This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A corpus of text is an example of a collection of documents. This method highlights the underlying structure of a body of text, bringing to light themes and patterns that might […] The post Unveiling the Future of Text Analysis: Trendy Topic Modeling with BERT appeared first on Analytics Vidhya.
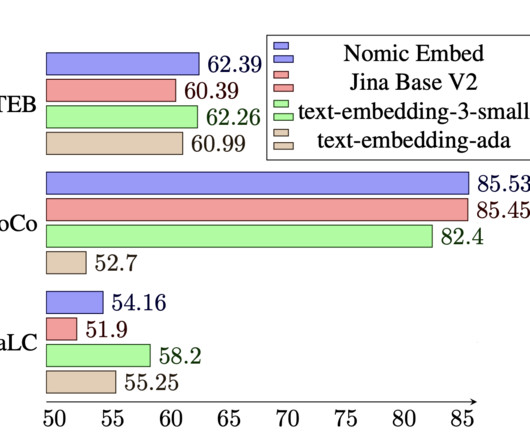
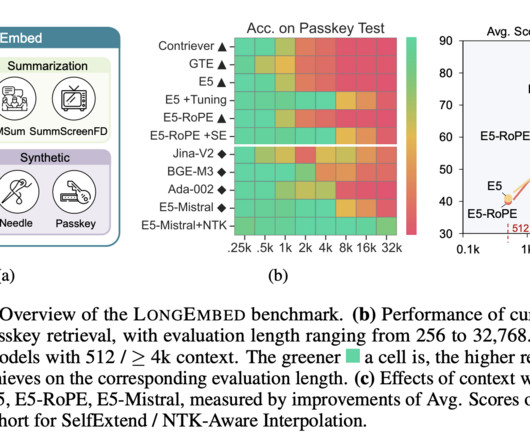
Current text embedding models, like BERT, are limited to processing only 512 tokens at a time, which hinders their effectiveness with long documents. This limitation often results in loss of context and nuanced understanding.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
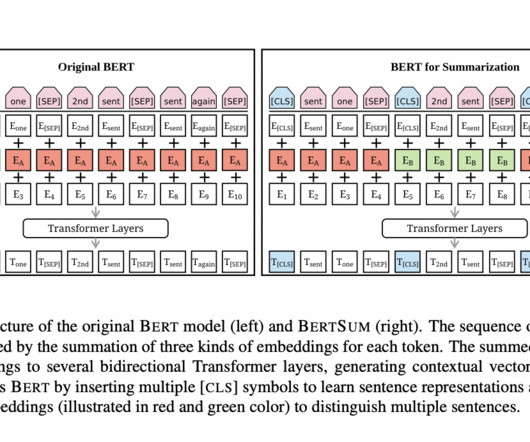
Models like GPT, BERT, and PaLM are getting popular for all the good reasons. The well-known model BERT, which stands for Bidirectional Encoder Representations from Transformers, has a number of amazing applications. It aims to reduce a document to a manageable length while keeping the majority of its meaning.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
document parsing, embedding, prompt management, source verification, audit tracking); High-quality, smaller, specialized LLMs that have been optimized for fact-based question-answering and enterprise workflows and Open Source, Cost-effective, Private deployment with flexibility and options for customization. not found’ classification).
Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction. LLMs like GPT, BERT, and OPT have harnessed transformers technology. Image and Document Processing Multimodal LLMs have completely replaced OCR.
BERT and its Variants : BERT (Bidirectional Encoder Representations from Transformers) by Google, is another significant model that has seen various updates and iterations like RoBERTa, and DistillBERT. These models are trained on diverse datasets, enabling them to create embeddings that capture a wide array of linguistic nuances.
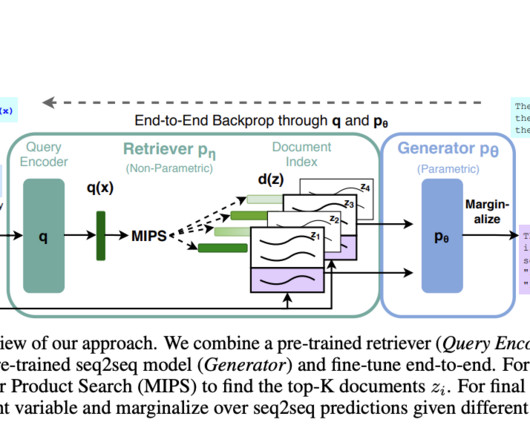
RAG is a technique that extends the knowledge and capabilities of large language models (LLMs) by providing them with access to external information sources, such as databases or document collections. Retrieval : The system queries a vector database or document collection to find information relevant to the user's query.
While new tasks and models emerge so often for many application domains, the underlying documents being modeled stay mostly unaltered. Introduction Training and inference with large neural models are computationally expensive and time-consuming. In light of this, to improve the efficiency of future […].
