This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Companies are presented with significant opportunities to innovate and address the challenges associated with handling and processing the large volumes of data generated by AI. Organizations generate and collect large amounts of information from various sources such as social media, customer interactions, IoT sensors and enterprise systems.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use bigdata to make critical business decisions. However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Enter data warehousing!
Summary: BigData as a Service (BDaaS) offers organisations scalable, cost-effective solutions for managing and analysing vast data volumes. By outsourcing BigData functionalities, businesses can focus on deriving insights, improving decision-making, and driving innovation while overcoming infrastructure complexities.
Choosing between them depends on your systems needsRabbitMQ is best for workflows, while Kafka is ideal for event-driven architectures and bigdata processing. They act as a middleman, helping different systems exchange information smoothly. Kafka excels in real-time data streaming and scalability.
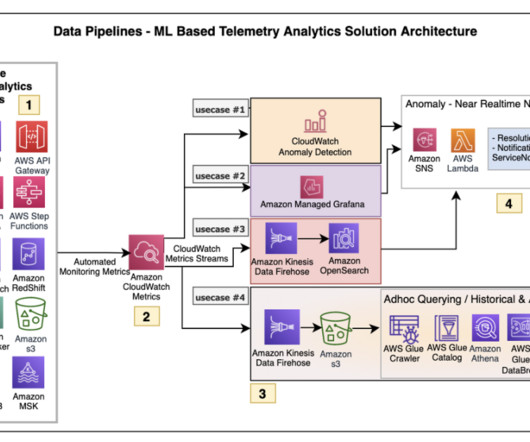
This is particularly useful for tracking access to sensitive resources such as personally identifiable information (PII), model updates, and other critical activities, enabling enterprises to maintain a robust audit trail and compliance. For more information, see Monitor Amazon Bedrock with Amazon CloudWatch.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
Summary: Apache NiFi is a powerful open-source dataingestion platform design to automate data flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation.
By exploring these challenges, organizations can recognize the importance of real-time forecasting and explore innovative solutions to overcome these hurdles, enabling them to stay competitive, make informed decisions, and thrive in today’s fast-paced business environment. For more information, refer to the following resources.
The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components. For ingestion, data can be updated in an offline mode, whereas inference needs to happen in milliseconds.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Thus, making it easier for analysts and data scientists to leverage their SQL skills for BigData analysis.
The banking dataset contains information about bank clients such as age, job, marital status, education, credit default status, and details about the marketing campaign contacts like communication type, duration, number of contacts, and outcome of the previous campaign. A new data flow is created on the Data Wrangler console.
It initiates the collection, indexing, and analysis of machine-generated data in real-time. It helps harness the power of bigdata and turn it into actionable intelligence. Moreover, it allows users to ingestdata from different sources. Additionally, Splunk can process and index massive volumes of data.
This article explores how data engineering can improve Customer 360 initiatives for AWS data engineering , bigdata engineering, and data analytics companies. Doing so enables companies to personalise their offerings, enhancing client satisfaction and helping make more informed decision-making processes.
In the later part of this article, we will discuss its importance and how we can use machine learning for streaming data analysis with the help of a hands-on example. What is streaming data? A streaming data pipeline is an enhanced version which is able to handle millions of events in real-time at scale.
Data scientists could be your key to unlocking the potential of the Information Revolution—but what do data scientists do? What Do Data Scientists Do? Data scientists drive business outcomes. Many implement machine learning and artificial intelligence to tackle challenges in the age of BigData.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
Unified Data Services: Azure Synapse Analytics combines bigdata and data warehousing, offering a unified analytics experience. Azure’s global network of data centres ensures high availability and performance, making it a powerful platform for Data Scientists to leverage for diverse data-driven projects.
Data contains information, and information can be used to predict future behaviors, from the buying habits of customers to securities returns. The financial services industry (FSI) is no exception to this, and is a well-established producer and consumer of data and analytics.
In addition, it also defines the framework wherein it is decided what action needs to be taken on certain data. And so, a company dealing in BigData Analysis needs to follow stringent Data Governance policies. Enhances Transparency Transparency while documenting data is important. Wrapping it up !!!
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
In the Account info section, provide the following information: For Select how to share , select Organization node. For options 2, 3, and 4, the SageMaker Projects Portfolio provides project templates to run ML experiment pipelines, steps including dataingestion, model training, and registering the model in the model registry.
This is what data processing pipelines do for you. Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions. No built-in data quality functionality. No expert support.
1 DataIngestion (e.g., Apache Kafka, Amazon Kinesis) 2 Data Preprocessing (e.g., The next section delves into these architectural patterns, exploring how they are leveraged in machine learning pipelines to streamline dataingestion, processing, model training, and deployment.
Data flow Here is an example of this data flow for an Agent Creator pipeline that involves dataingestion, preprocessing, and vectorization using Chunker and Embedding Snaps. This data was then integrated into Salesforce as a real-time feed of market insights.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. For more information, see Zeta Global’s home page. He is passionate about machine learning engineering, distributed systems, and big-data technologies.
AWS Data Exchange: Access third-party datasets directly within AWS. Data & ML/LLM Ops on AWS Amazon SageMaker: Comprehensive ML service to build, train, and deploy models at scale. Amazon EMR: Managed bigdata service to process large datasets quickly.
AWS Data Exchange: Access third-party datasets directly within AWS. Data & ML/LLM Ops on AWS Amazon SageMaker: Comprehensive ML service to build, train, and deploy models at scale. Amazon EMR: Managed bigdata service to process large datasets quickly.
Data collection – Updated shop prices lead to updated demand. The new information is used to enhance the training sets used in Step 1 for forecasting discounts. When inference data is ingested on Amazon S3, EventBridge automatically runs the inference pipeline. The following diagram illustrates this workflow.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content