This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Programming Languages: Python (most widely used in AI/ML) R, Java, or C++ (optional but useful) 2.
However, traditional deeplearning methods often struggle to interpret the semantic details in log data, typically in natural language. The study reviews approaches to log-based anomaly detection, focusing on deeplearning methods, especially those using pretrained LLMs. higher than the best alternative, NeuralLog.
While deeplearning models have achieved state-of-the-art results in this area, they require large amounts of labeled data, which is costly and time-consuming. Active learning helps optimize this process by selecting the most informative unlabeled samples for annotation, reducing the labeling effort.
In deeplearning, especially in NLP, image analysis, and biology, there is an increasing focus on developing models that offer both computational efficiency and robust expressiveness. The model outperforms traditional attention-based models, such as BERT and Vision Transformers, across domains with smaller model sizes.
AI and ML are expanding at a remarkable rate, which is marked by the evolution of numerous specialized subdomains. While they share foundational principles of machine learning, their objectives, methodologies, and outcomes differ significantly. Rather than learning to generate new data, these models aim to make accurate predictions.
With these advancements, it’s natural to wonder: Are we approaching the end of traditional machine learning (ML)? In this article, we’ll look at the state of the traditional machine learning landscape concerning modern generative AI innovations. What is Traditional Machine Learning?
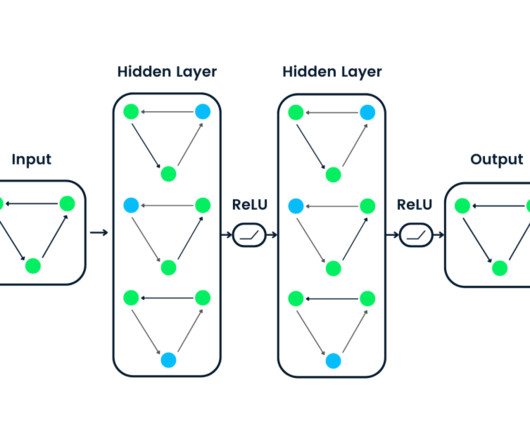
This gap has led to the evolution of deeplearning models, designed to learn directly from raw data. What is DeepLearning? Deeplearning, a subset of machine learning, is inspired by the structure and functioning of the human brain. High Accuracy: Delivers superior performance in many tasks.
Models like GPT, BERT, and PaLM are getting popular for all the good reasons. The well-known model BERT, which stands for Bidirectional Encoder Representations from Transformers, has a number of amazing applications. Recent research investigates the potential of BERT for text summarization.
The practical success of deeplearning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. They believe the proposed computational paradigm shows tremendous promise in connecting deeplearning theory and practice from a unified viewpoint of data compression.
The explosion in deeplearning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Top Training efficiency Efficient optimization methods are the cornerstone of modern ML applications and are particularly crucial in large scale settings.
Introduction To Generative AI Image Source Course difficulty: Beginner-level Completion time: ~ 45 minutes Prerequisites: No What will AI enthusiasts learn? What is Generative Artificial Intelligence, how it works, what its applications are, and how it differs from standard machine learning (ML) techniques.
Deeplearning models have emerged as transformative tools by leveraging RNA sequence data. Recent deeplearning-based methods integrate multiple sequence alignments (MSAs) and secondary structure constraints to enhance RNA 3D structure prediction. Don’t Forget to join our 55k+ ML SubReddit. million sequences.
