This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
This article was published as a part of the DataScience Blogathon. Introduction The purpose of a data warehouse is to combine multiple sources to generate different insights that help companies make better decisions and forecasting. It consists of historical and commutative data from single or multiple sources.
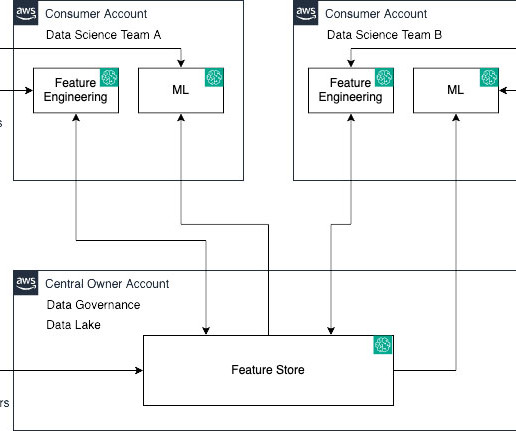
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, data lakes, and datascience teams, and maintaining compliance with relevant financial regulations.
Ahead of AI & BigData Expo Europe , Han Heloir, EMEA gen AI senior solutions architect at MongoDB , discusses the future of AI-powered applications and the role of scalable databases in supporting generative AI and enhancing business processes. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
Typically, on their own, data warehouses can be restricted by high storage costs that limit AI and ML model collaboration and deployments, while data lakes can result in low-performing datascience workloads. How does an open data lakehouse architecture support AI? All of this supports the use of AI.
But most important of all, the assumed dormant value in the unstructured data is a question mark, which can only be answered after these sophisticated techniques have been applied. Therefore, there is a need to being able to analyze and extract value from the data economically and flexibly. The solution integrates data in three tiers.
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use bigdata to make critical business decisions. However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Enter data warehousing!
Datascience tasks such as machine learning also greatly benefit from good data integrity. When an underlying machine learning model is being trained on data records that are trustworthy and accurate, the better that model will be at making business predictions or automating tasks.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. Perform data quality monitoring based on pre-configured rules.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. Today, generative AI can enable people without SQL knowledge.
Finance Organizations Detect Fraud in a Fraction of a Second Financial organizations face a significant challenge in detecting patterns of fraud due to the vast amount of transactional data that requires rapid analysis. Additionally, the scarcity of labeled data for actual instances of fraud poses a difficulty in training AI models.
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake.
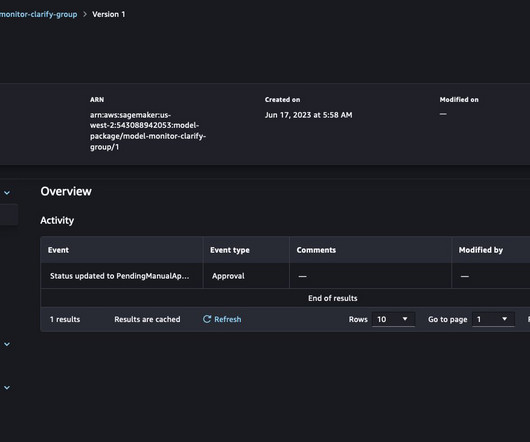
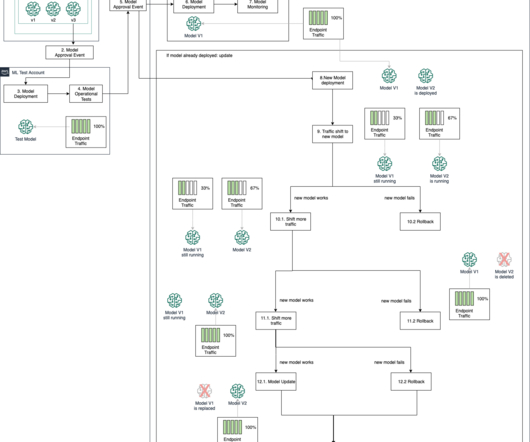
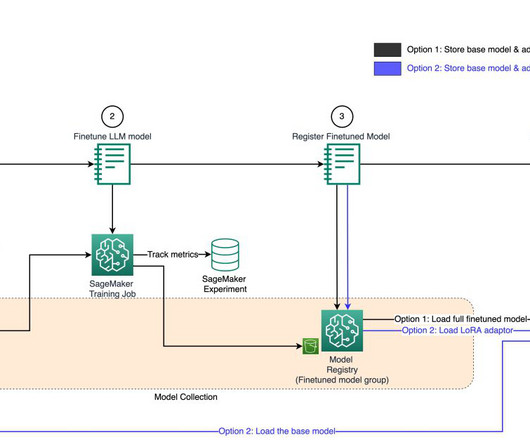
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. An experiment collects multiple runs with the same objective.
