This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
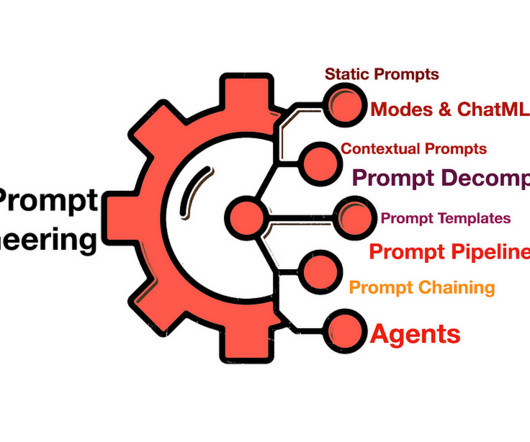
In the ever-evolving landscape of artificial intelligence, the art of promptengineering has emerged as a pivotal skill set for professionals and enthusiasts alike. Promptengineering, essentially, is the craft of designing inputs that guide these AI systems to produce the most accurate, relevant, and creative outputs.
However, traditional deeplearning methods often struggle to interpret the semantic details in log data, typically in natural language. Current LLM-based methods for anomaly detection include promptengineering, which uses LLMs in zero/few-shot setups, and fine-tuning, which adapts models to specific datasets.
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deeplearning and Natural Language Processing (NLP) to play pivotal roles in this tech. Today platforms like Spotify are leveraging AI to fine-tune their users' listening experiences.
Another breakthrough is the rise of generative language models powered by deeplearning algorithms. Facebook's RoBERTa, built on the BERT architecture, utilizes deeplearning algorithms to generate text based on given prompts. trillion parameters, making it one of the largest language models ever created.
By 2017, deeplearning began to make waves, driven by breakthroughs in neural networks and the release of frameworks like TensorFlow. The DeepLearning Boom (20182019) Between 2018 and 2019, deeplearning dominated the conference landscape.
The advent of more powerful personal computers paved the way for the gradual acceptance of deeplearning-based methods. The introduction of attention mechanisms has notably altered our approach to working with deeplearning algorithms, leading to a revolution in the realms of computer vision and natural language processing (NLP).
The role of promptengineer has attracted massive interest ever since Business Insider released an article last spring titled “ AI ‘PromptEngineer Jobs: $375k Salary, No Tech Backgrund Required.” It turns out that the role of a PromptEngineer is not simply typing questions into a prompt window.
Generative AI represents a significant advancement in deeplearning and AI development, with some suggesting it’s a move towards developing “ strong AI.” The result will be unusable if a user prompts the model to write a factual news article.
With advancements in deeplearning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Neural Networks & DeepLearning : Neural networks marked a turning point, mimicking human brain functions and evolving through experience.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of DeepLearning. Some Terminologies related to Artificial Intelligence (Ai) DeepLearning is a technique used in artificial intelligence (AI) that teaches computers to interpret data in a manner modeled after the human brain.
LLMs are a class of deeplearning models that are pretrained on massive text corpora, allowing them to generate human-like text and understand natural language at an unprecedented level. Promptengineering is crucial to steering LLMs effectively. What are Large Language Models and Why are They Important?
350x: Application Areas , Companies, Startups 3,000+: Prompts , PromptEngineering, & Prompt Lists 250+: Hardware, Frameworks , Approaches, Tools, & Data 300+: Achievements, Impacts on Society , AI Regulation, & Outlook 20x: What is Generative AI? Deeplearning neural network.
Harnessing the power of deeplearning for image segmentation is revolutionizing numerous industries, but often encounters a significant obstacle – the limited availability of training data. Over the years, various successful deeplearning architectures have been developed for this task, such as U-Net or SegFormer.
However, as the size and complexity of the deeplearning models that power generative AI continue to grow, deployment can be a challenging task. Then, we highlight how Amazon SageMaker large model inference deeplearning containers (LMI DLCs) can help with optimization and deployment.
Topological DeepLearning Made Easy with TopoX with Dr. Mustafa Hajij Slides In these AI slides, Dr. Mustafa Hajij introduced TopoX, a comprehensive Python suite for topological deeplearning. The open-source nature of TopoX positions it as a valuable asset for anyone exploring topological deeplearning.
