This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
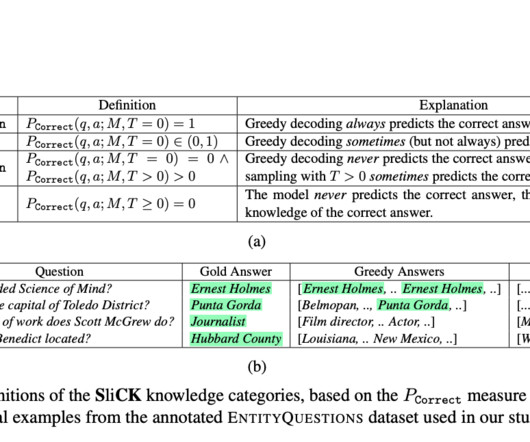
Research in computationallinguistics continues to explore how largelanguagemodels (LLMs) can be adapted to integrate new knowledge without compromising the integrity of existing information. The study’s findings demonstrate the effectiveness of the SliCK categorization in enhancing the fine-tuning process.
What are LargeLanguageModels (LLMs)? In generative AI, human language is perceived as a difficult data type. If a computer program is trained on enough data such that it can analyze, understand, and generate responses in natural language and other forms of content, it is called a LargeLanguageModel (LLM).
The development of LargeLanguageModels (LLMs), such as GPT and BERT, represents a remarkable leap in computationallinguistics. Training these models, however, is challenging. The system’s error detection mechanism is designed to identify and categorize failures during execution promptly.
While we can only guess whether some powerful future AI will categorize us as unintelligent, what’s clear is that there is an explicit and concerning contempt for the human animal among prominent AI boosters. Humans, like animals, are vulnerable, breakable creatures who can only thrive within a specific set of physical and social constraints.
On the other hand, Sentiment analysis is a method for automatically identifying, extracting, and categorizing subjective information from textual data. The 49th Annual Meeting of the Association for ComputationalLinguistics (ACL 2011). Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts.
Cross-lingual performance prediction [42] could be used to estimate performance for a broader set of languages. Multilingual vs English-centric models Let us now take a step back and look at recent largelanguagemodels in NLP in general. Joshi et al. [92] Vulić, I., & Søgaard, A. Winata, G.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content