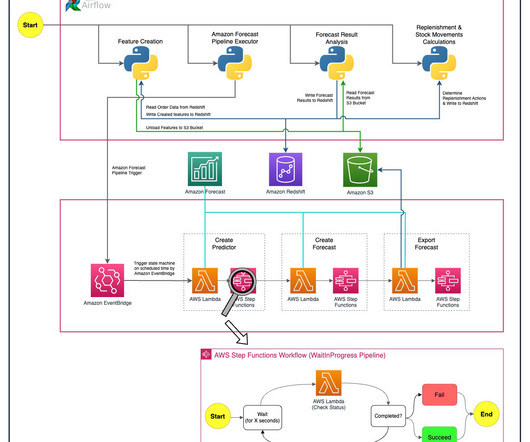
Solution overview Six people from Getir’s datascience team and infrastructure team worked together on this project. Deep/neural network algorithms also perform very well on sparse data set and in cold-start (new item introduction) scenarios. The following diagram shows the solution’s architecture.
Images can often be searched using supplemented metadata such as keywords. However, it takes a lot of manual effort to add detailed metadata to potentially thousands of images. Generative AI (GenAI) can be helpful in generating the metadata automatically. This helps us build more refined searches in the image search process.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. The model registry supports a hierarchical structure for organizing and storing ML models with model metadata information.
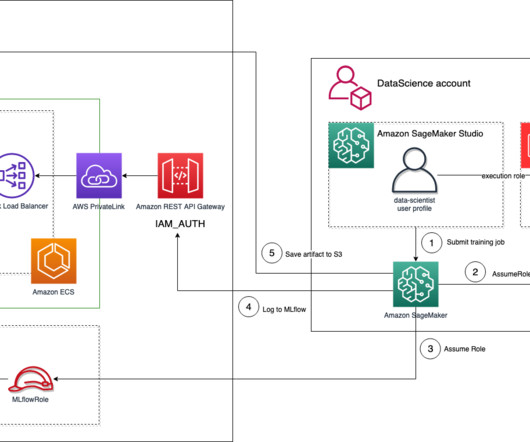
ML platform services This module helps the ML platform engineering team set up shared services that are used by the datascience teams on their team accounts. For example, you can set a proactive control that checks that direct internet access is not allowed for a SageMaker notebook instance.
model.create() creates a model entity, which will be included in the custom metadata registered for this model version and later used in the second pipeline for batch inference and model monitoring. In Studio, you can choose any step to see its key metadata. large", accelerator_type="ml.eia1.medium", large", accelerator_type="ml.eia1.medium",
AWS also focuses on customers of all sizes and industries so they can store and protect any amount of data for virtually any use case, such as data lakes, cloud-native applications, and mobile apps while providing easy-to-use management features. But that’s not where they end their services. Delta & Databricks Make This A Reality!
Priorities for Data Cubes evolution Users and developers discussed some of the main trends in the evolution of data cubes and best practices moving forward, such as how to overcome bottlenecks, and key technologies to improve efficiency and accessibility. 2/2) What should be the priority for the data cube evolution?
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. He collaborates closely with enterprise customers building modern data platforms, generative AI applications, and MLOps. You can customize the prompt examples to fit your ground truth use case.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
There are two distinct categories of permissions associated with sharing resources: Discoverability permissions – Discoverability means being able to see feature group names and metadata. With a background in datascience and mechanical engineering, his focus is on empowering customers to create lasting business impact with the help of AI.