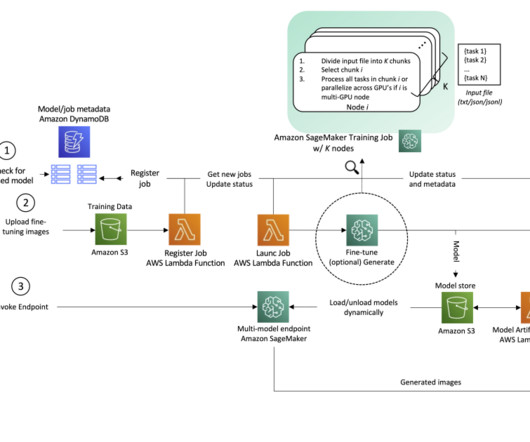
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. TensorRT is an SDK developed by NVIDIA that provides a high-performance deeplearning inference library.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
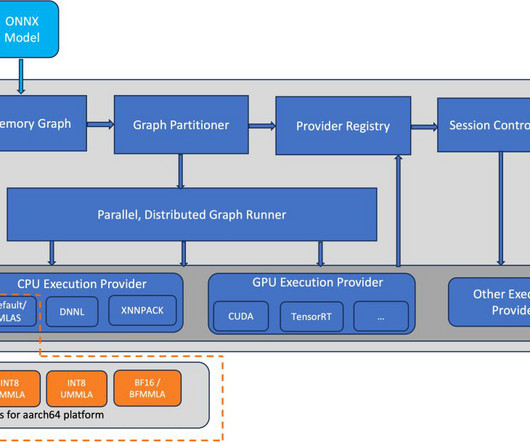
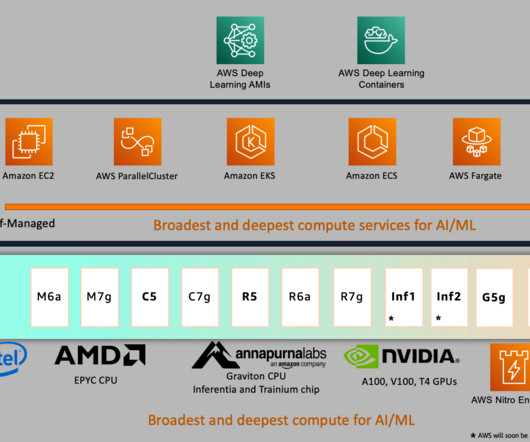
ONNX is an open source machine learning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. AWS Graviton3 processors are optimized for ML workloads, including support for bfloat16, Scalable Vector Extension (SVE), and Matrix Multiplication (MMLA) instructions.
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), natural language processing (NLP), and recommendation systems. If not, refer to Using the SageMaker Python SDK before continuing.
Exploring the Techniques of LIME and SHAP Interpretability in machine learning (ML) and deeplearning (DL) models helps us see into opaque inner workings of these advanced models. Flawed Decision Making The opaqueness in the decision-making process of LLMs like GPT-3 or BERT can lead to undetected biases and errors.
By taking care of the undifferentiated heavy lifting, SageMaker allows you to focus on working on your machine learning (ML) models, and not worry about things such as infrastructure. These two crucial parameters influence the efficiency, speed, and accuracy of training deeplearning models.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. These are basically big models based on deeplearning techniques that are trained with hundreds of billions of parameters.
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. introduces refactored graph ML pipeline APIs. GraphStorm provides different ways to fine-tune the BERT models, depending on the task types.
Traditional NLP methods like CNN, RNN, and LSTM have evolved with transformer architecture and large language models (LLMs) like GPT and BERT families, providing significant advancements in the field. Sparse retrieval employs simpler techniques like TF-IDF and BM25, while dense retrieval leverages deeplearning to improve accuracy.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
These innovations have showcased strong performance in comparison to conventional machine learning (ML) models, particularly in scenarios where labelled data is in short supply. In recent years, remarkable strides have been achieved in crafting extensive foundation language models for natural language processing (NLP).
Graph Neural Networks (GNNs) have emerged as a powerful deeplearning framework for graph machine learning tasks. In this article, we will delve into the latest research at the intersection of graph machine learning and large language models.
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. The code can be found on the GitHub repo.
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. Machine & DeepLearning Machine learning is the fundamental data science skillset, and deeplearning is the foundation for NLP.
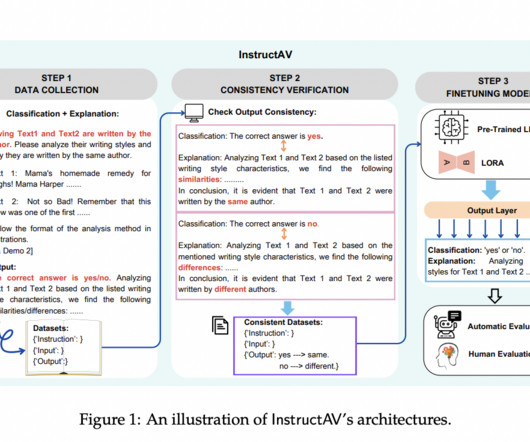
With deeplearning models like BERT and RoBERTa, the field has seen a paradigm shift. Existing methods for AV have advanced significantly with the use of deeplearning models. BERT and RoBERTa, for example, have shown superior performance over traditional stylometric techniques.
The Boom of Generative AI and Large Language Models(LLMs) 20182020: NLP was gaining traction, with a focus on word embeddings, BERT, and sentiment analysis. 20212024: Interest declined as deeplearning and pre-trained models took over, automating many tasks previously handled by classical ML techniques.
The course toward democratization of AI helped to further popularize generative AI following the open-source releases for such foundation model families as BERT, T5, GPT, CLIP and, most recently, Stable Diffusion. Second, SageMaker supports unique GPU-enabled hosting options for deploying deeplearning models at scale.
