

Data4ML Preparation Guidelines (Beyond The Basics)
Towards AI
NOVEMBER 8, 2024
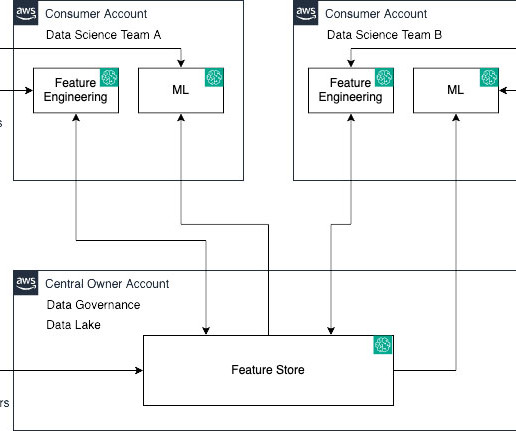
Data preparation isn’t just a part of the ML engineering process — it’s the heart of it. Data is a key differentiator in ML projects (more on this in my blog post below). This step, often done with data engineers, ensures a reproducible data snapshot from sources like production databases or APIs.









































Let's personalize your content