This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With these advancements, it’s natural to wonder: Are we approaching the end of traditional machinelearning (ML)? In this article, we’ll look at the state of the traditional machinelearning landscape concerning modern generative AI innovations. What is Traditional MachineLearning? What are its Limitations?
Generative AI is powered by advanced machinelearning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Roles like AI Engineer, MachineLearning Engineer, and Data Scientist are increasingly requiring expertise in Generative AI.
Introduction Large Language Models (LLMs) are foundational machinelearning models that use deeplearning algorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and entity relationships in the language.
Summary: DeepLearning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Introduction DeepLearning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. With a projected market growth from USD 6.4
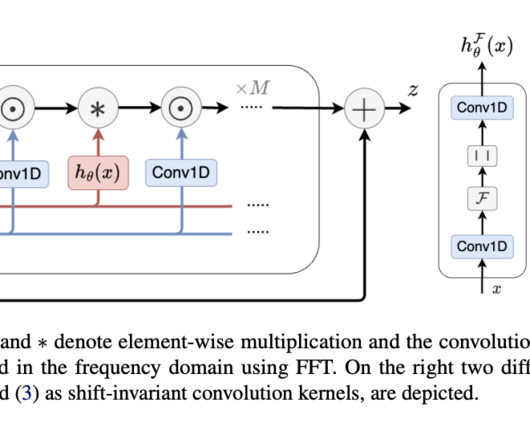
In deeplearning, especially in NLP, image analysis, and biology, there is an increasing focus on developing models that offer both computational efficiency and robust expressiveness. The model outperforms traditional attention-based models, such as BERT and Vision Transformers, across domains with smaller model sizes.
In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection. Machinelearning models, particularly those based on deeplearning architectures like BERT, have shown great promise in identifying malicious URLs by analyzing their textual features.
I have written short summaries of 68 different research papers published in the areas of MachineLearning and Natural Language Processing. Mind the gap: Challenges of deeplearning approaches to Theory of Mind Jaan Aru, Aqeel Labash, Oriol Corcoll, Raul Vicente. University of Wisconsin-Madison. University of Tartu.
Traditional machinelearning models, while effective in many scenarios, often struggle to process high-dimensional and unstructured data without extensive preprocessing and feature engineering. This gap has led to the evolution of deeplearning models, designed to learn directly from raw data.
Introduction Welcome into the world of Transformers, the deeplearning model that has transformed Natural Language Processing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines understand language, from translating texts to analyzing sentiments.
While they share foundational principles of machinelearning, their objectives, methodologies, and outcomes differ significantly. Rather than learning to generate new data, these models aim to make accurate predictions. Notably, BERT (Bidirectional Encoder Representations from Transformers), introduced by Devlin et al.
Machinelearning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. Training experiment: Training BERT Large from scratch Training, as opposed to inference, is a finite process that is repeated much less frequently.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deeplearning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
Machinelearning , a subset of AI, involves three components: algorithms, training data, and the resulting model. An algorithm, essentially a set of procedures, learns to identify patterns from a large set of examples (training data). The culmination of this training is a machine-learning model.
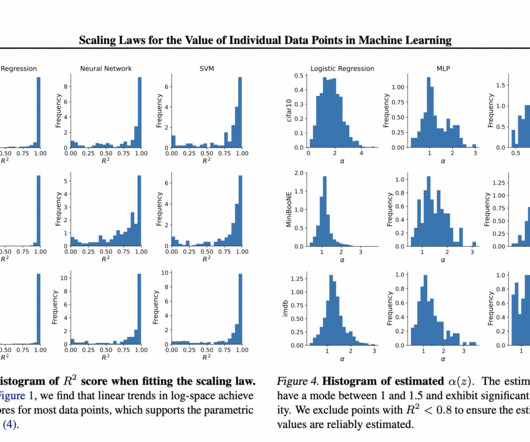
Machinelearning models for vision and language, have shown significant improvements recently, thanks to bigger model sizes and a huge amount of high-quality training data. The related works in this paper discuss a method called Scaling Laws for deeplearning, which have become popular in recent years.
