This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. First, we explore the option of in-context learning, where the LLM generates the requested metadata without documentation.
When we talk about dataintegrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. In short, yes.
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use bigdata to make critical business decisions. However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Enter data warehousing!
To maximize the value of their AI initiatives, organizations must maintain dataintegrity throughout its lifecycle. Managing this level of oversight requires adept handling of large volumes of data. Just as aircraft, crew and passengers are scrutinized, data governance maintains dataintegrity and prevents misuse or mishandling.
They’re built on machine learning algorithms that create outputs based on an organization’s data or other third-party bigdata sources. Sometimes, these outputs are biased because the data used to train the model was incomplete or inaccurate in some way.
Summary: This article provides a comprehensive guide on BigData interview questions, covering beginner to advanced topics. Introduction BigData continues transforming industries, making it a vital asset in 2025. The global BigData Analytics market, valued at $307.51 What is BigData?
Summary: HDFS in BigData uses distributed storage and replication to manage massive datasets efficiently. By co-locating data and computations, HDFS delivers high throughput, enabling advanced analytics and driving data-driven insights across various industries. It fosters reliability. between 2024 and 2030.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
As a result, it’s easier to find problems with data quality, inconsistencies, and outliers in the dataset. Metadata analysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables. The 18 best data profiling tools are listed below.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Extraction of relevant data points for electronic health records (EHRs) and clinical trial databases. Dataintegration and reporting The extracted insights and recommendations are integrated into the relevant clinical trial management systems, EHRs, and reporting mechanisms.
Summary: Choosing the right ETL tool is crucial for seamless dataintegration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
An integrated model factory to develop, deploy, and monitor models in one place using your preferred tools and languages. Databricks Databricks is a cloud-native platform for bigdata processing, machine learning, and analytics built using the Data Lakehouse architecture. Is it fast and reliable enough for your workflow?
Among those algorithms, deep/neural networks are more suitable for e-commerce forecasting problems as they accept item metadata features, forward-looking features for campaign and marketing activities, and – most importantly – related time series features. He has worked on Personalization and Supply Chain related projects.
Its in-memory processing helps to ensure that data is ready for quick analysis and reporting, enabling real-time what-if scenarios and reports without lag. Our solution handles massive multidimensional cubes seamlessly, enabling you to maintain a complete view of your data without sacrificing performance or dataintegrity.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time dataintegration. What is Apache NiFi?
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. Tanvi Singhal is a Data Scientist within AWS Professional Services.
They enhance dataintegrity, security, and accessibility while providing tools for efficient data management and retrieval. A Database Management System (DBMS) is specialised software designed to efficiently manage and organise data within a computer system. Indices are data structures optimised for rapid data retrieval.
Data lakes are able to handle a diverse range of data types. From images, videos, text, and even sensor data. Then, there’s dataintegration. A data lake can also act as a central hub for integratingdata from various sources and systems within an organization.
Access Transparency Users experience seamless access to files, as the system hides the complexities of how data distributed across various servers. DFS optimises data retrieval through caching mechanisms and load balancing across nodes, ensuring that AI applications can quickly access the latest information.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
These include the database engine for executing queries, the query processor for interpreting SQL commands, the storage manager for handling physical data storage, and the transaction manager for ensuring dataintegrity through ACID properties. Data Independence: Changes in database structure do not affect application programs.
In addition, it also defines the framework wherein it is decided what action needs to be taken on certain data. And so, a company dealing in BigData Analysis needs to follow stringent Data Governance policies. It can include data refresh cadences, PII limitations, regulatory data regulations, or even data access.
The primary purpose of a DBMS is to provide a systematic way to manage large amounts of data, ensuring that it is organised, accessible, and secure. By employing a DBMS, organisations can maintain dataintegrity, reduce redundancy, and streamline data operations, enabling more informed decision-making.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks. MongoDB, developed by MongoDB Inc.,
Data scientists can explore, experiment, and derive valuable insights without the constraints of a predefined structure. This capability empowers organizations to uncover hidden patterns, trends, and correlations in their data, leading to more informed decision-making. What Is Data Lake Architecture?
While unstructured data may seem chaotic, advancements in artificial intelligence and machine learning enable us to extract valuable insights from this data type. BigDataBigdata refers to vast volumes of information that exceed the processing capabilities of traditional databases.
Online Processing: this type of data processing involves managing transactional data in real time and focuses on handling individual transaction. The systems are designed to ensure dataintegrity, concurrency and quick response times for enabling interactive user transactions. The Data Science courses provided by Pickl.AI
Data Transparency Data Transparency is the pillar that ensures data is accessible and understandable to all stakeholders within an organization. This involves creating data dictionaries, documentation, and metadata. It provides clear insights into the data’s structure, meaning, and usage.
How generative AI troubleshooting for Spark works For Spark jobs, the troubleshooting feature analyzes job metadata, metrics and logs associated with the error signature of your job to generates a comprehensive root cause analysis. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, bigdata, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
These are subject-specific subsets of the data warehouse, catering to the specific needs of departments like marketing or sales. They offer a focused selection of data, allowing for faster analysis tailored to departmental goals. Metadata This acts like the data dictionary, providing crucial information about the data itself.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















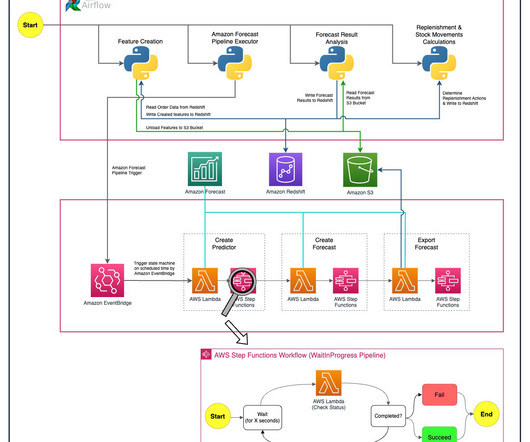






















Let's personalize your content