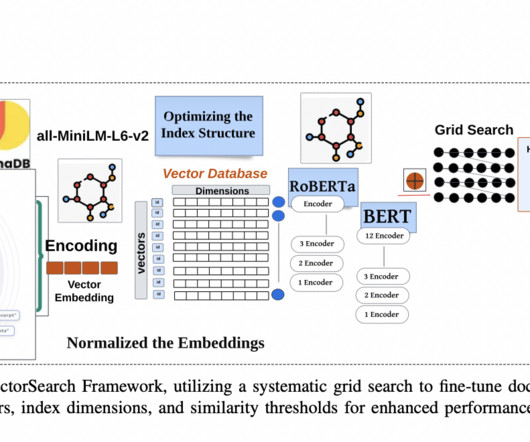
While some progress has been made in enhancing retrieval mechanisms through latent semantic analysis (LSA) and deep learning models, these methods still need to address the semantic gaps between queries and documents. These capabilities set it apart from conventional systems, offering a comprehensive solution for document retrieval.
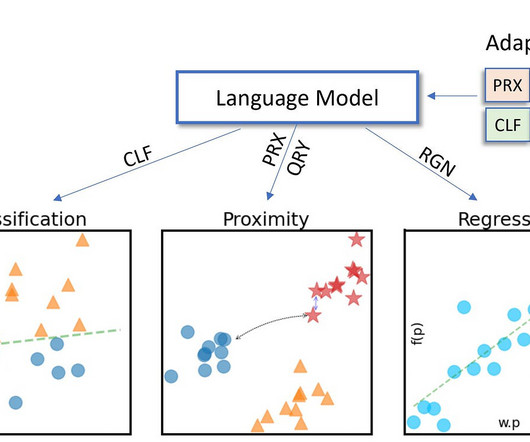
Fig 1: SPECTER2 uses adapters to generate task-specific embeddings for an input document TL;DR: We create SPECTER2 , a new scientific document embedding model via a 2-step training process on large datasets spanning 9 different tasks and 23 fields of study. iii) Out of the 7 tasks, 4 are designed to evaluate document similarity.
LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in Natural Language Processing (NLP).
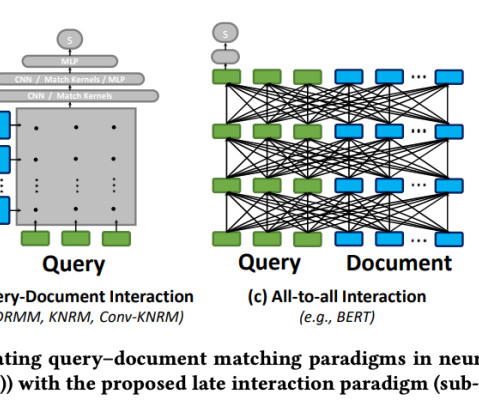
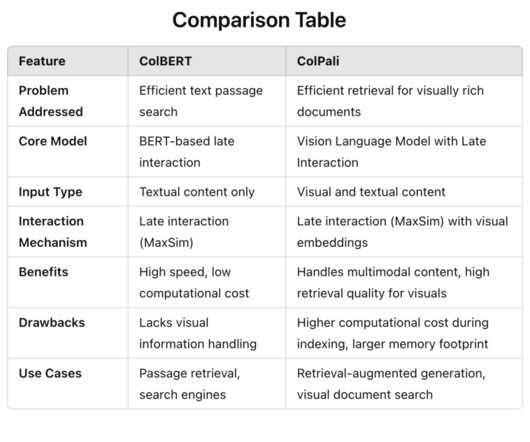
Problem Addressed ColBERT and ColPali address different facets of document retrieval, focusing on improving efficiency and effectiveness. ColBERT seeks to enhance the effectiveness of passage search by leveraging deep pre-trained language models like BERT while maintaining a lower computational cost through late interaction techniques.
For example, organizations can use generative AI to: Quickly turn mountains of unstructured text into specific and usable document summaries, paving the way for more informed decision-making. Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data.
Transformer-based language models, like BERT and T5, are adept at various tasks but struggle with infilling—generating text within a specific location while considering both preceding and succeeding contexts. While early models like BERT masked tokens randomly, later ones like T5 and BART showed improvements with contiguous masking.
Modernization teams perform their code analysis and go through several documents (mostly dated); this is where their reliance on code analysis tools becomes important. The accelerator generated UI for desired channel that could be integrated to the APIs, unit test cases and test data and design documentation.
Google plays a crucial role in advancing AI by developing cutting-edge technologies and tools like TensorFlow, Vertex AI, and BERT. Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini.
The key objective is to connect a model’s built-in knowledge with the vast and ever-growing information available in external databases and documents. This dynamic functionality makes RAG more agile and accurate than models like GPT-3 or BERT , which rely on knowledge acquired during training that can quickly become outdated.
