This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction With the advancement in deeplearning, neuralnetwork architectures like recurrent neuralnetworks (RNN and LSTM) and convolutional neuralnetworks (CNN) have shown. The post Transfer Learning for NLP: Fine-Tuning BERT for Text Classification appeared first on Analytics Vidhya.
The ability to effectively represent and reason about these intricate relational structures is crucial for enabling advancements in fields like network science, cheminformatics, and recommender systems. Graph NeuralNetworks (GNNs) have emerged as a powerful deeplearning framework for graph machine learning tasks.
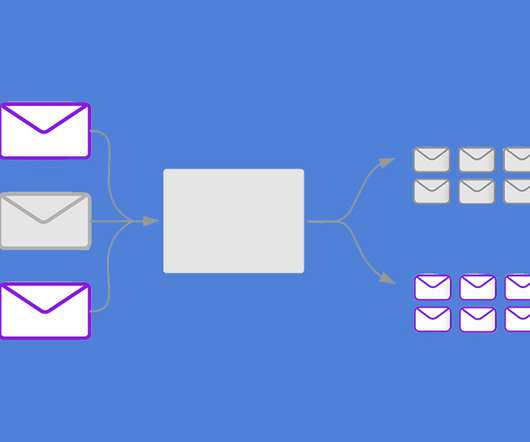
These systems, typically deeplearning models, are pre-trained on extensive labeled data, incorporating neuralnetworks for self-attention. This article introduces UltraFastBERT, a BERT-based framework matching the efficacy of leading BERT models but using just 0.3%
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neuralnetworks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GPT, BERT) Image Generation (e.g., Learn about supervised, unsupervised, and reinforcement learning.
Summary: DeepLearning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Introduction DeepLearning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. With a projected market growth from USD 6.4
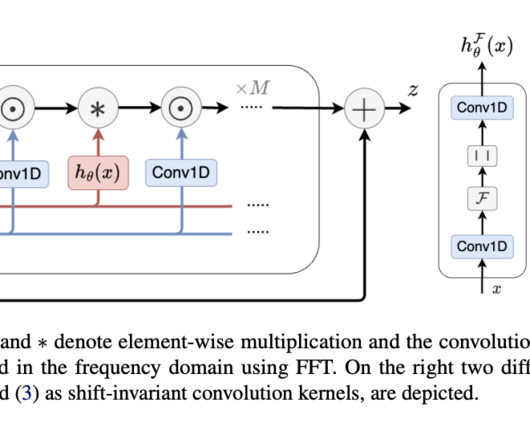
In deeplearning, especially in NLP, image analysis, and biology, there is an increasing focus on developing models that offer both computational efficiency and robust expressiveness. This layer adapts its kernel using a conditioning neuralnetwork, significantly enhancing Orchid’s ability to filter long sequences effectively.
The authenticity of this approach lies in its ability to learn the fundamental data distribution and generate novel instances that are not mere replicas. introduced the concept of Generative Adversarial Networks (GANs) , where two neuralnetworks, i.e., the generator and the discriminator, are trained simultaneously.
NeuralNetwork: Moving from Machine Learning to DeepLearning & Beyond Neuralnetwork (NN) models are far more complicated than traditional Machine Learning models. Advances in neuralnetwork techniques have formed the basis for transitioning from machine learning to deeplearning.
These patterns are then decoded using deepneuralnetworks to reconstruct the perceived images. The encoder translates visual stimuli into corresponding brain activity patterns through convolutional neuralnetworks (CNNs) that mimic the human visual cortex's hierarchical processing stages.
With nine times the speed of the Nvidia A100, these GPUs excel in handling deeplearning workloads. Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deeplearning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
This gap has led to the evolution of deeplearning models, designed to learn directly from raw data. What is DeepLearning? Deeplearning, a subset of machine learning, is inspired by the structure and functioning of the human brain. High Accuracy: Delivers superior performance in many tasks.
Project Structure Accelerating Convolutional NeuralNetworks Parsing Command Line Arguments and Running a Model Evaluating Convolutional NeuralNetworks Accelerating Vision Transformers Evaluating Vision Transformers Accelerating BERT Evaluating BERT Miscellaneous Summary Citation Information What’s New in PyTorch 2.0?
