This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By pre-training on a large corpus of text with a masked language model and next-sentence prediction, BERT captures rich bidirectional contexts and has achieved state-of-the-art results on a wide array of NLP tasks. GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.
Examples of Generative AI: Text Generation: Models like OpenAIs GPT-4 can generate human-like text for chatbots, content creation, and more. Music Generation: AI models like OpenAIs Jukebox can compose original music in various styles. GPT, BERT) Image Generation (e.g., Explore text generation models like GPT and BERT.
Introduction Ever since the launch of Generative AI models like the GPT (Generative Pre-trained Transformers) models by OpenAI, especially ChatGPT, Google has always been on the verge to create a launch an AI Model similar to that.
OpenAI Embeddings Strengths: Comprehensive Training: OpenAI’s embeddings, including text and image embeddings, are trained on massive datasets. Limitations: High Compute Requirements: Utilizing OpenAI embeddings necessitates significant computational resources, which might only be feasible for some users.
LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). Some examples are OpenAI , Hugging Face , and Weights & Biases. OpenAI, an AI research company, offers various services and models, including GPT-4, DALL-E, CLIP, and DINOv2.
Creating embeddings for natural language usually involves using pre-trained models such as: GPT-3 and GPT-4 : OpenAI's GPT-3 (Generative Pre-trained Transformer 3) has been a monumental model in the NLP community with 175 billion parameters.
This is typically done using large language models like BERT or GPT. Point-E (OpenAI) Point-E, developed by OpenAI , is another notable text-to-3D generation model. The post How Text-to-3D AI Generation Works: Meta 3D Gen, OpenAI Shap-E and more appeared first on Unite.AI. This stage takes approximately 20 seconds.
Here, we will focus on enterprise-friendly choices like Azure OpenAI, AWS Bedrock, and open-source models from Hugging Face 🤗 It is essential to evaluate and identify the most suitable embedding model for your application in order to optimize accuracy, latency, storage, memory, and cost.
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. The Brain (LLM Core) At the core of every LLM-based agent lies its brain, typically represented by a pre-trained language model like GPT-3 or BERT.
Transformer-based language models, like BERT and T5, are adept at various tasks but struggle with infilling—generating text within a specific location while considering both preceding and succeeding contexts. While early models like BERT masked tokens randomly, later ones like T5 and BART showed improvements with contiguous masking.
It explains different embedding techniques, including Word2Vec, GloVe, BERT, and more, and details how to utilize embedding models from providers such as OpenAI, HuggingFace, and Gemini within LangChain.
Leveraging Large Language Models (LLMs) such as OpenAI’s GPT-3.5 Introduction In the fast-paced world of customer support efficiency and responsiveness are paramount. for project optimization in customer support introduces a unique perspective.
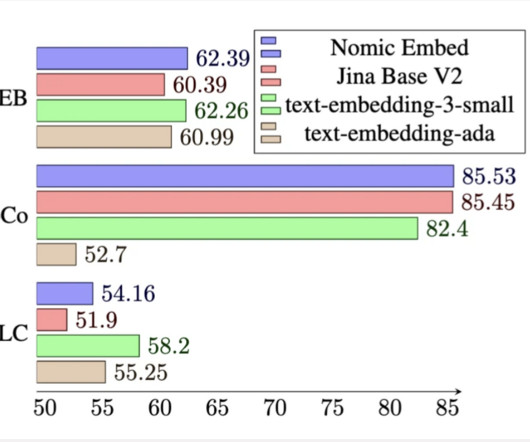
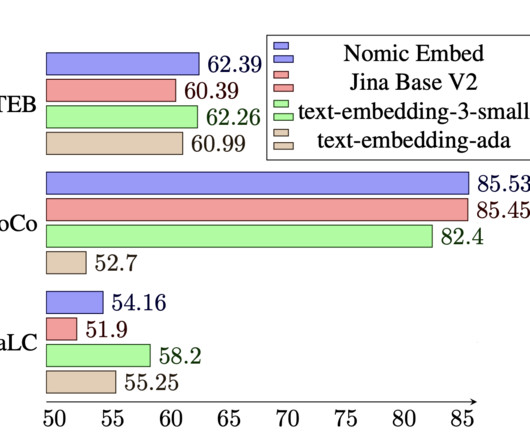
The existing popular models, including OpenAI’s text-embedding-ada-002, lack openness and auditability. It starts with training a BERT model with a context length of 2048 tokens, named nomic-bert-2048, with modifications inspired by MosaicBERT. Nomic Embed is built through a multi-stage contrastive learning pipeline.