Monitoring metadata and output When the job starts, a Lambda function writes the job processing metadata (the current job configuration and other log information) into the DynamoDB log table. This metadata and log information maintains a history of the job, its initial and ongoing configuration, and other important data.
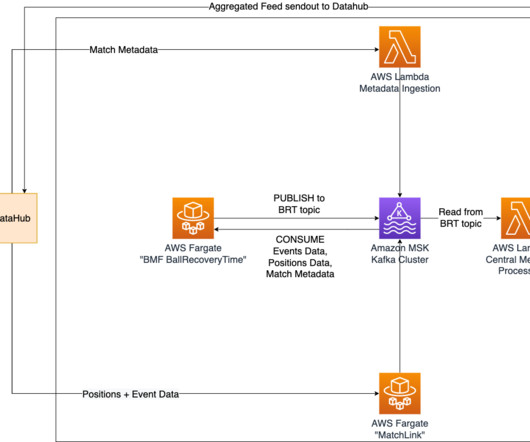
This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time. The match-related data is collected and ingested using DFL’s DataHub. Both the Lambda function and the Fargate container publish the data for further consumption in the relevant MSK topics.
Additionally, you can enable model invocation logging to collect invocation logs, full request response data, and metadata for all Amazon Bedrock model API invocations in your AWS account. Tanvi Singhal is a Data Scientist within AWS Professional Services.
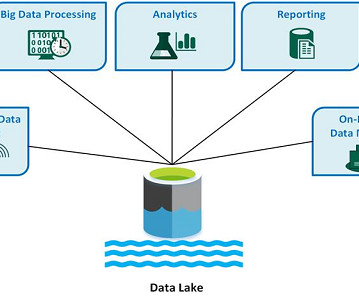
Data scientists can explore, experiment, and derive valuable insights without the constraints of a predefined structure. This capability empowers organizations to uncover hidden patterns, trends, and correlations in their data, leading to more informed decision-making. What Is Data Lake Architecture? The post Data Lakes Vs.
In this example, a model is developed in SageMaker using SageMaker Processing jobs to run data processing code that is used to prepare data for an ML algorithm. SageMaker Training jobs are then used to train an ML model on the data produced by the processing job.
Because request_auth_aws_sigv4 uses Boto3 to retrieve credentials, we know that it can load credentials from the instance metadata when an IAM role is associated with an Amazon Elastic Compute Cloud (Amazon EC2) instance (for other ways to supply credentials to Boto3, see Credentials ).
While unstructured data may seem chaotic, advancements in artificial intelligence and machine learning enable us to extract valuable insights from this data type. BigDataBigdata refers to vast volumes of information that exceed the processing capabilities of traditional databases.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data.
Both measurement data and ML inference outputs are exported at a frequency of once per hour to a Kinesis data stream, and they are delivered to Amazon S3 via Kinesis Data Firehose with a 1-minute buffer. The exported Amazon Monitron data is in JSON format. You can also view data by choosing Table data on the console.
This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration. Let’s unlock the power of ETL Tools for seamless data handling. Also Read: Top 10 DataScience tools for 2024. It is a process for moving and managing data from various sources to a central data warehouse.
Trends in Data Analytics career path Trends Key Information Market Size and Growth CAGR BigData Analytics Dealing with vast datasets efficiently. Cloud-based Data Analytics Utilising cloud platforms for scalable analysis. billion 28% AI-Powered Data Analytics Transformation in decision-making speed.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks. MongoDB, developed by MongoDB Inc.,
Network software facilitates data communication, and application software interacts with the DBMS to perform specific tasks. Data The core of the system. It includes the database itself, which is a collection of interrelated data. Metadata, or data about data, describes the database’s structure and organisation.
Data Transparency Data Transparency is the pillar that ensures data is accessible and understandable to all stakeholders within an organization. This involves creating data dictionaries, documentation, and metadata. It provides clear insights into the data’s structure, meaning, and usage.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
They provide flexibility in data models and can scale horizontally to manage large volumes of data. NoSQL is well-suited for bigdata applications and real-time analytics, allowing organisations to adapt to rapidly changing data landscapes. Examples include MongoDB, Cassandra, and Redis. billion active users.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content