A lot goes into learning a new skill, regardless of how in-depth it is. Getting started with natural language processing (NLP) is no exception, as you need to be savvy in machine learning, deeplearning, language, and more. To get you started on your journey, we’ve released a new on-demand Introduction to NLP course.
Introduction to LLMs LLM in the sphere of AI Large language models (often abbreviated as LLMs) refer to a type of artificial intelligence (AI) model typically based on deeplearning architectures known as transformers. Large language models, such as GPT-3 (Generative Pre-trained Transformer 3), BERT, XLNet, and Transformer-XL, etc.,
Promptengineering: Carefully designing prompts to guide the model's behavior. Curriculum learning: Gradually increasing the difficulty of tasks during training. Bidirectional language understanding with BERT. Tensorgrad is a tensor & deeplearning framework. PyTorch meets SymPy.
Large language models are foundational, based on deeplearning and artificial intelligence (AI), and are usually trained on massive datasets that create the foundation of their knowledge and abilities. Popular LLMs include Falcon 40B, GPT-4, LLaMa 2, and BERT. This is the stage at which promptengineering is crucial.
This trend started with models like the original GPT and ELMo, which had millions of parameters, and progressed to models like BERT and GPT-2, with hundreds of millions of parameters. Learn more about it in our dedicated blog series on Generative AI. months on average.
Unsurprisingly, Machine Learning (ML) has seen remarkable progress, revolutionizing industries and how we interact with technology. The emergence of Large Language Models (LLMs) like OpenAI's GPT , Meta's Llama , and Google's BERT has ushered in a new era in this field. We pay our contributors, and we don't sell ads.
Harnessing the power of deeplearning for image segmentation is revolutionizing numerous industries, but often encounters a significant obstacle the limited availability of training data. Over the years, various successful deeplearning architectures have been developed for this task, such as U-Net or SegFormer.
BERT and GPT are examples. You can adapt foundation models to downstream tasks in the following ways: PromptEngineering: Promptengineering is a powerful technique that enables LLMs to be more controllable and interpretable in their outputs, making them more suitable for real-world applications with specific requirements and constraints.
This year is intense: we have, among others, a new generative model that beats GANs , an AI-powered chatbot that discusses with more than 1 million people in a week and promptengineering , a job that did not exist a year ago. It is not surprising that it has become a major application area for deeplearning.
Considerations for Choosing a Distance Metric for Text Embeddings: Scale or Magnitude : Embeddings from models like Word2Vec, FastText, BERT, and GPT are often normalized to unit length. We’re committed to supporting and inspiring developers and engineers from all walks of life. We pay our contributors, and we don’t sell ads.
Then, we had a lot of machine-learning and deep-learningengineers. The work involved in training something like a BERT model and a large language model is very similar. That knowledge transfers, but the skillset that you’re operating in, there are unique engineering challenges.
Transformers, like BERT and GPT, brought a novel architecture that excelled at capturing contextual relationships in language. Techniques such as promptengineering, context windowing, and reinforcement learning from human feedback (RLHF) are used to reduce the chances of generating harmful or biased content.
Then, we had a lot of machine-learning and deep-learningengineers. The work involved in training something like a BERT model and a large language model is very similar. That knowledge transfers, but the skillset that you’re operating in, there are unique engineering challenges.
Then, we had a lot of machine-learning and deep-learningengineers. The work involved in training something like a BERT model and a large language model is very similar. That knowledge transfers, but the skillset that you’re operating in, there are unique engineering challenges.
In short, EDS is the problem of the widespread lack of a rational approach to and methodology for the objective, automated and quantitative evaluation of performance in terms of generative model finetuning and promptengineering for specific downstream GenAI tasks related to practical business applications. Garrido-Merchán E.C.,
These are deeplearning models used in NLP. Machine learning is about teaching computers to perform tasks by recognizing patterns, while deeplearning, a subset of machine learning, creates a network that learns independently. We choose a BERT model fine-tuned on the SQuAD dataset.
These advancements have been driven by significant breakthroughs in deeplearning and the availability of large datasets, allowing models to understand and generate human-like text with significant accuracy. Two key techniques driving these advancements are promptengineering and few-shot learning.
These advanced AI deeplearning models have seamlessly integrated into various applications, from Google's search engine enhancements with BERT to GitHub’s Copilot, which harnesses the capability of Large Language Models (LLMs) to convert simple code snippets into fully functional source codes.