For more details about how to run graph multi-task learning with GraphStorm, refer to Multi-task Learning in GraphStorm in our documentation. With the pre-trained BERT+GNN method, we first use a pre-trained BERT model to compute embeddings for node text features and then train a GNN model for prediction. Dataset Num.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
Traditional NLP methods like CNN, RNN, and LSTM have evolved with transformer architecture and large language models (LLMs) like GPT and BERT families, providing significant advancements in the field. In sequential single interaction, retrievers identify relevant documents, which the language model then uses to predict the output.
Text embeddings are vector representations of words, sentences, paragraphs or documents that capture their semantic meaning. More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings. Existing methods predominantly use smaller BERT-style architectures as the backbone model.
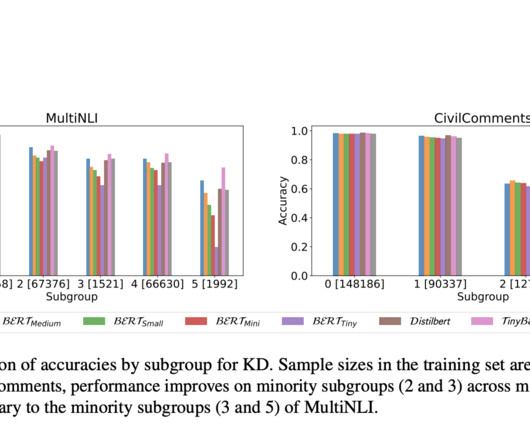
This pivot is crucial in Natural Language Processing (NLP), facilitating applications from document classification to advanced conversational agents. have proposed a comprehensive investigation into the effects of model compression on the subgroup robustness of BERT language models. If you like our work, you will love our newsletter.
From drug discovery to transcribing medical documents and even assisting in surgeries, it is transforming medical professionals’ lives and even helps reduce errors and improve their efficiency. Bioformer Bioformer is a compact version of BERT that can be used for biomedical text mining.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
The Eora MRIO (Multi-region input-output) dataset is a globally recognized spend-based emission factor set that documents the inter-sectoral transfers amongst 15.909 sectors across 190 countries. These commodity classes are associated with emission factors used to estimate environmental impacts using expenditure data.
BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018. Dev Developers can write, test and document faster using AI tools that generate custom snippets of code.
Inference experiment: Real-time document understanding with LayoutLM Inference, as opposed to training, is a continuous, unbounded workload that doesn’t have a defined completion point. Specifically, we select LayoutLM , a pre-trained transformer model used for document image processing and information extraction.
They transform sentences or documents into low-dimensional vectors, capturing the essence of semantic information, which in turn facilitates tasks like clustering, classification, and information retrieval. This restriction undermines their utility in scenarios where understanding the broader document context is crucial.
Text classification with transformers involves using a pretrained transformer model, such as BERT, RoBERTa, or DistilBERT, to classify input text into one or more predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
Transformer-based models such as BERT and GPT-3 further advanced the field, allowing AI to understand and generate human-like text across languages. Developers can start with minimal setup due to the platform’s intuitive interface and comprehensive documentation. Accessing and deploying Llama 3.1
The Jina framework specializes in long document processing, while BERT and its variants, like MiniLM and Nomic BERT, optimize for specific tasks like efficiency and long-context data handling. Moreover, the FAISS library aids in the efficient retrieval of documents, streamlining the embedding-based search processes.
General-purpose architectures like BERT, GPT-2, and BART perform strongly on various NLP tasks. The retriever provides the top-K documents based on the input query, and the generator produces output by conditioning these documents.
LLMs, including BERT and GPT-based models, are employed in two primary strategies: prompt engineering, which utilizes the internal knowledge of LLMs, and fine-tuning, which customizes models for specific datasets to improve anomaly detection performance. A projector aligns the vector spaces of BERT and Llama to maintain semantic coherence.
AllenNLP Embeddings Strengths: NLP Specialization: AllenNLP provides embeddings like BERT and ELMo that are specifically designed for NLP tasks. MultiLingual BERT is a versatile model designed to handle multilingual datasets effectively. It provides an embedding dimension of 768 and a substantial model size of 1.04
Despite significant advancements in NLP, models often need to help maintain context over extended text and conversations, especially when the context includes lengthy documents. T5 standardizes NLP tasks as text-to-text, while RoBERTa enhances BERT’s training process for superior performance.
transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, We will generate a measure called Term Frequency, Inverse Document Frequency, shortened to tf-idf for each term in our dataset.
Applications & Impact Meta's Llama is compared to other prominent LLMs, such as BERT and GPT-3. Documentation ambiguities add an extra layer of complexity, requiring users to navigate unclear guidelines. It has been found to outperform them on many external benchmarks, such as QA datasets like Natural Questions and QuAC.
This limitation restricts their use in scenarios demanding the analysis of extended documents, such as legal contracts or detailed academic reviews. Early models like BERT utilized absolute position embedding (APE), while more recent innovations like RoFormer and LLaMA incorporate rotary position embedding (RoPE) for handling longer texts.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content