This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Compiling data from these disparate systems into one unified location. This is where dataintegration comes in! Dataintegration is the process of combining information from multiple sources to create a consolidated dataset. Dataintegration tools consolidate this data, breaking down silos.
Compiling data from these disparate systems into one unified location. This is where dataintegration comes in! Dataintegration is the process of combining information from multiple sources to create a consolidated dataset. Dataintegration tools consolidate this data, breaking down silos.
“Data preprocessing prepares your data before feeding it into your machine-learning models.” This step involves cleaning your data, handling missing values, normalizing or scaling your data and encoding categorical variables into a format your algorithm can understand.
This involves a series of semi-automated or automated operations implemented through data engineering pipeline frameworks. ELT Pipelines: Typically used for big data, these pipelines extract data, load it into data warehouses or lakes, and then transform it.
Perform an analysis on the transformed data Now that transformations have been done on the data, you may want to perform analyses to make sure they haven’t affected dataintegrity. Linear categorical to categorical correlation is not supported. Features that are not either numeric or categorical are ignored.
To make sure that words are properly segmented before feeding them into NLP models, cleaning text data includes adding, deleting, or changing these symbols. Neglecting this preliminary stage may result in inaccurate tokenization, impacting subsequent tasks such as sentiment analysis, language modeling, or text categorization.
Users can take advantage of DATALORE’s data governance, dataintegration, and machine learning services, among others, on cloud computing platforms like Amazon Web Services, Microsoft Azure, and Google Cloud. Because it can handle numeric, textual, and categoricaldata, DATALORE normally beats EDV in every category.
Through the development of cyber recovery plans that include data validation through custom scripts, machine learning to increase data backup and data protection capabilities, and the deployment of virtual machines (VMs) , companies can recover from cyberattacks and prevent re-infection by malware in the future.
Sonnet to analyze and categorize each page of the uploaded document into three main types: intake forms, insurance cards, and doctors notes: # from document_classifier.py Sonnet to analyze and categorize each page of the uploaded document into three main types: intake forms, insurance cards, and doctors notes: # from document_classifier.py
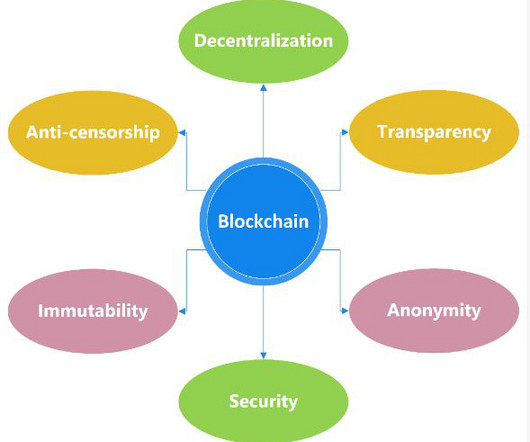
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies.
Interact with data: Analyze uploaded files and answer questions about the data, integrating seamlessly with web searches for a complete view. It allows you to save, annotate, and categorize resources, turning Perplexity into a personal knowledge base.
Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches. Challenges Implementation Complexity: Integrating AI agents into existing systems can be a demanding process, often requiring careful planning around dataintegration, legacy system compatibility, and security.
Some of the popular cloud-based vendors are: Hevo Data Equalum AWS DMS On the other hand, there are vendors offering on-premise data pipeline solutions and are mostly preferred by organizations dealing with highly sensitive data. It supports multi-source integration with capabilities expanding to multiple vendors.
If there are features related to network issues, those users are categorized as network issue-based users. The resultant categorization, along with the predicted churn status for each user, is then transmitted for campaign purposes.
This blog equips you with the top interview questions and answers, categorized by difficulty level. Top DBMS Interview Questions and Answers (2024 Edition) The world runs on data, and at the heart of data management lies the Database Management System (DBMS). They primarily focus on modifying data within the database.
These steps are designed to provide a seamless and efficient integration process, enabling you to deploy the solution effectively with your own data. Integrate knowledge base data To prepare your data for integration, locate the assets/knowledgebase_data_source/ directory and place your dataset within this folder.
Data Profiling Example: Here are some examples of data profiling: Column Data Types and Value Distribution: Identify the data types of each column (e.g., Determine the range of values for categorical columns. Analyze patterns of missing data to understand if they are random or systematic.
Introduction Data transformation plays a crucial role in data processing by ensuring that raw data is properly structured and optimised for analysis. Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors. calculating averages).
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., However, to improve results for specific use cases, developers often fine-tune generative models on small amounts of labeled data. a social media post or product description).
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
This ensures that conclusions drawn from the analysis are valid, enabling researchers to make informed predictions and decisions based on data. Chi-Square Tests For categoricaldata analysis using Chi-Square tests, larger sample sizes are critical for ensuring that expected frequencies meet the minimum requirements for valid results.
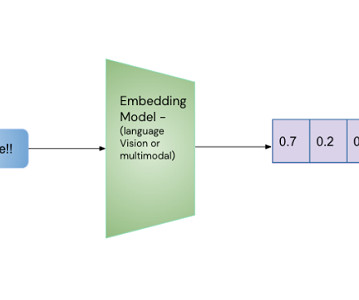
Using Embeddings to Detect Anomalies Figure 1: Using a trained deep neural network, it is possible to convert unstructured data to numeric representations, i.e., embeddings Embeddings are numerical representations generated from unstructured data like images, text, and audio, and greatly influence machine learning approaches for handling such data.