The pre-train and fine-tune paradigm, exemplified by models like ELMo and BERT, has evolved into prompt-based reasoning used by the GPT family. Techniques like Uprise and DaSLaM use lightweight retrievers or small models to optimize prompts, break down complex problems, or generate pseudo labels.
Utilizing the latest Hugging Face LLM modules on Amazon SageMaker, AWS customers can now tap into the power of SageMaker deeplearning containers (DLCs). accuracy on the development set, while its counterpart bert-base-uncased boasts an accuracy of 92.7%. He focuses on developing scalable machine learning algorithms.
Examples include our Deep Researcher, Deep Coder, and Advisor models. After testing available open source models, we felt that the out-of-the-box capabilities and responses were insufficient with promptengineering alone to meet our needs.
Generating improved instructions for each question-and-answer pair using an automatic promptengineering technique based on the Auto-Instruct Repository. The value of Amazon Bedrock in text generation for automatic promptengineering and text summarization for evaluation helped tremendously in the collaboration with Tealium.
This skill simplifies the data extraction process, allowing security analysts to conduct investigations more efficiently without requiring deep technical knowledge. We used promptengineering guidelines to tailor our prompts to generate better responses from the LLM. A three-shot prompting strategy is used for this task.
Autoencoding models, which are better suited for information extraction, distillation and other analytical tasks, are resting in the background — but let’s not forget that the initial LLM breakthrough in 2018 happened with BERT, an autoencoding model. Developers can now focus on efficient promptengineering and quick app prototyping.[11]
Devvret: We started Predibase in 2021 with the mission to democratize deeplearning. Initially, we believed the way to democratize deeplearning would be through platforms like ours, but we were surprised by how quickly the field evolved. What I mean is introducing a real active learning process for LLMs.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















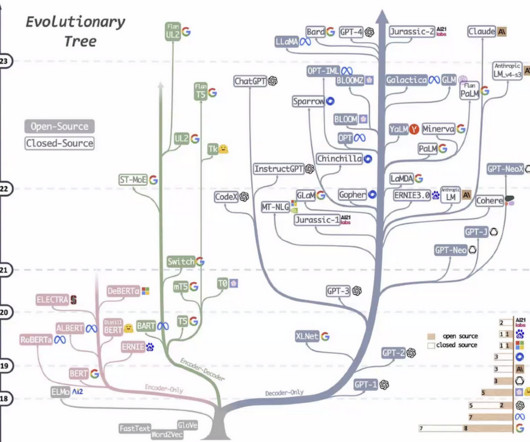

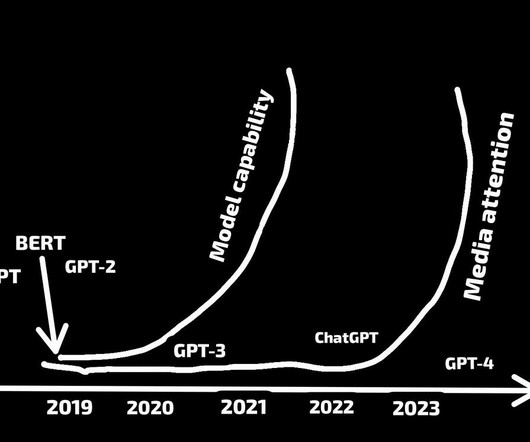















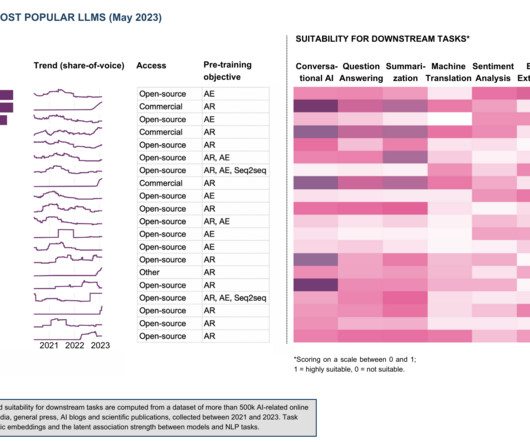







Let's personalize your content