This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction With the advancement in deeplearning, neural network architectures like recurrent neural networks (RNN and LSTM) and convolutional neural networks (CNN) have shown. The post Transfer Learning for NLP: Fine-Tuning BERT for Text Classification appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon BERT is too kind — so this article will be touching. The post Measuring Text Similarity Using BERT appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction In this article, you will learn about the input required for BERT in the classification or the question answering system development. Before diving directly into BERT let’s discuss the […].
The post MobileBERT: BERT for Resource-Limited Devices appeared first on Analytics Vidhya. Overview As the size of the NLP model increases into the hundreds of billions of parameters, so does the importance of being able to.
The post Fake News Classification Using DeepLearning appeared first on Analytics Vidhya. Let’s get started: “Adani Group is planning to explore investment in the EV sector.” ” “Wipro is planning to buy an EV-based startup.” ” […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction to BERT: BERT stands for Bidirectional Encoder Representations from Transformers. The post BERT for Natural Language Inference simplified in Pytorch! appeared first on Analytics Vidhya.
Summary: DeepLearning vs Neural Network is a common comparison in the field of artificial intelligence, as the two terms are often used interchangeably. Introduction DeepLearning and Neural Networks are like a sports team and its star player. DeepLearning Complexity : Involves multiple layers for advanced AI tasks.
Fake news detection might seem like a job best suited for cutting-edge transformer models like BERT, but can traditional models like LSTM still hold their ground? But heres the tech question: Which model is better at detecting fake news a classic LSTM or a modern transformer like BERT? What Makes BERT Powerful? sample(frac=1).reset_index(drop=True)
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GPT, BERT) Image Generation (e.g., Programming: Learn Python, as its the most widely used language in AI/ML.
Summary: DeepLearning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Introduction DeepLearning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. With a projected market growth from USD 6.4
These systems, typically deeplearning models, are pre-trained on extensive labeled data, incorporating neural networks for self-attention. This article introduces UltraFastBERT, a BERT-based framework matching the efficacy of leading BERT models but using just 0.3%
However, traditional deeplearning methods often struggle to interpret the semantic details in log data, typically in natural language. The study reviews approaches to log-based anomaly detection, focusing on deeplearning methods, especially those using pretrained LLMs. higher than the best alternative, NeuralLog.
In deeplearning, especially in NLP, image analysis, and biology, there is an increasing focus on developing models that offer both computational efficiency and robust expressiveness. The model outperforms traditional attention-based models, such as BERT and Vision Transformers, across domains with smaller model sizes.
While deeplearning models have achieved state-of-the-art results in this area, they require large amounts of labeled data, which is costly and time-consuming. Active learning helps optimize this process by selecting the most informative unlabeled samples for annotation, reducing the labeling effort.
AI for Context-Aware Search With the integration of AI, search engines started getting more innovative, learning to understand what users meant behind the keywords rather than just matching them. Technologies like Google's RankBrain and BERT have played a vital role in enhancing contextual understanding of search engines.
These are deeplearning models used in NLP. Machine learning is about teaching computers to perform tasks by recognizing patterns, while deeplearning, a subset of machine learning, creates a network that learns independently. We choose a BERT model fine-tuned on the SQuAD dataset.
In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection. Machine learning models, particularly those based on deeplearning architectures like BERT, have shown great promise in identifying malicious URLs by analyzing their textual features.
This gap has led to the evolution of deeplearning models, designed to learn directly from raw data. What is DeepLearning? Deeplearning, a subset of machine learning, is inspired by the structure and functioning of the human brain. High Accuracy: Delivers superior performance in many tasks.
Introduction Large Language Models (LLMs) are foundational machine learning models that use deeplearning algorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and entity relationships in the language.
Introduction Welcome into the world of Transformers, the deeplearning model that has transformed Natural Language Processing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines understand language, from translating texts to analyzing sentiments.
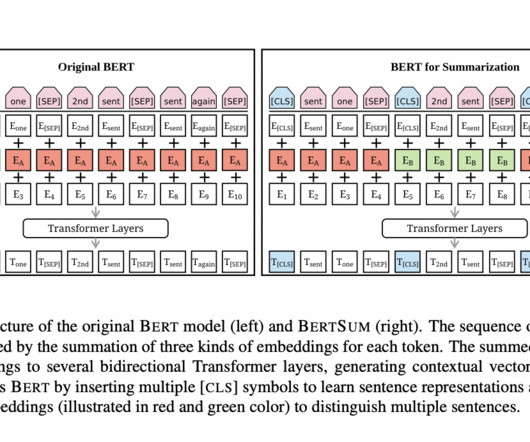
Models like GPT, BERT, and PaLM are getting popular for all the good reasons. The well-known model BERT, which stands for Bidirectional Encoder Representations from Transformers, has a number of amazing applications. Recent research investigates the potential of BERT for text summarization.
The practical success of deeplearning in processing and modeling large amounts of high-dimensional and multi-modal data has grown exponentially in recent years. They believe the proposed computational paradigm shows tremendous promise in connecting deeplearning theory and practice from a unified viewpoint of data compression.