Initially, a Masked Language Modeling Pretraining phase utilized resources like BooksCorpus and a Wikipedia dump from 2023, employing the bert-base-uncased tokenizer to create data chunks suited for long-context training. The journey to achieving such a feat involved meticulous stages of data preparation and model training.
Case Studies: Successful Implementations of Self-Reflective AI Systems Google’s BERT and Transformer models have significantly improved natural language understanding by employing self-reflective pre-training on extensive text data. Similarly, OpenAI's GPT series demonstrates the effectiveness of self-reflection in AI.
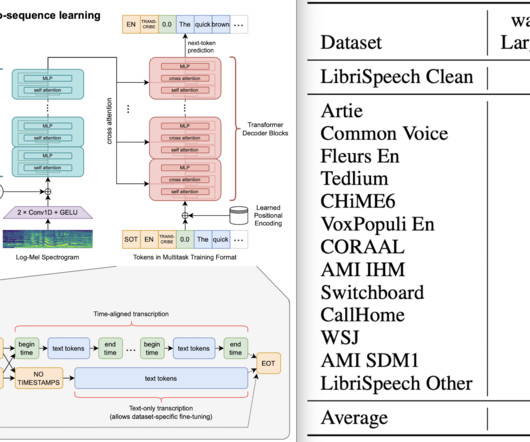
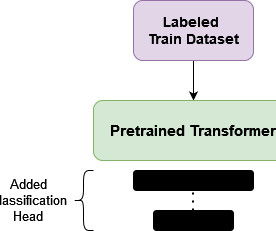
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
These models, such as OpenAI's GPT-4 and Google's BERT , are not just impressive technologies; they drive innovation and shape the future of how humans and machines work together. OpenAI's GPT-3 model undergoes rigorous auditing to address misinformation and bias, with continuous monitoring, human reviewers, and usage guidelines.
OpenAI Embeddings Strengths: Comprehensive Training: OpenAI’s embeddings, including text and image embeddings, are trained on massive datasets. Limitations: High Compute Requirements: Utilizing OpenAI embeddings necessitates significant computational resources, which might only be feasible for some users.
These tools, such as OpenAI's DALL-E , Google's Bard chatbot , and Microsoft's Azure OpenAI Service , empower users to generate content that resembles existing data. OpenAI's GPT-4 stands as a state-of-the-art generative language model, boasting an impressive over 1.7
GPT 3 and similar Large Language Models (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the Natural Language Processing (NLP) paradigm.
with: New OpenAI Whisper, Embeddings and Completions! Cutting-edge BGE and GTE text embedding models lead the MTEB leaderboard, surpassing even the renowned OpenAI text-embedding-ada-002. which has notably augmented the performance of models like BERT—we’re further integrating features to bolster model efficiency.
In this article, we will talk about another and one of the most impactful works published by Google, BERT (Bi-directional Encoder Representation from Transformers) BERT undoubtedly brought some major improvements in the NLP domain. The dependencies are Transformers, Semi-supervised Sequence Learning, ULMFit, OpenAI GPT, and ELMo.
(BigStock Image) Editor’s note: Four months after the release of its ChatGPT chatbot, OpenAI unveiled its latest artificial intelligence technology, GPT-4 , on Tuesday. All of these problems will be overcome in GPT-5 or in a subsequent version from OpenAI or a competitor.
Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication. link] The process can be categorized into three agents: Execution Agent : The heart of the system, this agent leverages OpenAI’s API for task processing. Below is a demonstration of the BabyAGI using this link.
In the case of BERT (Bidirectional Encoder Representations from Transformers), learning involves predicting randomly masked words (bidirectional) and sentence-order prediction. This is the process for specializing a general purpose model like OpenAI* GPT-4 into an application like ChatGPT* or GitHub* Copilot.
Models like OpenAI’s ChatGPT and Google Bard require enormous volumes of resources, including a lot of training data, substantial amounts of storage, intricate, deep learning frameworks, and enormous amounts of electricity. These versions offer flexibility in terms of applications, ranging from Mini with 4.4
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. One of the more popular and useful of the transformer architectures, Bidirectional Encoder Representations from Transformers (BERT), is a language representation model that was introduced in 2018.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
The quintessential examples for this distinction are: The BERT model, which stands for Bidirectional Encoder Representations from Transformers. This trend began with models like the original GPT and ELMo, which had millions of parameters, and progressed to models like BERT and GPT-2, with hundreds of millions of parameters.
OpenAI has been instrumental in developing revolutionary tools like the OpenAI Gym, designed for training reinforcement algorithms, and GPT-n models. One such model that has garnered considerable attention is OpenAI's ChatGPT , a shining exemplar in the realm of Large Language Models.
OpenAI's GPT series and almost all other LLMs currently are powered by transformers utilizing either encoder, decoder, or both architectures. An illustration of the pretraining process of MusicLM: SoundStream, w2v-BERT, and Mulan | Image source: here Moreover, MusicLM expands its capabilities by allowing melody conditioning.
As the course progresses, “Language Models and Transformer-based Generative Models” take center stage, shedding light on different language models, the Transformer architecture, and advanced models like GPT and BERT. Expert Creators : Developed by renowned professionals from OpenAI and DeepLearning.AI.
Soon to be followed by large general language models like BERT (Bidirectional Encoder Representations from Transformers). In hindsight, these companies might have been too early in their evolution, as they missed the boat by being early on what groundbreaking advances OpenAI brought to the world.
GPT-4 GPT-4 is OpenAI's latest (and largest) model. BERTBERT stands for Bidirectional Encoder Representations from Transformers, and it's a large language model by Google. BERT is an encoder-only Transformer model and is pre-trained on an extensive amount of unlabeled text from the internet.
Current methods in the field include keyword-based search engines and advanced neural network models like BERT and GPT. employs a variety of models, including Ollama’s Llama3, HuggingFace’s MiniLMEmbedder, Cohere’s Command R+, Google’s Gemini, and OpenAI’s GPT-4. Check out the release video!
You know, that thing OpenAI used to make GPT3.5 As an early adopter of the BERT models in 2017, I hadn’t exactly been convinced computers could interpret human language with similar granularity and contextuality as people do. Author(s): Tim Cvetko Originally published on Towards AI. into ChatGPT?
In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna. BERT excels in understanding context and generating contextually relevant representations for a given text.
Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data. Custom-trained models: Most organizations can’t produce or support AI without a strong partnership.
Libraries DRAGON is a new foundation model (improvement of BERT) that is pre-trained jointly from text and knowledge graphs for improved language, knowledge and reasoning capabilities. DRAGON can be used as a drop-in replacement for BERT. OpenAI-compatible APIs: Serve APIs that are compatible with OpenAI standards.
Many fields have used fine-tuning, but OpenAI’s InstructGPT is a particularly impressive and up-to-date example. By optimizing the probability over all possible orders of factorization, its autoregressive formulation surpasses BERT’s restrictions, allowing for acquiring knowledge in both directions.
Distinguished adaptations include the decoder-only Transformer, optimizing text generation processes in models like OpenAI’s GPT series. Moreover, hybrid models such as BERT and T5 combine various architectural strengths, enhancing language models’ efficiency and capability in understanding and generating nuanced text.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content