This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
To maximize the value of their AI initiatives, organizations must maintain dataintegrity throughout its lifecycle. Every organization aims for up-to-date information, real-time market awareness, and insights to achieve optimal business results. Managing this level of oversight requires adept handling of large volumes of data.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.)
This article will explore data warehousing, its architecture types, key components, benefits, and challenges. What is Data Warehousing? Data warehousing is a data management system to support BusinessIntelligence (BI) operations. It can handle vast amounts of data and facilitate complex queries.
Analytics, management, and businessintelligence (BI) procedures, such as data cleansing, transformation, and decision-making, rely on data profiling. Content and quality reviews are becoming more important as data sets grow in size and variety of sources. The 18 best data profiling tools are listed below.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for businessintelligence and data science use cases.
Extraction of relevant data points for electronic health records (EHRs) and clinical trial databases. Dataintegration and reporting The extracted insights and recommendations are integrated into the relevant clinical trial management systems, EHRs, and reporting mechanisms.
Storage Optimization: Data warehouses use columnar storage formats and indexing to enhance query performance and data compression. They excel at managing structured data and supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions.
Irina Steenbeek introduces the concept of descriptive lineage as “a method to record metadata-based data lineage manually in a repository.” Extraction, transformation and loading (ETL) tools dominated the dataintegration scene at the time, used primarily for data warehousing and businessintelligence.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
Its in-memory processing helps to ensure that data is ready for quick analysis and reporting, enabling real-time what-if scenarios and reports without lag. Our solution handles massive multidimensional cubes seamlessly, enabling you to maintain a complete view of your data without sacrificing performance or dataintegrity.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
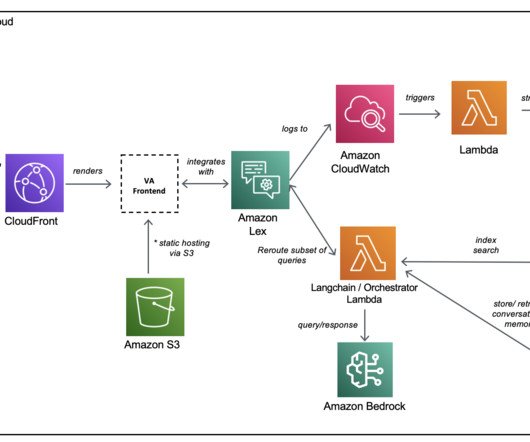
Metadata about the request/response pairings are logged to Amazon CloudWatch. As an Information Technology Leader, Jay specializes in artificial intelligence, dataintegration, businessintelligence, and user interface domains.
They enhance dataintegrity, security, and accessibility while providing tools for efficient data management and retrieval. A Database Management System (DBMS) is specialised software designed to efficiently manage and organise data within a computer system. Indices are data structures optimised for rapid data retrieval.
On the other hand, a Data Warehouse is a structured storage system designed for efficient querying and analysis. It involves the extraction, transformation, and loading (ETL) process to organize data for businessintelligence purposes. It often serves as a source for Data Warehouses. What Is Data Lake Architecture?
This period also saw the development of the first data warehouses, large storage repositories that held data from different sources in a consistent format. The concept of data warehousing was introduced by Bill Inmon, often referred to as the “father of data warehousing.” Morgan Kaufmann. Dean, J., & Ghemawat, S.
By leveraging data services and APIs, a data fabric can also pull together data from legacy systems, data lakes, data warehouses and SQL databases, providing a holistic view into business performance. It uses knowledge graphs, semantics and AI/ML technology to discover patterns in various types of metadata.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content