This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The managed service offers a simple and cost-effective method of categorizing and managing bigdata in an enterprise. It provides organizations with […].
This technology employs contextual, behavioural, and categorical detection models, achieving an impressive 90 percent accuracy rate. Photo by Markus Spiske on Unsplash ) See also: MyShell releases OpenVoice voice cloning AI Want to learn more about AI and bigdata from industry leaders?
It creates a trove of historical data that can be retrieved, analyzed, and reported to provide insight or predictive analysis into an organization’s performance and operations. Data warehousing solutions drive business efficiency, build future analysis and predictions, enhance productivity, and improve business success.
medium.com Similarity-driven adversarial testing of neural networks As similarity is one of the key components of human cognition and categorization, the approach presents a shift towards a more human-centered security testing of deep neural networks. Explore its AI-powered versatility. Explore its AI-powered versatility.
You spent over 7 years at Google, where you helped to build and lead teams working on strategy, operations, bigdata and machine learning. We figured out how to use all the bigdata we had on how advertisers used our products to help sales teams. What was your favorite project and what did you learn from this experience?
It offers both open-source and enterprise/paid versions and facilitates bigdata management. Key Features: Seamless integration with cloud and on-premise environments, extensive data quality, and governance tools. Pros: Scalable, strong data governance features, support for bigdata.
It offers both open-source and enterprise/paid versions and facilitates bigdata management. Key Features: Seamless integration with cloud and on-premise environments, extensive data quality, and governance tools. Pros: Scalable, strong data governance features, support for bigdata. Visit Hevo Data → 7.
ELT Pipelines: Typically used for bigdata, these pipelines extract data, load it into data warehouses or lakes, and then transform it. It is suitable for distributed and scalable large-scale data processing, providing quick big-data query and analysis capabilities.
To find the relationship between a numeric variable (like age or income) and a categorical variable (like gender or education level), we first assign numeric values to the categories in a way that allows them to best predict the numeric variable. Linear categorical to categorical correlation is not supported.
Davidson’s upcoming paper, “Spatial Relation Categorization in Infants and Deep Neural Networks,” co-authored with CDS Assistant Professor of Psychology and Data Science Brenden Lake and former CDS Research Scientist Emin Orhan , is set for publication in Cognition in early 2024.
Data extraction Once you’ve assigned numerical values, you will apply one or more text-mining techniques to the structured data to extract insights from social media data. It also automates tasks like information extraction and content categorization. positive, negative or neutral).
Fortunately, advancements in data analytics and technology are transforming the way organizations approach compliance, offering solutions to streamline processes and ensure adherence to regulatory standards. One of the key drivers of this transformation is the utilization of bigdata analytics.
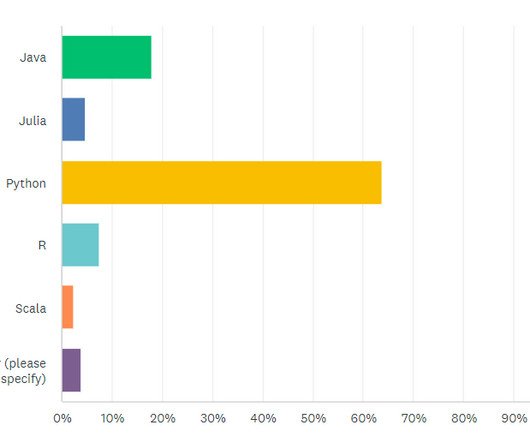
Bigdata analytics is evergreen, and as more companies use bigdata it only makes sense that practitioners are interested in analyzing data in-house. No field truly dominated over the others, so it’s safe to say that there’s a good amount of interest across the board. However, the top three still make sense.
Artificial intelligence and machine learning are fundamentally transforming how industries operate, especially with regard to automation and bigdata processing. Workers take pictures of the pile and the app meticulously categorizes them. In 2022, China leveraged Alibaba Cloud’s AI to make waste incineration more efficient.
These advancements rely on cyber-physical systems supported by bigdata and computational power, enabling tasks such as radiology interpretation to surpass human performance. However, the challenge lies in integrating and explaining multimodal data from various sources, such as sensors and images.
Machine translation, summarization, ticket categorization, and spell-checking are among the examples. LLMs are able to gain knowledge from bigdata, comprehend its context and entities, and respond to user inquiries. What are large language models used for?
Model risk : Risk categorization of the model version. He is passionate about building secure and scalable AI/ML and bigdata solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. Model stage : Stage where the model version is deployed.
By using machine learning algorithms and bigdata analytics, AI can uncover patterns, correlations and trends that might escape human analysts. Unlike traditional AI, which analyzes and categorizes existing content, generative AI can create new content tailored to individual customers.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging.
Next, we want to look for categoricaldata in our dataset. Data Wrangler has a built-in functionality to encode categoricaldata using both ordinal and one-hot encodings. Looking at our dataset, we can see that the TERM , HOME_OWNERSHIP , and PURPOSE columns all appear to be categorical in nature.
BigData and a boatload of data are not the same. Check out the case where we helped a large company deal with their boatload-of-accounting-data problem with a dedicated BigData solution. This means processing about 75,000 incoming invoices a year that all need to be evaluated and categorized.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring data quality.