The practical success of deeplearning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. They believe the proposed computational paradigm shows tremendous promise in connecting deeplearning theory and practice from a unified viewpoint of data compression.
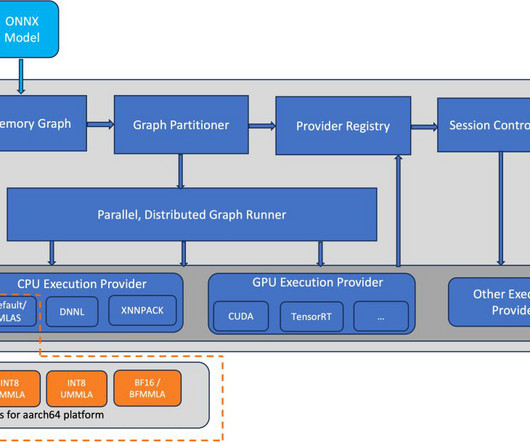
ONNX is an open source machinelearning (ML) framework that provides interoperability across a wide range of frameworks, operating systems, and hardware platforms. Optimized GEMM kernels ONNX Runtime supports the Microsoft Linear Algebra Subroutine (MLAS) backend as the default Execution Provider (EP) for deeplearning operators.
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), natural language processing (NLP), and recommendation systems. If not, refer to Using the SageMaker Python SDK before continuing.
The explosion in deeplearning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Using this approach, for the first time, we were able to effectively train BERT using simple SGD without the need for adaptivity.
Today, we can train deeplearning algorithms that can automatically extract and represent information contained in audio signals, if trained with enough data. Traditional machinelearning feature-based pipeline vs. end-to-end deeplearning approach ( source ).
By utilizing machinelearning algorithms , it produces new content, including images, text, and audio, that resembles existing data. Another breakthrough is the rise of generative language models powered by deeplearning algorithms. trillion parameters, making it one of the largest language models ever created.
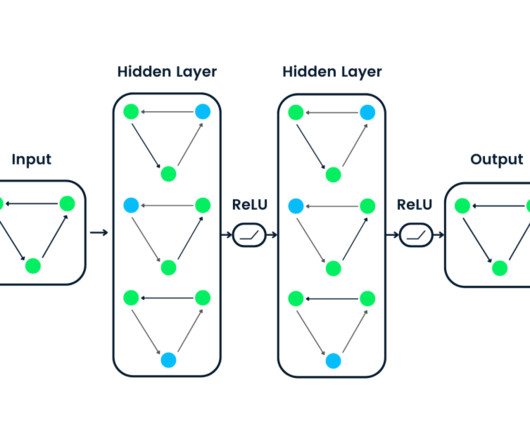
Graph Neural Networks (GNNs) have emerged as a powerful deeplearning framework for graph machinelearning tasks. The tremendous success of LLMs has catalyzed explorations into leveraging their power for graph machinelearning tasks.
Let’s explore some key design patterns that are particularly useful in AI and machinelearning contexts, along with Python examples. BERT, GPT, or T5) based on the task. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. loading models, data preprocessing pipelines).
Over the past decade, data science has undergone a remarkable evolution, driven by rapid advancements in machinelearning, artificial intelligence, and big data technologies. By 2017, deeplearning began to make waves, driven by breakthroughs in neural networks and the release of frameworks like TensorFlow.
The Rise of AI Engineering andMLOps 20182019: Early discussions around MLOps and AI engineering were sparse, primarily focused on general machinelearning best practices. MLOps emerged as a necessary discipline to address the challenges of deploying and maintaining machinelearning models in production environments.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. Deeplearning refers to the use of neural network architectures, characterized by their multi-layer design (i.e. deep” architecture).
Introduction To Generative AI Image Source Course difficulty: Beginner-level Completion time: ~ 45 minutes Prerequisites: No What will AI enthusiasts learn? What is Generative Artificial Intelligence, how it works, what its applications are, and how it differs from standard machinelearning (ML) techniques.