It covers essential skills like data cleaning, problem-solving, and data visualization using tools like SQL, Tableau, and R Programming. By completing the course, you’ll gain the skills to identify the appropriate data analytics strategy for various situations and understand your position within the analytics life cycle.
The primary goal of clustering is to maximise the intra-cluster similarity (data points within the same cluster are similar) while minimising the inter-cluster similarity (data points in different clusters are dissimilar). This process helps uncover hidden patterns and relationships in the data that might not be immediately apparent.
Categorization and grouping Hash Tables can be used to categorize or group items based on certain attributes. For example, they can be used to group emails by sender, categorize products by type, or group transactions by date. Hash functions are used to ensure dataintegrity and verify message authenticity.
By addressing issues like missing values, duplicates, and inconsistencies, preprocessing enhances data quality and reliability for subsequent analysis. Data Cleaning Data cleaning is crucial for dataintegrity. The process ensures data reliability, a prerequisite for sound analysis.
Methods of Data Collection Data collection methods vary widely depending on the field of study, the nature of the data needed, and the resources available. Here are some common methods: Surveys and Questionnaires Researchers use structured tools like surveys to collect numerical or categoricaldata from many participants.
It helps ensure that the data input into a spreadsheet is accurate and conforms to specific criteria, preventing errors and inconsistencies in your data. Data validation is particularly useful when you’re creating forms, surveys, or templates in Excel or when you want to maintain dataintegrity in a shared workbook.
Data visualisation principles include clarity, accuracy, efficiency, consistency, and aesthetics. A bar chart represents categoricaldata with rectangular bars. In contrast, a histogram represents the distribution of numerical data by dividing it into intervals and displaying the frequency of each interval with bars.
Users can categorize material, create queries, extract named entities, find content themes, and calculate sentiment ratings for each of these elements. Panoply Panoply is a cloud-based, intelligent end-to-end data management system that streamlines data from source to analysis without using ETL.
Then, compile the model, harnessing the power of the Adam optimizer and categorical cross-entropy loss. This aids in organizing and categorizing large image datasets, enabling efficient search and retrieval of images based on their content. Images are visual data, while text is linguistic data.
Noise can arise from sensor errors, human mistakes, or extraneous data that doesn’t relate to the problem being solved. Inconsistencies Data that contains contradictions or variations that should not exist. Validation Rules Implement strict validation rules to ensure data adheres to predefined standards.
Here are some popular methods: Regression Techniques Linear regression and its variants model the relationship between historical data (e.g., Decision Trees These tree-like structures categorizedata and predict demand based on a series of sequential decisions. Incorporating External DataIntegrate external data sources (e.g.,
Once preprocessed, you can pass the data to R for advanced statistical analysis and validation. For instance, Python can handle complex categorical encoding, while R can apply domain-specific statistical techniques, ensuring a well-rounded dataset ready for modelling. Libraries like Pandas and Scikit-learn streamline these operations.
Multi-modal dataintegration tasks. It’s particularly effective for large-scale datasets and high-dimensional data. CatBoost CatBoost, developed by Yandex, handles categoricaldata without extensive preprocessing. Requires careful tuning of models and hyperparameters. Recommender systems for e-commerce platforms.
Whether it’s identifying market trends, optimizing business processes, or targeting customer segments, data manipulation is vital in driving strategic actions and achieving desired outcomes. Types of Data Manipulation Data manipulation techniques can be categorized into different types based on the operations performed.
Data mining techniques include classification, regression, clustering, association rule learning, and anomaly detection. These techniques can be applied to a wide range of data types, including numerical data, categoricaldata, text data, and more. MapReduce: simplified data processing on large clusters.
Significance of ETL pipeline in machine learning The significance of ETL pipelines lies in the fact that they enable organizations to derive valuable insights from large and complex data sets. Here are some specific reasons why they are important: DataIntegration: Organizations can integratedata from various sources using ETL pipelines.
These integrations enable generating formulas, categorizingdata, and visualizations using simple language prompts. These limitations highlight the need for strategic planning, especially for organizations looking to integrate LLMs effectively while protecting dataintegrity and ensuring operational reliability.
The Role of Semantic Layers in Self-Service BI Semantic layers simplify data access and play a critical role in maintaining dataintegrity and governance. Time-Consuming Processes: Extracting data manually is labor intensive because it involves extensive cross-functional collaboration.
In order to solve particular business questions, this process usually includes developing and managing data systems, collecting and cleaning data, analyzing it statistically, and interpreting the findings. Simplilearn : It includes top-asked data analyst interview questions, guiding the candidate in the interview process.
MonkeyLearn’s powerful text analysis features enable it to change data visualization quickly and let customers configure classifiers and extractors to automatically categorizedata by subject or purpose or to extract important product aspects and user information.
Decentralized AI reduces data violation risk by letting data stay in its local surroundings while taking part in the training process. Therefore, the secure nature of blockchain guarantees the data to be tamper-proof. Blockchain technology records every transaction in the chain through an immutable ledger.
By analyzing symptoms and medical histories, they categorize cases based on urgency and suggest initial steps before a healthcare provider’s involvement. Data Normalization: Medical data is diverse, including lab results, imaging studies, and clinician notes.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content