This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Ahead of AI & BigData Expo Europe, AI News caught up with Ivo Everts, Senior Solutions Architect at Databricks , to discuss several key developments set to shape the future of open-source AI and data governance. It was trained more efficiently due to a variety of technological advances.
Operationalisation needs good orchestration to make it work, as Basil Faruqui, director of solutions marketing at BMC , explains. “If CRMs and ERPs had been going the SaaS route for a while, but we started seeing more demands from the operations world for SaaS consumption models,” explains Faruqui.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
Nowadays most businesses use data science, whether a business is product-based or service-based they use data science for their growth. Data Science and BigData There is an Umbrella of Bigdata and what is BigData?
We also explained the end-to-end user experience of the SageMaker Unified Studio for two different use cases of notebook and query. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. Chiho Sugimoto is a Cloud Support Engineer on the AWS BigData Support team.
We calculate the following information based on the clustering output shown in the following figure: The number of dimensions in PCA that explain 95% of the variance The location of each cluster center, or centroid Additionally, we look at the proportion (higher or lower) of samples in each cluster, as shown in the following figure.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
Top 50+ Interview Questions for Data Analysts Technical Questions SQL Queries What is SQL, and why is it necessary for data analysis? SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. Data Visualisation What are the fundamental principles of data visualisation?
The company’s H20 Driverless AI streamlines AI development and predictive analytics for professionals and citizen data scientists through open source and customized recipes. When necessary, the platform also enables numerous governance and explainability elements.
I started working in Data Science right after graduating with an MS degree in Electrical and Computer Engineering from the University of California, Los Angeles (UCLA). You might even need to write custom data crawling code, find public datasets, and find pragmatic ways to augment data to solve the problem.
Bigdata analytics are supported by scalable, object-oriented services. Each of the “buckets” used to store data has a maximum capacity of 5 terabytes. The platform’s schema independence allows you to directly consume data in any format or type.
In contrast, MongoDB uses a more straightforward query language that works well with JSON data structures. MongoDB’s horizontal scaling capabilities surpass relational databases’ typical vertical scaling limitations, making it suitable for bigdata applications. Explain The Difference Between MongoDB and SQL Databases.
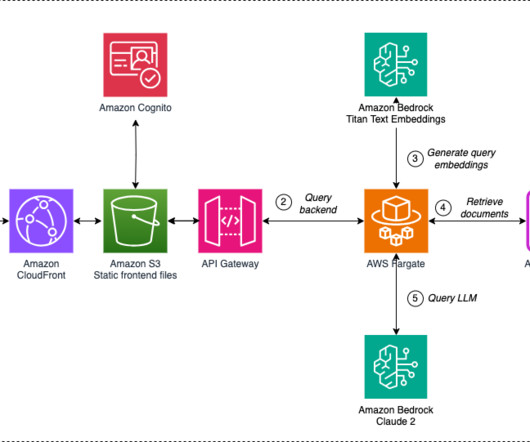
In this post, we explain how Cepsa Química and partner Keepler have implemented a generative AI assistant to increase the efficiency of the product stewardship team when answering compliance queries related to the chemical products they market. The following diagram illustrates this architecture.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content