This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
This extensive training allows the embeddings to capture semantic meanings effectively, enabling advanced NLP tasks. Utility Functions: The library provides useful functions for similarity lookups and analogies, aiding in various NLP tasks. MultiLingual BERT is a versatile model designed to handle multilingual datasets effectively.
By Vatsal Saglani This article explores the creation of PDF2Pod, a NotebookLM clone that transforms PDF documents into engaging, multi-speaker podcasts. It also demonstrates how to store and retrieve embedded documents using vector stores and visualize embeddings for better understanding.
Language model pretraining has significantly advanced the field of Natural Language Processing (NLP) and Natural Language Understanding (NLU). Models like GPT, BERT, and PaLM are getting popular for all the good reasons. It aims to reduce a document to a manageable length while keeping the majority of its meaning.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
Take, for instance, word embeddings in natural language processing (NLP). Creating embeddings for natural language usually involves using pre-trained models such as: GPT-3 and GPT-4 : OpenAI's GPT-3 (Generative Pre-trained Transformer 3) has been a monumental model in the NLP community with 175 billion parameters.
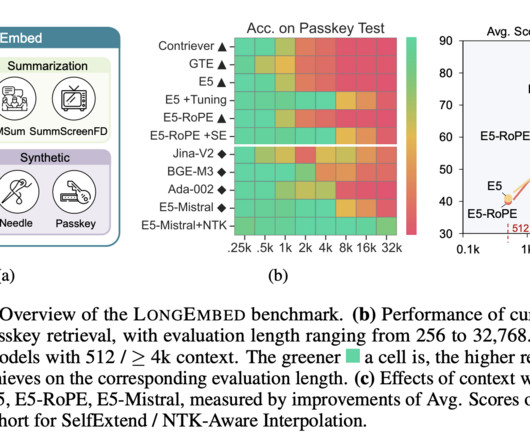
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval João Coelho, Bruno Martins, João Magalhães, Jamie Callan, Chenyan Xiong. link] The paper investigates positional biases when encoding long documents into a vector for similarity-based retrieval. ArXiv 2024. CSIRO Data61, University of Copenhagen.
Embedding models are fundamental tools in natural language processing (NLP), providing the backbone for applications like information retrieval and retrieval-augmented generation. This limitation restricts their use in scenarios demanding the analysis of extended documents, such as legal contracts or detailed academic reviews.
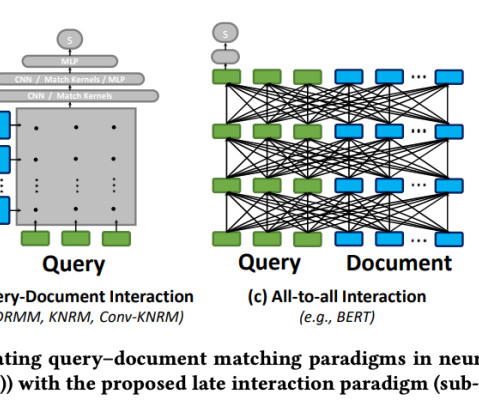
When it comes to natural language processing (NLP) and information retrieval, the ability to efficiently and accurately retrieve relevant information is paramount. Retrieval : The system queries a vector database or document collection to find information relevant to the user's query.
LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP). However, LLMs are also very different from other models.
Photo by adrianna geo on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.23.20 If you haven’t heard, we released the NLP Model Forge ? NLP Model Forge So… the NLP Model Forge, a collection of 1,400 NLP code snippets that you can seamlessly select to run inference in Colab!
The Eora MRIO (Multi-region input-output) dataset is a globally recognized spend-based emission factor set that documents the inter-sectoral transfers amongst 15.909 sectors across 190 countries. In recent years, remarkable strides have been achieved in crafting extensive foundation language models for natural language processing (NLP).