Rather than learning to generate new data, these models aim to make accurate predictions. Notably, BERT (Bidirectional Encoder Representations from Transformers), introduced by Devlin et al. Image Source Defining Predictive AI Predictive AI is primarily concerned with forecasting or inferring outcomes based on historical data.
Neural Network: Moving from Machine Learning to DeepLearning & Beyond Neural network (NN) models are far more complicated than traditional Machine Learning models. Advances in neural network techniques have formed the basis for transitioning from machine learning to deeplearning.
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), natural language processing (NLP), and recommendation systems. If not, refer to Using the SageMaker Python SDK before continuing.
The explosion in deeplearning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Using this approach, for the first time, we were able to effectively train BERT using simple SGD without the need for adaptivity.
Deeplearning models have emerged as transformative tools by leveraging RNA sequence data. Recent deeplearning-based methods integrate multiple sequence alignments (MSAs) and secondary structure constraints to enhance RNA 3D structure prediction. million sequences.
At its core, DeWave utilizes deeplearning models trained on extensive datasets of brain activity. The encoder, a BERT (Bidirectional Encoder Representations from Transformers) model, transforms EEG waves into unique codes. DeWave decodes their brainwaves into written words as users silently read text passages.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deeplearning model designed explicitly for natural language processing tasks like answering questions, analyzing sentiment, and translation.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deeplearning, computer vision , natural language processing , and more. NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. Deeplearning refers to the use of neural network architectures, characterized by their multi-layer design (i.e. deep” architecture).
Today, we can train deeplearning algorithms that can automatically extract and represent information contained in audio signals, if trained with enough data. Traditional machine learning feature-based pipeline vs. end-to-end deeplearning approach ( source ).
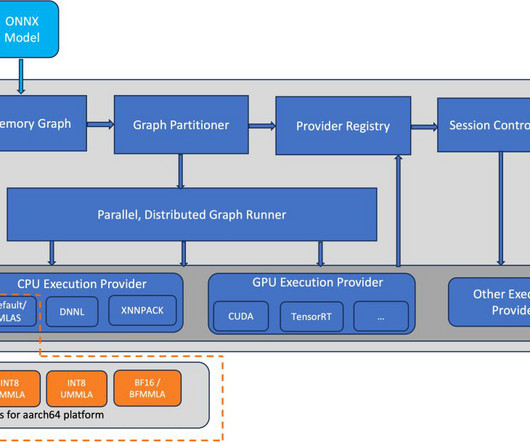
Optimized GEMM kernels ONNX Runtime supports the Microsoft Linear Algebra Subroutine (MLAS) backend as the default Execution Provider (EP) for deeplearning operators. AWS Graviton3-based EC2 instances (c7g, m7g, r7g, c7gn, and Hpc7g instances) support bfloat16 format and MMLA instructions for the deeplearning operator acceleration.
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deeplearning and Natural Language Processing (NLP) to play pivotal roles in this tech. Today platforms like Spotify are leveraging AI to fine-tune their users' listening experiences.
With nine times the speed of the Nvidia A100, these GPUs excel in handling deeplearning workloads. Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.
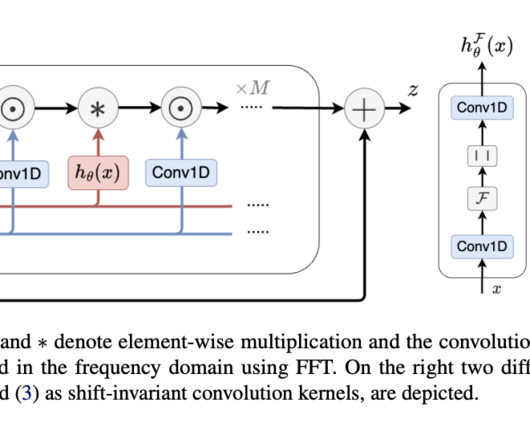
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Impact V.2
Introduction To Image Generation Image Source Course difficulty: Beginner-level Completion time: ~ 1 day (Complete the quiz/lab in your own time) Prerequisites: Knowledge of ML, DeepLearning (DL), Convolutional Neural Nets (CNNs), and Python programming. What will AI enthusiasts learn? Learn how it operates and its uses.
We present the results of recent performance and power draw experiments conducted by AWS that quantify the energy efficiency benefits you can expect when migrating your deeplearning workloads from other inference- and training-optimized accelerated Amazon Elastic Compute Cloud (Amazon EC2) instances to AWS Inferentia and AWS Trainium.
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
Transformer-based language models such as BERT ( Bidirectional Transformers for Language Understanding ) have the ability to capture words or sentences within a bigger context of data, and allow for the classification of the news sentiment given the current state of the world. The code can be found on the GitHub repo.
BERT, GPT, or T5) based on the task. Example : In AI, a Factory pattern might dynamically generate a deeplearning model based on the task type and hardware constraints, whereas in traditional systems, it might simply generate a user interface component. tabular vs. unstructured text).
Traditional NLP methods like CNN, RNN, and LSTM have evolved with transformer architecture and large language models (LLMs) like GPT and BERT families, providing significant advancements in the field. Sparse retrieval employs simpler techniques like TF-IDF and BM25, while dense retrieval leverages deeplearning to improve accuracy.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content