The explosion in deeplearning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. The basic idea of MoEs is to construct a network from a number of expert sub-networks, where each input is processed by a suitable subset of experts.
This process of adapting pre-trained models to new tasks or domains is an example of Transfer Learning , a fundamental concept in modern deeplearning. Transfer learning allows a model to leverage the knowledge gained from one task and apply it to another, often with minimal additional training.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deeplearning, computer vision , natural language processing , and more. NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT.
DeepNeuralNetworks (DNNs) have proven to be exceptionally adept at processing highly complicated modalities like these, so it is unsurprising that they have revolutionized the way we approach audio data modeling. Traditional machine learning feature-based pipeline vs. end-to-end deeplearning approach ( source ).
By 2017, deeplearning began to make waves, driven by breakthroughs in neuralnetworks and the release of frameworks like TensorFlow. Sessions on convolutional neuralnetworks (CNNs) and recurrent neuralnetworks (RNNs) started gaining popularity, marking the beginning of data sciences shift toward AI-driven methods.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. Deeplearning refers to the use of neuralnetwork architectures, characterized by their multi-layer design (i.e.
In AI, particularly in deeplearning , this often means dealing with a rapidly increasing number of computations as models grow in size and handle larger datasets. AI models like neuralnetworks , used in applications like Natural Language Processing (NLP) and computer vision , are notorious for their high computational demands.
Summary: Neuralnetworks are a key technique in Machine Learning, inspired by the human brain. They consist of interconnected nodes that learn complex patterns in data. This architecture allows neuralnetworks to learn complex patterns and relationships within data.
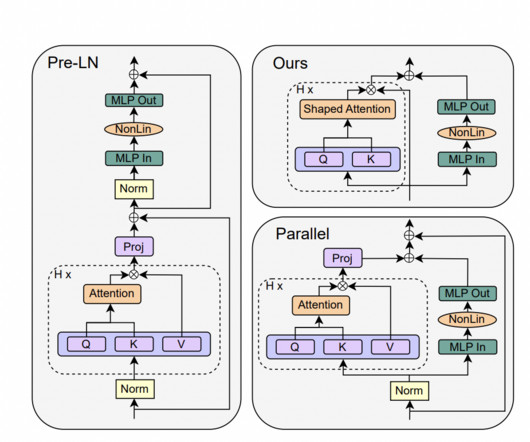
The research presents a study on simplifying transformer blocks in deepneuralnetworks, specifically focusing on the standard transformer block. The study examines the simplification of transformer blocks in deepneuralnetworks, focusing specifically on the standard transformer block.
With advancements in deeplearning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. NeuralNetworks & DeepLearning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience.
They said transformer models , large language models (LLMs), vision language models (VLMs) and other neuralnetworks still being built are part of an important new category they dubbed foundation models. Earlier neuralnetworks were narrowly tuned for specific tasks.
Summary: Recurrent NeuralNetworks (RNNs) are specialised neuralnetworks designed for processing sequential data by maintaining memory of previous inputs. Introduction Neuralnetworks have revolutionised data processing by mimicking the human brain’s ability to recognise patterns.
Exploring the Techniques of LIME and SHAP Interpretability in machine learning (ML) and deeplearning (DL) models helps us see into opaque inner workings of these advanced models. Flawed Decision Making The opaqueness in the decision-making process of LLMs like GPT-3 or BERT can lead to undetected biases and errors.
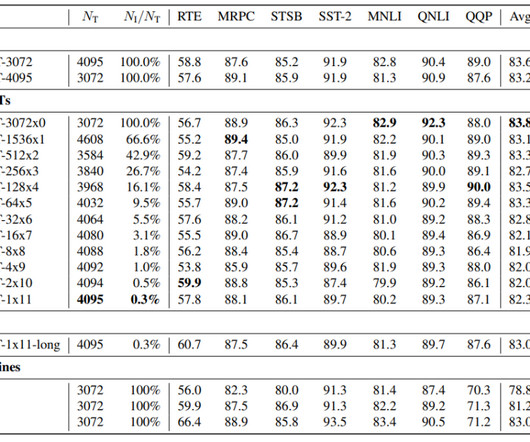
We also released a comprehensive study of co-training language models (LM) and graph neuralnetworks (GNN) for large graphs with rich text features using the Microsoft Academic Graph (MAG) dataset from our KDD 2024 paper. GraphStorm provides different ways to fine-tune the BERT models, depending on the task types. Dataset Num.