Natural Language Processing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. Traditional NLP methods like CNN, RNN, and LSTM have evolved with transformer architecture and large language models (LLMs) like GPT and BERT families, providing significant advancements in the field.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
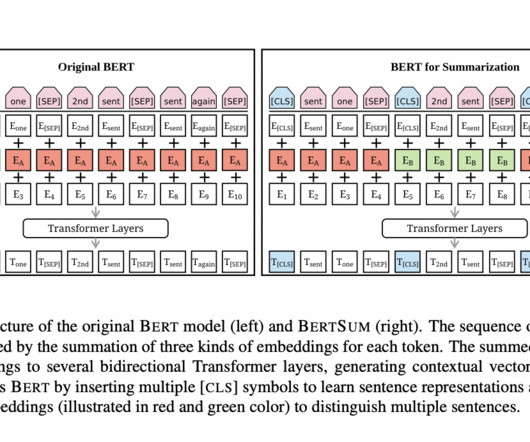
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Photo by Kunal Shinde on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 08.09.20 What is the state of NLP? For an overview of some tasks, see NLP Progress or our XTREME benchmark. In the next post, I will outline interesting research directions and opportunities in multilingual NLP.”
It’s also an area that stands to benefit most from automated or semi-automated machine learning (ML) and natural language processing (NLP) techniques. Semi) automated data extraction for SLRs through NLP Researchers can deploy a variety of ML and NLP techniques to help mitigate these challenges. This study by Bui et al.
While new tasks and models emerge so often for many application domains, the underlying documents being modeled stay mostly unaltered. Introduction Training and inference with large neural models are computationally expensive and time-consuming. In light of this, to improve the efficiency of future […].
John Snow Labs , the award-winning Healthcare AI and NLP company, announced the latest major release of its Spark NLP library – Spark NLP 5 – featuring the highly anticipated support for the ONNX runtime. State-of-the-Art Accuracy, 100% Open Source The Spark NLP Models Hub now includes over 500 ONYX-optimized models.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini.
But now, a computer can be taught to comprehend and process human language through Natural Language Processing (NLP), which was implemented, to make computers capable of understanding spoken and written language. This article will explain to you in detail about RoBERTa and if you do not know about BERT please click on the associated link.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
We’re using deepset/roberta-base-squad2 , which is: Based on RoBERTa architecture (a robustly optimized BERT approach) Fine-tuned on SQuAD 2.0 Useful Resources Hugging Face Transformers Documentation More about Question Answering Models SQuAD Dataset Information BeautifulSoup Documentation Here is the Colab Notebook.
This extensive training allows the embeddings to capture semantic meanings effectively, enabling advanced NLP tasks. Utility Functions: The library provides useful functions for similarity lookups and analogies, aiding in various NLP tasks. MultiLingual BERT is a versatile model designed to handle multilingual datasets effectively.
They are now capable of natural language processing ( NLP ), grasping context and exhibiting elements of creativity. For example, organizations can use generative AI to: Quickly turn mountains of unstructured text into specific and usable document summaries, paving the way for more informed decision-making.
And truly, there can’t be an effective RAG without an NLP library that is production-ready, natively distributed, state-of-the-art, and user-friendly. We’re excited to unveil Spark NLP 5.1 New Features Spark NLP ONNX (toujours) In Spark NLP 5.1.0, Following our introduction of ONNX Runtime in Spark NLP 5.0.0—which
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Knowledge-intensive Natural Language Processing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. The primary challenge in knowledge-intensive NLP tasks is that large pre-trained language models need help accessing and manipulating knowledge precisely. Check out the Paper.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
Be sure to check out her talk, “C reating a Custom Vocabulary for NLP tasks using exBERT and spaCY ,” there! Natural Language Processing (NLP) tasks involve analyzing, understanding, and generating human language. However, the first step in any NLP task is to pre-process the text for training. Why do we need a custom vocabulary?
Natural language processing (NLP) focuses on enabling computers to understand and generate human language, making interactions more intuitive and efficient. Despite significant advancements in NLP, models often need to help maintain context over extended text and conversations, especially when the context includes lengthy documents.
