This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction to ETLETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build BigData.
ELT Pipelines: Typically used for bigdata, these pipelines extract data, load it into data warehouses or lakes, and then transform it. Detailed Examination of Tools Apache Spark: An open-source platform supporting multiple languages (Python, Java, SQL, Scala, and R).
It offers both open-source and enterprise/paid versions and facilitates bigdata management. Key Features: Seamless integration with cloud and on-premise environments, extensive data quality, and governance tools. Pros: Scalable, strong data governance features, support for bigdata.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
It offers both open-source and enterprise/paid versions and facilitates bigdata management. Key Features: Seamless integration with cloud and on-premise environments, extensive data quality, and governance tools. Pros: Scalable, strong data governance features, support for bigdata.
Summary: Data engineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, prepare data for analytics and ML, and train ML models. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. BigData Architect.
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. When the data is in CSV format, use an Amazon SageMaker Jupyter notebook to run a PySpark script to load the raw data into Neptune and visualize it in a Jupyter notebook.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. Introduction Apache Spark and Hadoop are potent frameworks for bigdata processing and distributed computing. Apache Spark is an open-source, unified analytics engine for large-scale data processing.
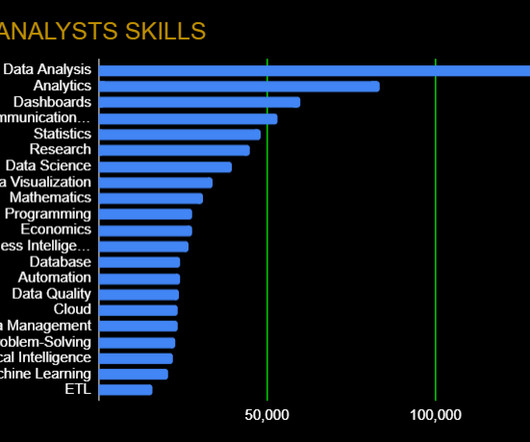
Data Wrangling: Data Quality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. These jobs can be run immediately or on a recurring time schedule without the need for data workers to refactor code as Python modules.
But, the amount of data companies must manage is growing at a staggering rate. Research analyst firm Statista forecasts global data creation will hit 180 zettabytes by 2025. In our discussion, we cover the genesis of the HPCC Systems data lake platform and what makes it different from other bigdata solutions currently available.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring data quality and integrity.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by Data Scientists. How to Become an Azure Data Engineer? Which service would you use to create Data Warehouse in Azure?
Ensures data protection and leaks by ensuring best practices for data storage. Now that’s out of the way, let’s get to the details of each offer: Apache Airflow Overview It is one of the most popular open-source python-based data pipeline tools with high flexibility in creating workflows and tasks.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
This week, I will cover why I think data janitor work is dying and companies that are built in on top of data janitor work could be ripe for disruption through LLMs and what to do about it. A data janitor is a person who works to take bigdata and condense it into useful amounts of information.
Bigdata analytics are supported by scalable, object-oriented services. Each of the “buckets” used to store data has a maximum capacity of 5 terabytes. Python and SQL are supported languages for machine learning research. Bigdata services and enterprise-level integration are both extensively supported.
Read Blogs: Crucial Statistics Interview Questions for Data Science Success. Python Interview Questions And Answers. MongoDB is a NoSQL database that handles large-scale data and modern application requirements. In contrast, MongoDB uses a more straightforward query language that works well with JSON data structures.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content