Large Language Models (LLMs) like ChatGPT, Google’s Bert, Gemini, Claude Models, and others have emerged as central figures, redefining our interaction with digital interfaces. These models use deeplearning techniques, particularly neuralnetworks, to process and produce text that mimics human-like understanding and responses.
Models such as GPT, BERT , and more recently Llama , Mistral are capable of understanding and generating human-like text with unprecedented fluency and coherence. The Rise of CUDA-Accelerated AI Frameworks GPU-accelerated deeplearning has been fueled by the development of popular AI frameworks that leverage CUDA for efficient computation.
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. Machine & DeepLearning Machine learning is the fundamental data science skillset, and deeplearning is the foundation for NLP.
Let’s create a small dataset of abstracts from various fields: Copy Code Copied Use a different Browser abstracts = [ { "id": 1, "title": "DeepLearning for Natural Language Processing", "abstract": "This paper explores recent advances in deeplearning models for natural language processing tasks.
Models like OpenAI’s ChatGPT and Google Bard require enormous volumes of resources, including a lot of training data, substantial amounts of storage, intricate, deeplearning frameworks, and enormous amounts of electricity. What are Small Language Models? million parameters to Medium with 41 million.
A significant breakthrough came with neuralnetworks and deeplearning. Models like Google's Neural Machine Translation (GNMT) and Transformer revolutionized language processing by enabling more nuanced, context-aware translations. IBM's Model 1 and Model 2 laid the groundwork for advanced systems.
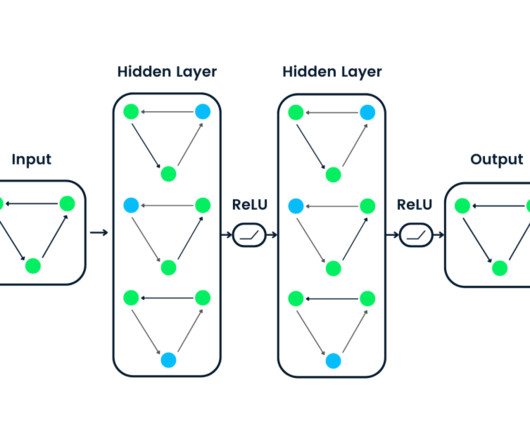
Activation functions for neuralnetworks are an essential part of deeplearning since they decide the accuracy and efficiency of the training model used to create or split a large-scale neuralnetwork and the output of deeplearning models.
The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis. 20212024: Interest declined as deeplearning and pre-trained models took over, automating many tasks previously handled by classical ML techniques.
Summary: Batch Normalization in DeepLearning improves training stability, reduces sensitivity to hyperparameters, and speeds up convergence by normalising layer inputs. It’s a crucial technique in modern neuralnetworks, enhancing performance and generalisation. The global DeepLearning market, valued at $17.60
Over the years, we evolved that to solving NLP use cases by adopting NeuralNetwork-based algorithms loosely based on the structure and function of a human brain. 2003) “ Support-vector networks ” by Cortes and Vapnik (1995) Significant people : David Blei Corinna Cortes Vladimir Vapnik 4.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
Another breakthrough is the rise of generative language models powered by deeplearning algorithms. Facebook's RoBERTa, built on the BERT architecture, utilizes deeplearning algorithms to generate text based on given prompts. trillion parameters, making it one of the largest language models ever created.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does.
They use deeplearning techniques to process and produce language in a contextually relevant manner. Parameter In the context of neuralnetworks, including LLMs, a parameter is a variable part of the model’s architecture learned from the training data.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
Many frameworks employ a generic neuralnetwork for a wide range of image restoration tasks, but these networks are each trained separately. Recent deeplearning methods have displayed stronger and more consistent performance when compared to traditional image restoration methods.
Natural Language Processing Transformers, the neuralnetwork architecture, that has taken the world of natural language processing (NLP) by storm, is a class of models that can be used for both language and image processing. One of the earliest representation models used in NLP was the Bag of Words (BoW) model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content