This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise streaming analytics firm Streambased aims to help organisations extract impactful business insights from these continuous flows of operational event data. In an interview at the recent AI & BigData Expo , Streambased founder and CEO Tom Scott outlined the company’s approach to enabling advanced analytics on streaming data.
They must demonstrate tangible ROI from AI investments while navigating challenges around dataquality and regulatory uncertainty. After all, isnt ensuring strong data governance a core principle that the EU AI Act is built upon? To adapt, companies must prioritise strengthening their approach to dataquality.
Ahead of AI & BigData Expo North America – where the company will showcase its expertise – Chuck Ros , Industry Success Director at SoftServe, provided valuable insights into the company’s AI initiatives, the challenges faced, and its future strategy for leveraging this powerful technology. .
Its not a choice between better data or better models. The future of AI demands both, but it starts with the data. Why DataQuality Matters More Than Ever According to one survey, 48% of businesses use bigdata , but a much lower number manage to use it successfully. Why is this the case?
Addressing this gap will require a multi-faceted approach including grappling with issues related to dataquality and ensuring that AI systems are built on reliable, unbiased, and representative datasets. Companies have struggled with dataquality and data hygiene.
This wouldn’t be possible without forward-thinking customers like SSE Renewables who are willing to go on the journey with us,” explained Allen. See also: Hugging Face is launching an open robotics project Want to learn more about AI and bigdata from industry leaders?
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party bigdata sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
Introduction Are you struggling to decide between data-driven practices and AI-driven strategies for your business? Besides, there is a balance between the precision of traditional data analysis and the innovative potential of explainable artificial intelligence.
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
Introduction: The Reality of Machine Learning Consider a healthcare organisation that implemented a Machine Learning model to predict patient outcomes based on historical data. However, once deployed in a real-world setting, its performance plummeted due to dataquality issues and unforeseen biases.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance.
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. Databricks Databricks is a cloud-native platform for bigdata processing, machine learning, and analytics built using the Data Lakehouse architecture.
Regulatory compliance By integrating the extracted insights and recommendations into clinical trial management systems and EHRs, this approach facilitates compliance with regulatory requirements for data capture, adverse event reporting, and trial monitoring. He helps customers implement bigdata, machine learning, and analytics solutions.
Transparency and explainability : Making sure that AI systems are transparent, explainable, and accountable. It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle.
It involves breaking down the data into smaller chunks that can be processed in parallel across multiple nodes, and then combining the results of those processing tasks to produce a final output. Batch Processing Design Pattern The batch Processing Design Pattern is commonly used for processing large amounts of data in batches.
Data Management and Preprocessing for Accurate Predictions DataQuality is Paramount: The foundation of robust ML in demand forecasting lies in high-qualitydata. Retailers must ensure data is clean, consistent, and free from anomalies. Consistently review and purify data to uphold its accuracy.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
We also detail the steps that data scientists can take to configure the data flow, analyze the dataquality, and add data transformations. Finally, we show how to export the data flow and train a model using SageMaker Autopilot. Data Wrangler creates the report from the sampled data.
Taken together, this explains the poor market adoption of traditional MDM (Master Data Management) solutions. In addition, as new data is added, or data changes, the AI can surface instances where it is struggling to confidently make decisions (“low confidence matches”) and ask the human for input.
The batch inference pipeline includes steps for checking dataquality against a baseline created by the training pipeline, as well as model quality (model performance) if ground truth labels are available. If the batch inference pipeline discovers dataquality issues, it will notify the responsible data scientist via Amazon SNS.
Step 3: Load and process the PDF data For this blog, we will use a PDF file to perform the QnA on it. We’ve selected a research paper titled “DEEP LEARNING APPLICATIONS AND CHALLENGES IN BIGDATA ANALYTICS,” which can be accessed at the following link: [link] Please download the PDF and place it in your working directory.
Image from "BigData Analytics Methods" by Peter Ghavami Here are some critical contributions of data scientists and machine learning engineers in health informatics: Data Analysis and Visualization: Data scientists and machine learning engineers are skilled in analyzing large, complex healthcare datasets.
While unstructured data may seem chaotic, advancements in artificial intelligence and machine learning enable us to extract valuable insights from this data type. BigDataBigdata refers to vast volumes of information that exceed the processing capabilities of traditional databases.
The following are some critical challenges in the field: a) Data Integration: With the advent of high-throughput technologies, enormous volumes of biological data are being generated from diverse sources. Developing methods for model interpretability and explainability is an active area of research in bioinformatics.
Diagnostic Analytics Diagnostic analytics goes a step further by explaining why certain events occurred. It uses data mining , correlations, and statistical analyses to investigate the causes behind past outcomes. Organisations that harness BigData can gain comprehensive insights into customer preferences and market trends.
Knowledge of Cloud Computing and BigData Tools As complex Machine Learning (ML) models grow, robust infrastructure for large datasets and intensive computations becomes increasingly important. BigData Tools Integration Bigdata tools like Apache Spark and Hadoop are vital for managing and processing massive datasets.
The Tangent Information Modeler, Time Series Modeling Reinvented Philip Wauters | Customer Success Manager and Value Engineer | Tangent Works Existing techniques for modeling time series data face limitations in scalability, agility, explainability, and accuracy.
Top 50+ Interview Questions for Data Analysts Technical Questions SQL Queries What is SQL, and why is it necessary for data analysis? SQL stands for Structured Query Language, essential for querying and manipulating data stored in relational databases. Data Visualisation What are the fundamental principles of data visualisation?
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. Compute, bigdata, large commoditized models—all important stages.
Kishore will then double click into some of the opportunities we find here at Capital One, and Bayan will finish us off with a lean into one of our open-source solutions that really is an important contribution to our data-centric AI community. Compute, bigdata, large commoditized models—all important stages.
But some of these queries are still recurrent and haven’t been explained well. More specifically, embeddings enable neural networks to consume training data in formats that allow extracting features from the data, which is particularly important in tasks such as natural language processing (NLP) or image recognition.
Robust data management is another critical element. Establishing strong information governance frameworks ensures dataquality, security and regulatory compliance. Transparent, explainable AI models are necessary for informed decision-making. is currently no universally accepted framework for coding SDOH data.
She has innovated and delivered several product lines and services specializing in distributed systems, cloud computing, bigdata, machine learning and security. Can you explain the concept of ‘data democracy' in the context of today's AI-driven business environment?
The benefits of this solution are: You can flexibly achieve data cleaning, sanitizing, and dataquality management in addition to chunking and embedding. You can build and manage an incremental data pipeline to update embeddings on Vectorstore at scale. You can choose a wide variety of embedding models.
Unified model governance architecture ML governance enforces the ethical, legal, and efficient use of ML systems by addressing concerns like bias, transparency, explainability, and accountability. Prepare the data to build your model training pipeline. The Amazon DataZone project ID is captured in the Documentation section.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































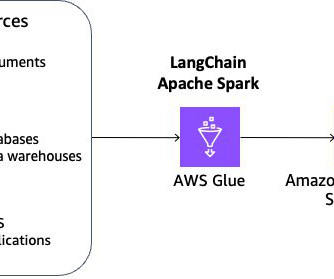







Let's personalize your content