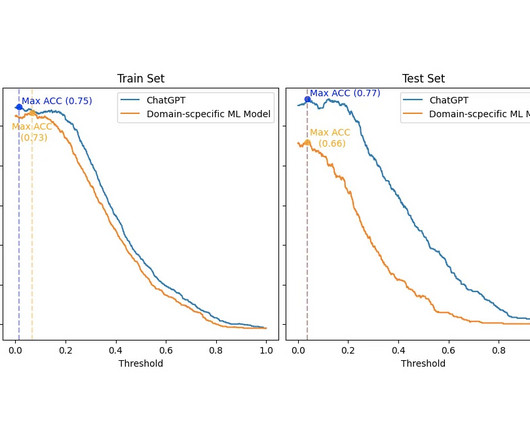
So, to make a viable comparison, I had to: Categorize the dataset scores into Positive , Neutral , or Negative labels. This evaluation assesses how the accuracy (y-axis) changes regarding the threshold (x-axis) for categorizing the numeric Gold-Standard dataset for both models. First, I must be honest. Then, I made a confusion matrix.
Distributed training is a technique that allows for the parallel processing of large amounts of data across multiple machines or devices. By splitting the data and training multiple models in parallel, distributed training can significantly reduce training time and improve the performance of models on bigdata.
ML also helps businesses forecast and decrease customer churn (the rate at which a company loses customers), a widespread use of bigdata. For instance, email management automation tools such as Levity use ML to identify and categorize emails as they come in using text classification algorithms.
The identification of regularities in data can then be used to make predictions, categorize information, and improve decision-making processes. While explorative pattern recognition aims to identify data patterns in general, descriptive pattern recognition starts by categorizing the detected patterns.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
A sector that is currently being influenced by machine learning is the geospatial sector, through well-crafted algorithms that improve data analysis through mapping techniques such as image classification, object detection, spatial clustering, and predictive modeling, revolutionizing how we understand and interact with geographic information.
Here are the primary types: Logistic Regression Models: These models use historical data to predict the probability of default. Decision Trees and Random Forests: These models categorize borrowers based on various risk factors. BigData Analytics: Bigdata allows for more granular insights into borrower behaviour and market conditions.
However, this approach presents substantial limitations, as it frequently allows superficially relevant papers to be categorized as SDG-aligned, despite the lack of meaningful substantive contributions to actual SDG targets. For example, Phi-3.5-mini demonstrates minimal intersection with other models, indicating stricter filtering criteria.
Typically, microservices are categorized by their business capabilities (e.g., Bigdata analytics Serverless dramatically reduces the cost and complexity of writing and deploying code for data applications. Microservices applications often have their own stack that includes a database and database management model.
However, unsupervised learning has its own advantages, such as being more resistant to overfitting (the big challenge of Convolutional Neural Networks ) and better able to learn from complex bigdata, such as customer data or behavioral data without an inherent structure.
Best data pipeline tools: Apache Airflow | Source Categorization Open Source Batch data processing Pros Fully customizable and supports complex business use cases. Best data pipeline tools: Talend | Source Categorization Open Source Batch data processing Pros Apache license makes it free to use.
This scalability ensures that the algorithm remains reliable whether youre working on a single machine or a large-scale distributed system, making it suitable for real-world bigdata applications. Its design and implementation make it a go-to choice for beginners and seasoned Data Scientists.
Effective visualizations can lead to better decision-making, improved communication of ideas, and a deeper understanding of the underlying data. Key Takeaways Select visualizations that match your data: categorical or numerical for clarity. Adjust complexity and style based on your audience’s data familiarity.
LARs are a type of embedding that can be used to represent high-dimensional categoricaldata in a lower-dimensional continuous space. This makes it easier to learn the relationships between different items of data, such as posts, articles, and people. TypeChat replaces prompt engineering with schema engineering.
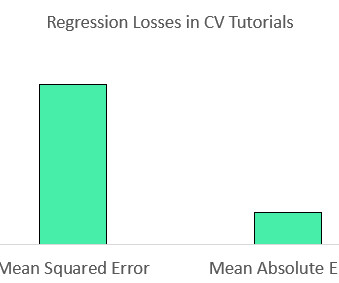
Source: Author We see that the sparse categorical cross entropy loss (also called softmax loss) was the most common. Both sparse categorical cross entropy and categorical cross entropy use the same loss function. The most obvious question is then, “which loss functions are being used in those image classification problems?”
Secure databases in the physical data center, bigdata platforms and the cloud. Stolen or compromised credentials, the most common type of breach, cost companies $150,000 more than other types of data breaches. Make sure they recognize phishing and other cybersecurity threats.
The solution for data quantity challenges in the retail industry lies in enhanced storage and management. Integrating software that can automatically categorize or process could solve the issue of being overwhelmed by information. For example, retailers could analyze and reveal trends much faster with a bigdata platform.
Timeline of data engineering — Created by the author using canva In this post, I will cover everything from the early days of data storage and relational databases to the emergence of bigdata, NoSQL databases, and distributed computing frameworks.
This blog equips you with the top interview questions and answers, categorized by difficulty level. Top DBMS Interview Questions and Answers (2024 Edition) The world runs on data, and at the heart of data management lies the Database Management System (DBMS). Summary Feeling unprepared for your DBMS interview?
Aggregation : Combining multiple data points into a single summary (e.g., Normalisation : Scaling data to fall within a specific range, often to standardise features in Machine Learning. Encoding : Converting categoricaldata into numerical values for better processing by algorithms. calculating averages).
It allows users to quickly and easily find the images they need without having to manually tag or categorize them. About the Authors Charalampos Grouzakis is a Data Scientist within AWS Professional Services. He has over 11 years of experience in developing and leading data science, machine learning, and bigdata initiatives.
Turi Create To add suggestions, object identification, picture classification, image similarity, or activity categorization to your app, you can be an expert in machine learning. It includes built-in streaming graphics to analyze your data and focuses on tasks rather than algorithms.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content