This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon A datascientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Datascientists often spend up to 80% of their time on data engineering in data science projects.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Automation has been a key trend in the past few years and that ranges from the design to building of a data warehouse to loading and maintaining, all of that can be automated. So pretty much what is available to a developer or datascientist who is working with the open source libraries and going through their own data science journey.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Data Science focuses on analysing data to find patterns and make predictions. Data engineering, on the other hand, builds the foundation that makes this analysis possible. Without well-structured data, DataScientists cannot perform their work efficiently. billion in 2024 , is expected to reach $325.01
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. BigData Architect.
Working as a DataScientist — Expectation versus Reality! 11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. As I was working on these projects, I knew I wanted to work as a DataScientist once I graduate.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
You may use OpenRefine for more than just data cleaning; it can also help you find mistakes and outliers that could compromise your data’s quality. Apache Griffin Apache Griffin is an open-source data quality tool that aims to enhance bigdata processes.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
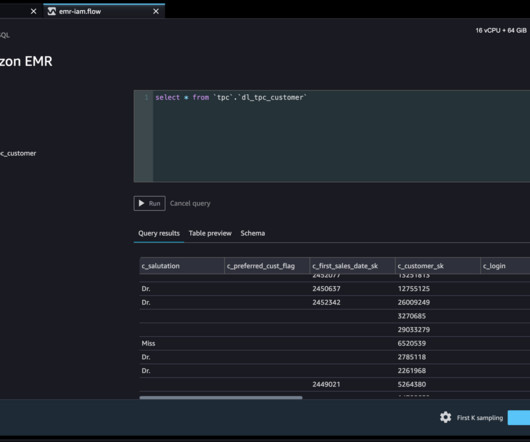
We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. In this post, we show how to use Lake Formation as a central data governance capability and Amazon EMR as a bigdata query engine to enable access for SageMaker Data Wrangler.
Thus, making it easier for analysts and datascientists to leverage their SQL skills for BigData analysis. It applies the data structure during querying rather than data ingestion. This integration allows users to combine the strengths of different tools and frameworks to solve complex big-data challenges.
Performance: Query performance can be slower compared to optimized data stores. Business Applications: BigData Analytics : Supporting advanced analytics, machine learning, and artificial intelligence applications. Data Archival : Storing historical data that might be needed for future analysis.
The company’s H20 Driverless AI streamlines AI development and predictive analytics for professionals and citizen datascientists through open source and customized recipes. The platform makes collaborative data science better for corporate users and simplifies predictive analytics for professional datascientists.
About the authors Samantha Stuart is a DataScientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. He collaborates closely with enterprise customers building modern data platforms, generative AI applications, and MLOps.
Data Analytics in the Age of AI, When to Use RAG, Examples of Data Visualization with D3 and Vega, and ODSC East Selling Out Soon Data Analytics in the Age of AI Let’s explore the multifaceted ways in which AI is revolutionizing data analytics, making it more accessible, efficient, and insightful than ever before.
Data Wrangling: Data Quality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring data quality and integrity.
But, the amount of data companies must manage is growing at a staggering rate. Research analyst firm Statista forecasts global data creation will hit 180 zettabytes by 2025. In our discussion, we cover the genesis of the HPCC Systems data lake platform and what makes it different from other bigdata solutions currently available.
Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible. Importance of Data Lakes Data Lakes play a pivotal role in modern data analytics, providing a platform for DataScientists and analysts to extract valuable insights from diverse data sources.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by DataScientists. How to Become an Azure Data Engineer? Which service would you use to create Data Warehouse in Azure?
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks. MongoDB, developed by MongoDB Inc.,
Confirmed sessions related to software engineering include: Building Data Contracts with Open-Source Tools Chronon — Open Source Data Platform for AI/ML Creating APIs That DataScientists Will Love with FastAPI, SQLAlchemy, and Pydantic Using APIs in Data Science Without Breaking Anything Don’t Go Over the Deep End: Building an Effective OSS Management (..)
And since the advent of cloud data warehouse, I was lucky enough to get a good amount of exposure on Google Cloud Platform in the early stages of the era which became my competitive edge in this wild job market. A lot of you who are already in the data science field must be familiar with BigQuery and its advantages.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
By following these guidelines, datascientists can quantify the user experience delivered by their generative AI pipelines and communicate meaning to business stakeholders, facilitating ready comparisons across different architectures, such as Retrieval Augmented Generation (RAG) pipelines, off-the-shelf or fine-tuned LLMs, or agentic solutions.
It often requires multiple teams working together and integrating various data sources, tools, and services. For example, creating a targeted marketing app involves data engineers, datascientists, and business analysts using different systems and tools.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
This is a guest post co-written with Vicente Cruz Mínguez, Head of Data and Advanced Analytics at Cepsa Química, and Marcos Fernández Díaz, Senior DataScientist at Keepler. About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
About the Authors Siokhan Kouassi is a DataScientist at Parameta Solutions with expertise in statistical machine learning, deep learning, and generative AI. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content