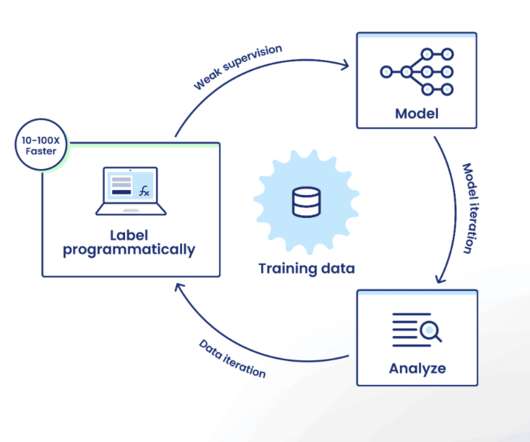
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Machine learning to identify emerging patterns in complaint data and solve widespread issues faster. Book a demo today.
Instead of exclusively relying on a singular data development technique, leverage a variety of techniques such as promoting, RAG, and fine-tuning for the most optimal outcome. Focus on improving dataquality and transforming manual data development processes into programmatic operations to scale fine-tuning.
But this approach is expensive, time-consuming, and out of reach for all but the most well-funded companies, making the use of free, open-source alternatives for data curation appealing if sufficiently high dataquality can be achieved. Book a demo today. See what Snorkel option is right for you.
But this approach is expensive, time-consuming, and out of reach for all but the most well-funded companies, making the use of free, open-source alternatives for data curation appealing if sufficiently high dataquality can be achieved. Book a demo today.
But this approach is expensive, time-consuming, and out of reach for all but the most well-funded companies, making the use of free, open-source alternatives for data curation appealing if sufficiently high dataquality can be achieved. Book a demo today.
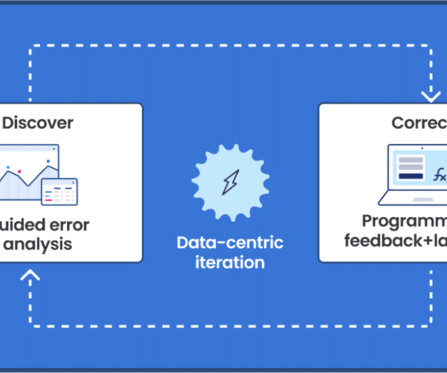
Scenario: Entity linking with payroll data and job classifications I’m building an entity-linking app to connect job listings in a payroll system to a job categorization system developed by the Bureau of Labor Statistics. However, without efficient labeling workflows, putting data-centric AI into practice can be out of reach.
Scenario: Entity linking with payroll data and job classifications I’m building an entity-linking app to connect job listings in a payroll system to a job categorization system developed by the Bureau of Labor Statistics. However, without efficient labeling workflows, putting data-centric AI into practice can be out of reach.
Data visualisation principles include clarity, accuracy, efficiency, consistency, and aesthetics. A bar chart represents categoricaldata with rectangular bars. In contrast, a histogram represents the distribution of numerical data by dividing it into intervals and displaying the frequency of each interval with bars.
Get a demo. Unlike simple segmentation that might just separate foreground from background, semantic segmentation categorizes all pixels in an image into predefined categories. Pixel Classification: Similar to semantic segmentation, each pixel within the bounding box is categorized. What is Segmentation?
But this approach is expensive, time-consuming, and out of reach for all but the most well-funded companies, making the use of free, open-source alternatives for data curation appealing if sufficiently high dataquality can be achieved. Book a demo today.
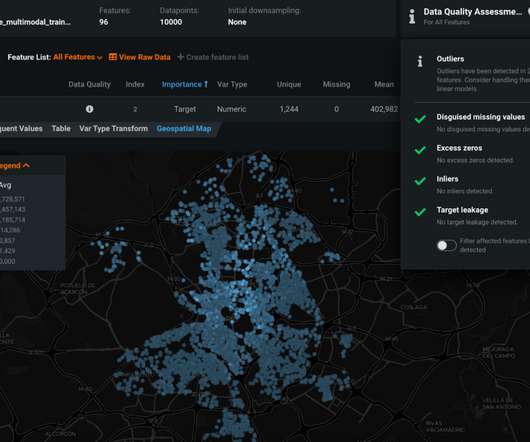
In this educated example , the aim is to predict home prices at the property level in the city of Madrid and the training dataset contains 5 different data types (numerical, categorical, text, location, and images) and +90 variables that are related to these 5 different groups: Market performance. Watch a demo.
To learn more, book a demo with our team. We can categorize the types of AI for the blind and their functions. Data Collection and Annotation Deep learning models are highly dependent on dataquality and volume. Data collection and cleaning are critical steps in developing effective deep-learning models.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content