This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
With their own unique architecture, capabilities, and optimum use cases, data warehouses and bigdata systems are two popular solutions. The differences between data warehouses and bigdata have been discussed in this article, along with their functions, areas of strength, and considerations for businesses.
With CustomerAI, brands can expand their perception of customer data, activate it more extensively, and be better informed by a deeper understanding of their customers. AN: What will Twilio be sharing with the audience at this year’s AI & BigData Expo Europe? With Segment, you choose where you start.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. For more information on enabling users in IAM Identity Center, see Add users to your Identity Center directory. Data Engineer at Amazon Ads.
Apart from the time-sensitive necessity of running a business with perishable, delicate goods, the company has significantly adopted Azure, moving some existing ETL applications to the cloud, while Hershey’s operations are built on a complex SAP environment. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
Compiling data from these disparate systems into one unified location. This is where data integration comes in! Data integration is the process of combining information from multiple sources to create a consolidated dataset. Data integration tools consolidate this data, breaking down silos. The challenge?
Compiling data from these disparate systems into one unified location. This is where data integration comes in! Data integration is the process of combining information from multiple sources to create a consolidated dataset. Data integration tools consolidate this data, breaking down silos. The challenge?
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use bigdata to make critical business decisions. However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Enter data warehousing!
Extract, Transform, and Load are referred to as ETL. ETL is the process of gathering data from numerous sources, standardizing it, and then transferring it to a central database, data lake, data warehouse, or data store for additional analysis. Involved in each step of the end-to-end ETL process are: 1.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
Understanding Data Engineering Data engineering is collecting, storing, and organising data so businesses can use it effectively. It involves building systems that move and transform raw data into a usable format. Without data engineering , companies would struggle to analyse information and make informed decisions.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Summary: HDFS in BigData uses distributed storage and replication to manage massive datasets efficiently. By co-locating data and computations, HDFS delivers high throughput, enabling advanced analytics and driving data-driven insights across various industries. It fosters reliability. between 2024 and 2030.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. When the data is in CSV format, use an Amazon SageMaker Jupyter notebook to run a PySpark script to load the raw data into Neptune and visualize it in a Jupyter notebook.
Embeddings capture the information content in bodies of text, allowing natural language processing (NLP) models to work with language in a numeric form. Embeddings are just vectors of floating point numbers, so we can analyze them to help answer three important questions: Is our reference data changing over time?
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As a result, data lakes can accommodate vast volumes of data from different sources, providing a cost-effective and scalable solution for handling bigdata.
Data profiling is a crucial tool. For evaluating data quality. It entails analyzing, cleansing, transforming, and modeling data to find valuable information, improve data quality, and assist in better decision-making, What is Data Profiling?
To ensure the highest quality measurement of your question answering application against ground truth, the evaluation metrics implementation must inform ground truth curation. By following these guidelines, data teams can implement high fidelity ground truth generation for question-answering use case evaluation with FMEval.
With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration. Overview In the era of BigData , organizations inundated with vast amounts of information generated from various sources. How Does Apache NiFi Ensure Data Integrity?
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. Introduction Apache Spark and Hadoop are potent frameworks for bigdata processing and distributed computing. Apache Spark is an open-source, unified analytics engine for large-scale data processing.
Summary: Understanding Business Intelligence Architecture is essential for organizations seeking to harness data effectively. This framework includes components like data sources, integration, storage, analysis, visualization, and information delivery. Data Lakes: These store raw, unprocessed data in its original format.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
These tools transform raw data into actionable insights, enabling businesses to make informed decisions, improve operational efficiency, and adapt to market trends effectively. Introduction Business Intelligence (BI) tools are essential for organizations looking to harness data effectively and make informed decisions.
Eight prominent concepts stand out: Customer Data Platforms (CDPs), Master Data Management (MDM), Data Lakes, Data Warehouses, Data Lakehouses, Data Marts, Feature Stores, and Enterprise Resource Planning (ERP). Pros: Data Consistency: Ensures consistent and accurate data across the organization.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Thus, making it easier for analysts and data scientists to leverage their SQL skills for BigData analysis.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
Data analysis helps organizations make informed decisions by turning raw data into actionable insights. With businesses increasingly relying on data-driven strategies, the demand for skilled data analysts is rising. You’ll learn the fundamentals of gathering, cleaning, analyzing, and visualizing data.
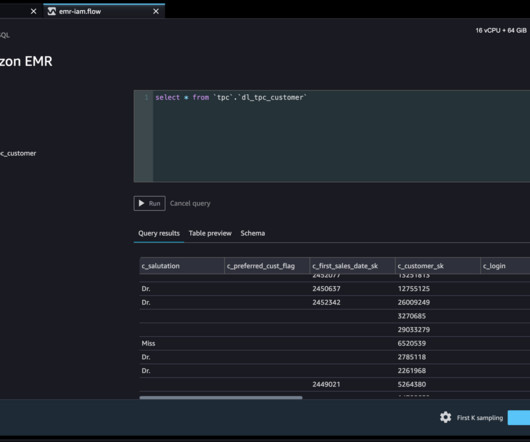
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks. For more information, refer to Create keys and certificates for data encryption.
This flexibility allows organizations to store vast amounts of raw data without the need for extensive preprocessing, providing a comprehensive view of information. Centralized Data Repository Data Lakes serve as a centralized repository, consolidating data from different sources within an organization.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring data quality and integrity.
This article explores how data engineering can improve Customer 360 initiatives for AWS data engineering , bigdata engineering, and data analytics companies. Doing so enables companies to personalise their offerings, enhancing client satisfaction and helping make more informed decision-making processes.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks.
It relates to employing algorithms to find and examine data patterns to forecast future events. Through practice, machines pick up information or skills (or data). Deep learning is a branch of machine learning frequently used with text, audio, visual, or photographic data. Built to use predictive models.
From the above, you can see how Data Warehousing has grown crucial for large and medium-sized enterprises. Data Warehouse facilitates the team’s access to data and helps them draw conclusions from the information and merge data from many sources. It expedites access to helpful information in this way.
This is what data processing pipelines do for you. Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions.
This week, I will cover why I think data janitor work is dying and companies that are built in on top of data janitor work could be ripe for disruption through LLMs and what to do about it. A data janitor is a person who works to take bigdata and condense it into useful amounts of information.
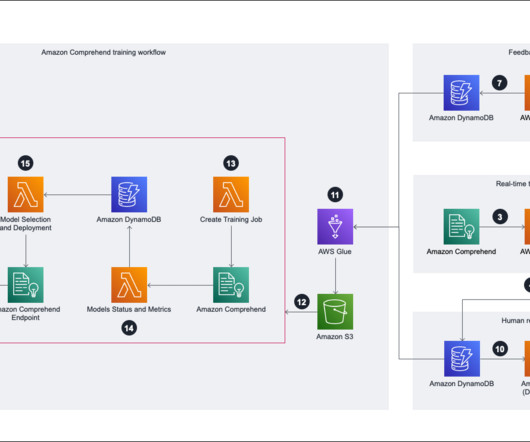
To solve this problem, Pro360 initially added options and choices for the customer, such as “I would like more information” or “No, I have other options.” Amazon Comprehend training workflow To start the training the Amazon Comprehend model, we need to prepare the training data. This made it even more challenging.
By providing a true expected outcome to measure against, ground truth data unlocks the ability to deterministically evaluate system quality. Ground truth curation and metric interpretation are tightly coupled, and the implementation of the evaluation metric must inform ground truth curation to achieve best results.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content