This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction to ETLETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build BigData.
This article was published as a part of the DataScience Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
This article was published as a part of the DataScience Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
Ahead of AI & BigData Expo Europe , Han Heloir, EMEA gen AI senior solutions architect at MongoDB , discusses the future of AI-powered applications and the role of scalable databases in supporting generative AI and enhancing business processes. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
DataScience You heard this term most of the time all over the internet, as well this is the most concerning topic for newbies who want to enter the world of data but don’t know the actual meaning of it. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ DataScience ’.
AI and machine learning (ML) models are incredibly effective at doing this but are complex to build and require datascience expertise. AN: What will Twilio be sharing with the audience at this year’s AI & BigData Expo Europe? HT: Twilio Segment is excited to be taking part in AI & BigData Expo Europe in 2023!
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
Learning these tools is crucial for building scalable data pipelines. offers DataScience courses covering these tools with a job guarantee for career growth. Introduction Imagine a world where data is a messy jungle, and we need smart tools to turn it into useful insights.
Automation has been a key trend in the past few years and that ranges from the design to building of a data warehouse to loading and maintaining, all of that can be automated. So pretty much what is available to a developer or data scientist who is working with the open source libraries and going through their own datascience journey.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use bigdata to make critical business decisions. However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Enter data warehousing!
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
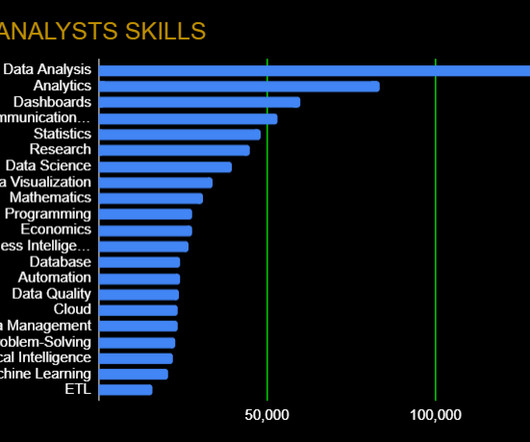
As the sibling of datascience, data analytics is still a hot field that garners significant interest. Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently.
Data Analytics in the Age of AI, When to Use RAG, Examples of Data Visualization with D3 and Vega, and ODSC East Selling Out Soon Data Analytics in the Age of AI Let’s explore the multifaceted ways in which AI is revolutionizing data analytics, making it more accessible, efficient, and insightful than ever before.
But, the amount of data companies must manage is growing at a staggering rate. Research analyst firm Statista forecasts global data creation will hit 180 zettabytes by 2025. In our discussion, we cover the genesis of the HPCC Systems data lake platform and what makes it different from other bigdata solutions currently available.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
IBM merged the critical capabilities of the vendor into its more contemporary Watson Studio running on the IBM Cloud Pak for Data platform as it continues to innovate. The platform makes collaborative datascience better for corporate users and simplifies predictive analytics for professional data scientists.
Data Quality: Without proper governance, data quality can become an issue. Performance: Query performance can be slower compared to optimized data stores. Business Applications: BigData Analytics : Supporting advanced analytics, machine learning, and artificial intelligence applications.
About the authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. He collaborates closely with enterprise customers building modern data platforms, generative AI applications, and MLOps.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring data quality and integrity.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
Data scientists can explore, experiment, and derive valuable insights without the constraints of a predefined structure. This capability empowers organizations to uncover hidden patterns, trends, and correlations in their data, leading to more informed decision-making. What Is a Data Warehouse? What is meant by Data Lake?
11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in DataScience and Machine Learning (ML) professions can be a lot different from the expectation of it. A popular focus of a majority of DataScience courses, degrees, and online competitions is on creating a model that has the highest accuracy or best fit.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks. MongoDB, developed by MongoDB Inc.,
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. About the authors Anchit Gupta is a Senior Product Manager for Amazon SageMaker Studio.
In my 7 years of DataScience journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. A lot of you who are already in the datascience field must be familiar with BigQuery and its advantages.
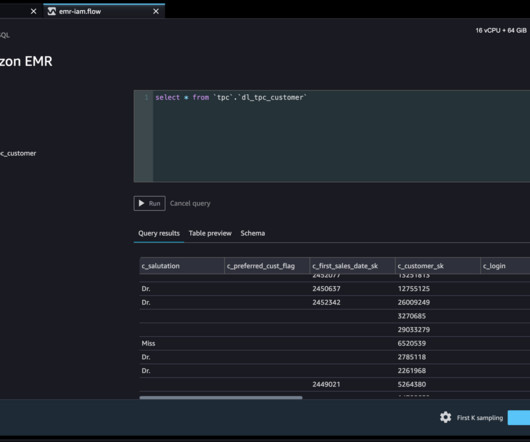
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks. Isha Dua is a Senior Solutions Architect based in the San Francisco Bay Area.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
About the Authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. He collaborates closely with enterprise customers building modern data platforms, generative AI applications, and MLOps.
Read Blogs: Crucial Statistics Interview Questions for DataScience Success. MongoDB is a NoSQL database that handles large-scale data and modern application requirements. Unlike traditional relational databases, MongoDB stores data in flexible, JSON-like documents, allowing for dynamic schemas. What is MongoDB?
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, bigdata, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
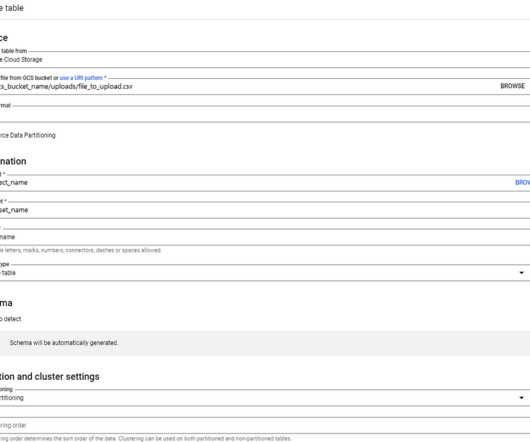
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content