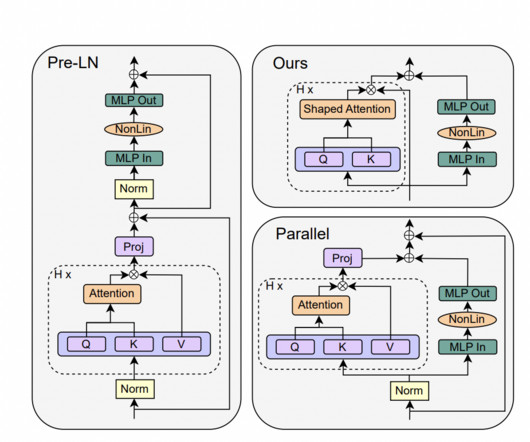
The motivation for simplification arises from the complexity of modern neural network architectures and the gap between theory and practice in deeplearning. The study conducted experiments on autoregressive decoder-only and BERT encoder-only models to assess the performance of the simplified transformers. Check out the Paper.
Customers are always looking for ways to improve the performance and response times of their machine learning (ML) inference workloads without increasing the cost per transaction and without sacrificing the accuracy of the results. In the following example figure, we show INT8 inference performance in C6i for a BERT-base model.
In a compelling talk at ODSC West 2024 , Yan Liu, PhD , a leading machine learning expert and professor at the University of Southern California (USC), shared her vision for how GPT-inspired architectures could revolutionize how we model, understand, and act on complex time series data acrossdomains. The result?
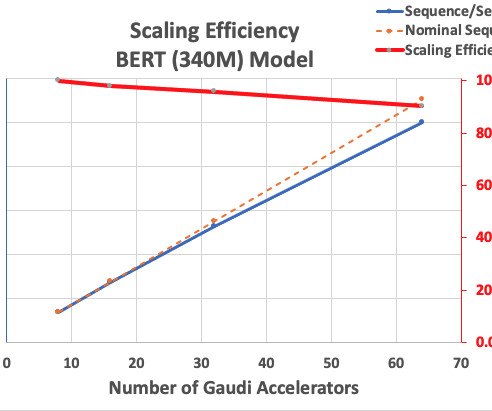
Libraries such as DeepSpeed (an open-source deeplearning optimization library for PyTorch) address some of these challenges, and can help accelerate model development and training. We present scaling results for an encoder-type transformer model (BERT with 340 million to 1.5 All these features are enabled on the BERT 1.5B
Then using Machine Learning and DeepLearning sentiment analysis techniques, these businesses analyze if a customer feels positive or negative about their product so that they can make appropriate business decisions to improve their business. Words like “Descent”, “Average”, etc. are assigned a negative label.
In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. Trn1 instances are purpose built for high-performance deeplearning model training while offering up to 50% cost-to-train savings over comparable GPU-based instances.
Let’s create a small dataset of abstracts from various fields: Copy Code Copied Use a different Browser abstracts = [ { "id": 1, "title": "DeepLearning for Natural Language Processing", "abstract": "This paper explores recent advances in deeplearning models for natural language processing tasks.
Amazon SageMaker multi-model endpoints (MMEs) provide a scalable and cost-effective way to deploy a large number of machine learning (ML) models. It gives you the ability to deploy multiple ML models in a single serving container behind a single endpoint. Instance Type GPU Type Num of GPUs GPU Memory (GiB) ml.g4dn.2xlarge
Implementing end-to-end deeplearning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. But you need to fine-tune these language models when performing your deeplearning projects. This is where AI platforms come in. Let’s do this.
We’re using deepset/roberta-base-squad2 , which is: Based on RoBERTa architecture (a robustly optimized BERT approach) Fine-tuned on SQuAD 2.0 Dont Forget to join our 85k+ ML SubReddit. Let’s start by installing the necessary libraries: # Install required packages Copy Code Copied Use a different Browser !pip Windows NT 10.0;
This week we are diving into some interesting discussions on transformers, BERT, and RAG, along with some interesting collaboration opportunities for building a bot, a productivity app, and more. If you are good with Python, AI, ML, APIs, py-cord, or setting up a machine/server, connect with him in the Discord thread!
Text classification with transformers refers to the application of deeplearning models based on the transformer architecture to classify sequences of text into predefined categories or labels. BERT (Bidirectional Encoder Representations from Transformers) is a language model that was introduced by Google in 2018.
Great machine learning (ML) research requires great systems. In this post, we provide an overview of the numerous advances made across Google this past year in systems for ML that enable us to support the serving and training of complex models while easing the complexity of implementation for end users.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content