This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
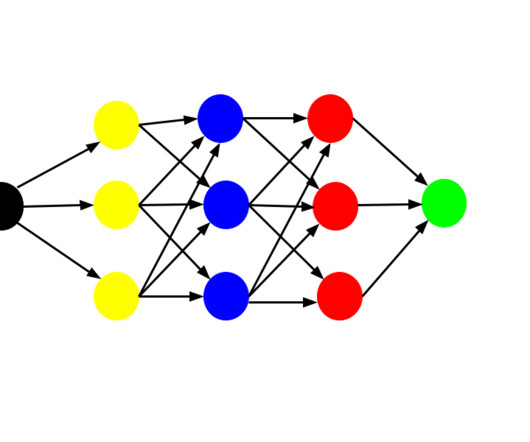
In this guide, we’ll talk about ConvolutionalNeuralNetworks, how to train a CNN, what applications CNNs can be used for, and best practices for using CNNs. What Are ConvolutionalNeuralNetworks CNN? CNNs learn geometric properties on different scales by applying convolutional filters to input data.
In the following, we will explore ConvolutionalNeuralNetworks (CNNs), a key element in computer vision and image processing. Whether you’re a beginner or an experienced practitioner, this guide will provide insights into the mechanics of artificial neuralnetworks and their applications. Howard et al.
Before being fed into the network, the photos are pre-processed and shrunk to the same size. A convolutionalneuralnetwork (CNN) is primarily used for image classification. Convolutional, pooling, and fully linked layers are some of the layers that make up a CNN. X_train = X_train / 255.0 X_test = X_test / 255.0
Traditionally, models for single-view object reconstruction built on convolutionalneuralnetworks have shown remarkable performance in reconstruction tasks. More recent depth estimation frameworks deploy convolutionalneuralnetwork structures to extract depth in a monocular image.
You’ll typically find IoU and mAP used to evaluate the performance of HOG + Linear SVM detectors ( Dalal and Triggs, 2005 ), ConvolutionalNeuralNetwork methods, such as Faster R-CNN ( Girshick et al., Today, we would typically swap in a deeper, more accurate base network, such as ResNet ( He et al., 2015 ; He et al.,
Integrating XGboost with ConvolutionalNeuralNetworks Photo by Alexander Grey on Unsplash XGBoost is a powerful library that performs gradient boosting. For clarity, Tensorflow and Pytorch can be used for building neuralnetworks. It was envisioned by Thongsuwan et al., It was envisioned by Thongsuwan et al.,
Neuralnetworks leverage the structure and properties of graph and work in a similar fashion. Graph NeuralNetworks are a class of artificial neuralnetworks that can be represented as graphs. These tasks require the model to categorize edge types or predict the existence of an edge between two given nodes.
Unlike regression, which deals with continuous output variables, classification involves predicting categorical output variables. They are easy to interpret and can handle both categorical and numerical data. Understand the unique characteristics and challenges of each type to apply the right approach effectively.
Types of Deep Learning Approaches A variety of methods and designs are used to train neuralnetworks under the umbrella of deep learning. Some of the symbolic approaches of deep learning are listed below: CNNs (ConvolutionalNeuralNetworks) : CNNs are frequently employed in image and video recognition jobs.
State of Computer Vision Tasks in 2024 The field of computer vision today involves advanced AI algorithms and architectures, such as convolutionalneuralnetworks (CNNs) and vision transformers ( ViTs ), to process, analyze, and extract relevant patterns from visual data. Get a demo here.
Deep learning models can extract different, and often more useful, features compared to traditional machine learning models for several reasons: Depth Deep learning models, especially ConvolutionalNeuralNetworks (CNNs), have multiple layers that can learn hierarchical representations of the input data.
Furthermore, attention mechanisms work to enhance the explainability or interpretability of AI models. Attention Mechanisms in Deep Learning Attention mechanisms are helping reimagine both convolutionalneuralnetworks ( CNNs ) and sequence models.