GraphStorm is a low-code enterprise graph machinelearning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. GraphStorm provides different ways to fine-tune the BERT models, depending on the task types. Dataset Num. of nodes Num. of edges Num.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machinelearning models lack. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed.
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. Machine & DeepLearningMachinelearning is the fundamental data science skillset, and deeplearning is the foundation for NLP.
A significant breakthrough came with neural networks and deeplearning. Models like Google's Neural Machine Translation (GNMT) and Transformer revolutionized language processing by enabling more nuanced, context-aware translations. IBM's Model 1 and Model 2 laid the groundwork for advanced systems.
These innovations have showcased strong performance in comparison to conventional machinelearning (ML) models, particularly in scenarios where labelled data is in short supply. In recent years, remarkable strides have been achieved in crafting extensive foundation language models for natural language processing (NLP).
These models, such as OpenAI's GPT-4 and Google's BERT , are not just impressive technologies; they drive innovation and shape the future of how humans and machines work together. Google has developed several tools to enhance the transparency and interpretability of its BERT model.
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. The code can be found on the GitHub repo.
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
An open-source machinelearning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
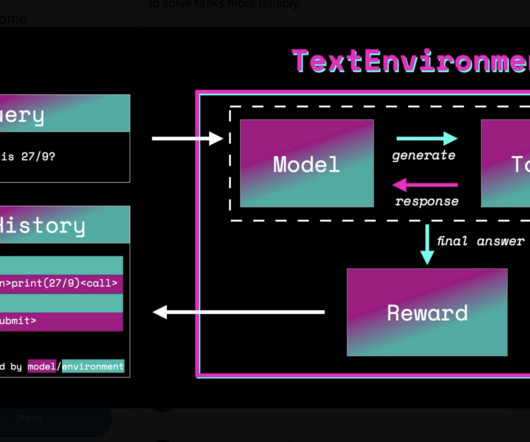
A transformer model with an additional scalar output for each token that can be utilized as a value function in reinforcement learning is presented in AutoModelForCausalLMWithValueHead and AutoModelForSeq2SeqLMWithValueHead. How does TRL work? In TRL, a transformer language model is trained to optimize a reward signal.
In a compelling talk at ODSC West 2024 , Yan Liu, PhD , a leading machinelearning expert and professor at the University of Southern California (USC), shared her vision for how GPT-inspired architectures could revolutionize how we model, understand, and act on complex time series data acrossdomains. The result?
CDS PhD Student Angelica Chen Most machinelearning interpretability research analyzes the behavior of models after their training is complete, and is often correlational, or even anecdotal. The paper is a case study of syntax acquisition in BERT (Bidirectional Encoder Representations from Transformers).
Amazon Elastic Compute Cloud (Amazon EC2) DL2q instances, powered by Qualcomm AI 100 Standard accelerators, can be used to cost-efficiently deploy deeplearning (DL) workloads in the cloud. To learn more about tuning the performance of a model, see the Cloud AI 100 Key Performance Parameters Documentation. Roy from Qualcomm AI.
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machinelearning. This process of adapting pre-trained models to new tasks or domains is an example of Transfer Learning , a fundamental concept in modern deeplearning.
A large language model (often abbreviated as LLM) is a machine-learning model designed to understand, generate, and interact with human language. LLMs leverage deeplearning architectures to process and understand the nuances and context of human language. LLMs are built upon deeplearning, a subset of machinelearning.
Photo by Shubham Dhage on Unsplash Introduction Large language Models (LLMs) are a subset of DeepLearning. Transformer architectures give a machinelearning model the ability to use self-attention mechanisms to recognize links between words in a phrase, independent of where they appear in the text sequence.
In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machinelearning accelerator designed by AWS. Trn1 instances are purpose built for high-performance deeplearning model training while offering up to 50% cost-to-train savings over comparable GPU-based instances.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content