This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
Managing BigData effectively helps companies optimise strategies, improve customer experience, and gain a competitive edge in todays data-driven world. Introduction BigData is growing faster than ever, shaping how businesses and industries operate. In 2023, the global BigData market was worth $327.26
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, data lakes, and datascience teams, and maintaining compliance with relevant financial regulations.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
True dataquality simplification requires transformation of both code and data, because the two are inextricably linked. Code sprawl and data siloing both imply bad habits that should be the exception, rather than the norm.
These organizations are shaping the future of the AI and datascience industries with their innovative products and services. These tools are designed to help companies derive insights from bigdata. Making Data Observable Bigeye The quality of the data powering your machine learning algorithms should not be a mystery.
Learning these tools is crucial for building scalable data pipelines. offers DataScience courses covering these tools with a job guarantee for career growth. Introduction Imagine a world where data is a messy jungle, and we need smart tools to turn it into useful insights.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: The healthcare industry is undergoing a data-driven revolution. DataScience is analyzing vast amounts of patient information to predict diseases before they strike, personalize treatment plans based on individual needs, and streamline healthcare operations. quintillion bytes of data each year [source: IBM].
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
But before AI/ML can contribute to enterprise-level transformation, organizations must first address the problems with the integrity of the data driving AI/ML outcomes. The truth is, companies need trusted data, not just bigdata. That’s why any discussion about AI/ML is also a discussion about data integrity.
In this blog, we are going to unfold the two key aspects of data management that is Data Observability and DataQuality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. What initially attracted you to computer science? What we have done is we have actually created this configuration where you are able to pick from a large list of options.
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use bigdata to make critical business decisions. However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Enter data warehousing!
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
DataScience helps businesses uncover valuable insights and make informed decisions. Programming for DataScience enables Data Scientists to analyze vast amounts of data and extract meaningful information. 8 Most Used Programming Languages for DataScience 1.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
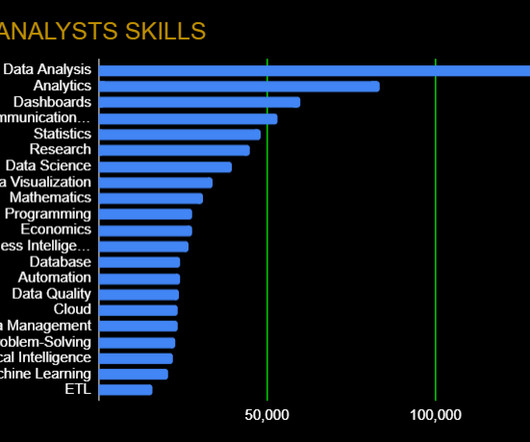
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
To quickly explore the loan data, choose Get data insights and select the loan_status target column and Classification problem type. The generated DataQuality and Insight report provides key statistics, visualizations, and feature importance analyses. Now you have a balanced target column. Huong Nguyen is a Sr.
Artificial Intelligence (AI) stands at the forefront of transforming data governance strategies, offering innovative solutions that enhance data integrity and security. In this post, let’s understand the growing role of AI in data governance, making it more dynamic, efficient, and secure. You can connect with him on LinkedIn.
As the sibling of datascience, data analytics is still a hot field that garners significant interest. Companies have plenty of data at their disposal and are looking for people who can make sense of it and make deductions quickly and efficiently.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to datascience. Data Wrangler creates the report from the sampled data.
Join us in the city of Boston on April 24th for a full day of talks on a wide range of topics, including Data Engineering, Machine Learning, Cloud Data Services, BigData Services, Data Pipelines and Integration, Monitoring and Management, DataQuality and Governance, and Data Exploration.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring dataquality and integrity.
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Runs are executions of some piece of datascience code and record metadata and generated artifacts.
Step 3: Load and process the PDF data For this blog, we will use a PDF file to perform the QnA on it. We’ve selected a research paper titled “DEEP LEARNING APPLICATIONS AND CHALLENGES IN BIGDATA ANALYTICS,” which can be accessed at the following link: [link] Please download the PDF and place it in your working directory.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a datascience development account (which has more controls than a typical application development account). The following figure depicts a successful run of the training pipeline.
Data Engineering plays a critical role in enabling organizations to efficiently collect, store, process, and analyze large volumes of data. It is a field of expertise within the broader domain of data management and DataScience. Best Data Engineering Books for Beginners 1.
Hadoop has become a highly familiar term because of the advent of bigdata in the digital world and establishing its position successfully. The technological development through BigData has been able to change the approach of data analysis vehemently. It offers several advantages for handling bigdata effectively.
Revolutionizing Healthcare through DataScience and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating datascience, machine learning, and information technology.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. The right tool can significantly enhance efficiency, scalability, and dataquality.
Such growth makes it difficult for many enterprises to leverage bigdata; they end up spending valuable time and resources just trying to manage data and less time analyzing it. What are the big differentiators between HPCC Systems and other bigdata tools? Spark is indeed a popular bigdata tool.
HPCC Systems — The Kit and Kaboodle for BigData and DataScience Bob Foreman | Software Engineering Lead | LexisNexis/HPCC Join this session to learn how ECL can help you create powerful data queries through a comprehensive and dedicated data lake platform.
Cons: Complexity: Managing and securing a data lake involves intricate tasks that require careful planning and execution. DataQuality: Without proper governance, dataquality can become an issue. Performance: Query performance can be slower compared to optimized data stores.
See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge", These are key files calculated from raw data used as a baseline.
Look for Anomalies During Training Anomaly detection or monitoring data for suspicious patterns and content can save precious time and costly AI and ML model retraining. Data training can be laborious, but ensuring the dataquality used in training systems can be a worthwhile investment for organizations.
For example, retailers could analyze and reveal trends much faster with a bigdata platform. It also can ensure they retain quality details since they don’t have to limit how much they collect. Quality Most retailers have dealt with irrelevant results even when using automatic processing systems like AI.
Transform and monitor – Perform batch inference and set up dataquality with model monitoring to have a baseline dataset suggestion. transform-monitor.ipynb – This notebook is the third step in our workflow and takes the base BERT model and runs a SageMaker batch transform job, while also setting up dataquality with model monitoring.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. Let’s unlock the power of ETL Tools for seamless data handling.
In my 7 years of DataScience journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. A lot of you who are already in the datascience field must be familiar with BigQuery and its advantages.
Bioinformatics: A Haven for Data Scientists and Machine Learning Engineers: Bioinformatics offers an unparalleled opportunity for data scientists and machine learning engineers to apply their expertise in solving complex biological problems. We’re committed to supporting and inspiring developers and engineers from all walks of life.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content