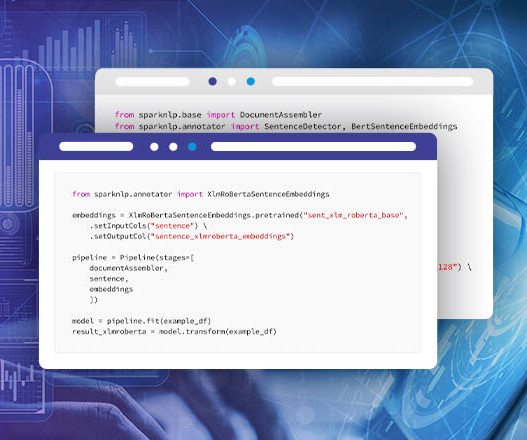
Contextual Entity Ruler in Spark NLP refines entity recognition by applying context-aware rules to detected entities. Whether youre working with clinical NLP, financial documents, or any domain where accuracy matters, this approach can significantly enhance your entity extraction pipeline. setInputCols(["document"]).setOutputCol("sentence")
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
Introduction In natural language processing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The minimal number of documents in which a word must appear to be retained is min_df, which is set to 5.
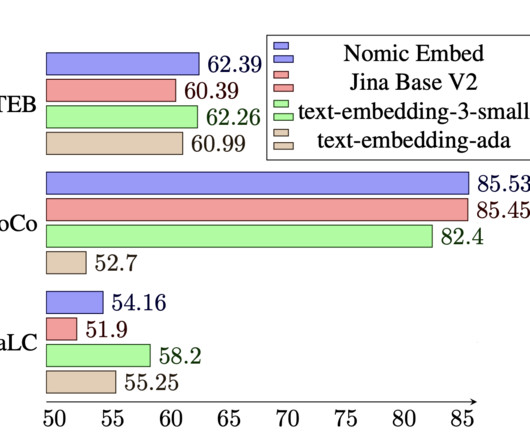
Text embeddings are vector representations of words, sentences, paragraphs or documents that capture their semantic meaning. They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more.
From drug discovery to transcribing medical documents and even assisting in surgeries, it is transforming medical professionals’ lives and even helps reduce errors and improve their efficiency. Bioformer Bioformer is a compact version of BERT that can be used for biomedical text mining.
Many different transformer models have already been implemented in Spark NLP, and specifically for text classification, Spark NLP provides various annotators that are designed to work with pretrained language models. BERT-based Transformers are a family of deep learning models that use the transformer architecture.
In the evolving landscape of natural language processing (NLP), the ability to grasp and process extensive textual contexts is paramount. They transform sentences or documents into low-dimensional vectors, capturing the essence of semantic information, which in turn facilitates tasks like clustering, classification, and information retrieval.
Summary: This blog provides a comprehensive guide to the top 15 Natural Language Processing (NLP) interview questions and answers. Introduction Natural Language Processing (NLP) is a rapidly advancing field that sits at the intersection of linguistics, computer science, and artificial intelligence. What are the Key Components Of NLP?
This post expands on the NAACL 2019 tutorial on Transfer Learning in NLP. In the span of little more than a year, transfer learning in the form of pretrained language models has become ubiquitous in NLP and has contributed to the state of the art on a wide range of tasks. However, transfer learning is not a recent phenomenon in NLP.
Inference experiment: Real-time document understanding with LayoutLM Inference, as opposed to training, is a continuous, unbounded workload that doesn’t have a defined completion point. Specifically, we select LayoutLM , a pre-trained transformer model used for document image processing and information extraction.
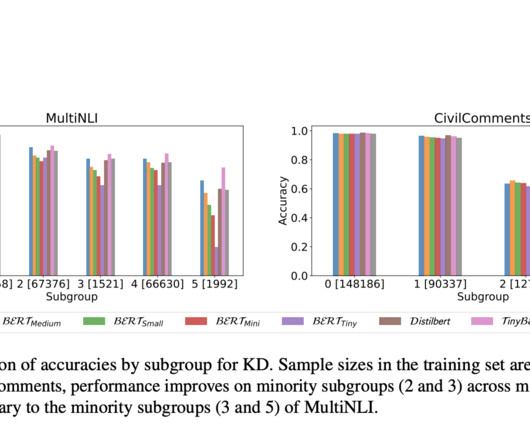
This pivot is crucial in Natural Language Processing (NLP), facilitating applications from document classification to advanced conversational agents. have proposed a comprehensive investigation into the effects of model compression on the subgroup robustness of BERT language models.
Sentence embeddings with Transformers are a powerful natural language processing (NLP) technique that use deep learning models known as Transformers to encode sentences into fixed-length vectors that can be used for a variety of NLP tasks. Introduction to Spark NLP Spark NLP is an open-source library maintained by John Snow Labs.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content