The Adam optimizer is used with the initial learning rate specified in the config file, and the loss function used is sparse categorical cross-entropy. format(initial_accuracy)) # train the image classification network print("[INFO] training network.") format(initial_loss)) print("initial accuracy: {: 2f}".format(initial_accuracy))
Over the last six months, a powerful new neuralnetwork playbook has come together for Natural Language Processing. This post explains the components of this new approach, and shows how they’re put together in two recent systems. 2016) model and a convolutionalneuralnetwork (CNN). 2016) HN-ATT 68.2
This can make it challenging for businesses to explain or justify their decisions to customers or regulators. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks Radford et al. Interpretability Foundation models are often described as “black boxes.” What are foundation models?
Convolutionalneuralnetworks (CNNs) and recurrent neuralnetworks (RNNs) are often employed to extract meaningful representations from images and text, respectively. Then, compile the model, harnessing the power of the Adam optimizer and categorical cross-entropy loss.
The AI community categorizes N-shot approaches into few, one, and zero-shot learning. Matching Networks: The algorithm computes embeddings using a support set, and one-shot learns by classifying the query data sample based on which support set embedding is closest to the query embedding – source.
These networks can learn from large volumes of data and are particularly effective in handling tasks such as image recognition and natural language processing. Key Deep Learning models include: ConvolutionalNeuralNetworks (CNNs) CNNs are designed to process structured grid data, such as images.
Applications of Anomaly Detection Figure 3 explains several applications of anomaly detection in various areas. Figure 4: Categorization of Anomalies based on type, latency, application, and method (source: ScienceDirect ). We then introduce spectral clustering, highlighting its advantages over K-Means and explaining how it works.
We can categorize the types of AI for the blind and their functions. With content summarization, we can describe scenes, explain text, and give sentiment analysis. These models usually use a classification algorithm like a ConvolutionalNeuralNetwork (CNN) or a multimodal architecture.
Methods for continual learning can be categorized as regularization-based, architectural, and memory-based, each with specific advantages and drawbacks. For example, convolutionalneuralnetworks achieve significantly better accuracy in continual learning when they use batch normalization and skip connections.
Broadly, image segmentation is categorized into: Semantic Segmentation: Every pixel is labeled based on its class. This module represents a common architectural pattern in convolutionalneuralnetworks, especially in U-Net-like architectures. call the UNet class from the network.py That’s not the case.
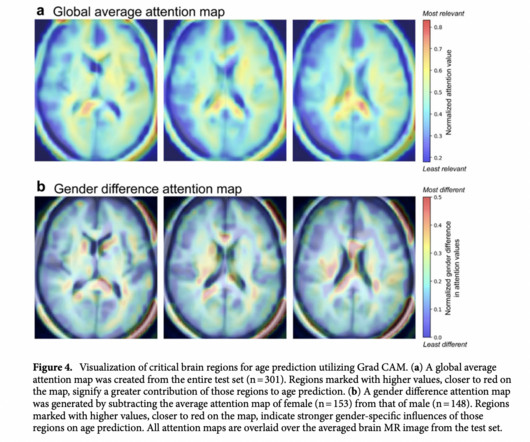
In tackling the intricate task of predicting brain age, researchers introduce a groundbreaking hybrid deep learning model that integrates ConvolutionalNeuralNetworks (CNN) and Multilayer Perceptron (MLP) architectures. Importantly, the model’s performance includes R-square results, indicating a robust fit to the data.
Human Action Recognition (HAR) is a process of identifying and categorizing human actions from videos or image sequences. The VGG model The VGG ( Visual Geometry Group ) model is a deep convolutionalneuralnetwork architecture for image recognition tasks. What is Human action recognition (HAR)? Zisserman and K.
Then, it creates three blocks of layers, each consisting of two convolutional layers followed by batch normalization and dropout. We then compile the model with the Adam optimizer, sparse categorical cross-entropy as the loss function, and accuracy as the metric for evaluation. Or has to involve complex mathematics and equations?
Convolutionalneuralnetworks ( CNNs ) are a subtype of artificial neuralnetworks that have been popular in several applications linked to computer vision and are attracting interest in other domains. It also offers comprehensive developer instructions. To get a baseline score, we shall employ a CNN model.
They have shown impressive performance in various computer vision tasks, often outperforming traditional convolutionalneuralnetworks (CNNs). Airbnb uses ViTs for several purposes in their photo tour feature: Image classification : Categorizing photos into different room types (bedroom, bathroom, kitchen, etc.)
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content