This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the DataScience Blogathon BERT is too kind — so this article will be touching. The post Measuring Text Similarity Using BERT appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Introduction In this article, you will learn about the input required for BERT in the classification or the question answering system development. Before diving directly into BERT let’s discuss the […].
This article was published as a part of the DataScience Blogathon. The post Fake News Classification Using DeepLearning appeared first on Analytics Vidhya. Introduction Here’s a quick puzzle for you. I’ll give you two titles, and you’ll have to tell me which is fake. ” […]. .”
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction to BERT: BERT stands for Bidirectional Encoder Representations from Transformers. The post BERT for Natural Language Inference simplified in Pytorch! appeared first on Analytics Vidhya.
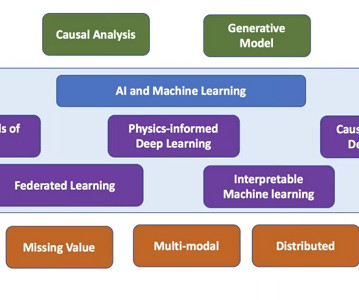
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GPT, BERT) Image Generation (e.g., Programming: Learn Python, as its the most widely used language in AI/ML.
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. 20212024: Interest declined as deeplearning and pre-trained models took over, automating many tasks previously handled by classical ML techniques.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. Deeplearning refers to the use of neural network architectures, characterized by their multi-layer design (i.e. deep” architecture).
Adaptability to Unseen Data: These models may not adapt well to real-world data that wasn’t part of their training data. Neural Network: Moving from Machine Learning to DeepLearning & Beyond Neural network (NN) models are far more complicated than traditional Machine Learning models.
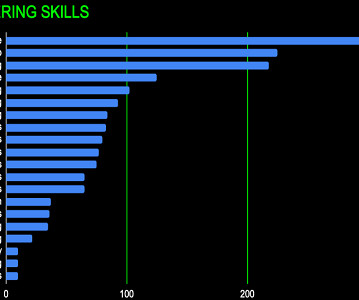
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise.
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), natural language processing (NLP), and recommendation systems. If not, refer to Using the SageMaker Python SDK before continuing.
In a compelling talk at ODSC West 2024 , Yan Liu, PhD , a leading machine learning expert and professor at the University of Southern California (USC), shared her vision for how GPT-inspired architectures could revolutionize how we model, understand, and act on complex time series data acrossdomains. The result?
The paper is a case study of syntax acquisition in BERT (Bidirectional Encoder Representations from Transformers). An MLM, BERT gained significant attention around 2018–2019 and is now often used as a base model fine-tuned for various tasks, such as classification.
GenAI I serve as the Principal Data Scientist at a prominent healthcare firm, where I lead a small team dedicated to addressing patient needs. Over the past 11 years in the field of datascience, I’ve witnessed significant transformations. CS6910/CS7015: DeepLearning Mitesh M. Khapra Homepage www.cse.iitm.ac.in
The following is a brief tutorial on how BERT and Transformers work in NLP-based analysis using the Masked Language Model (MLM). Introduction In this tutorial, we will provide a little background on the BERT model and how it works. The BERT model was pre-trained using text from Wikipedia. What is BERT? How Does BERT Work?
An open-source machine learning model called BERT was developed by Google in 2018 for NLP, but this model had some limitations, and due to this, a modified BERT model called RoBERTa (Robustly Optimized BERT Pre-Training Approach) was developed by the team at Facebook in the year 2019. What is RoBERTa?
With advancements in deeplearning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. Neural Networks & DeepLearning : Neural networks marked a turning point, mimicking human brain functions and evolving through experience.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and DataScience are revolutionising how we analyse data, make decisions, and solve complex problems.
Generative AI represents a significant advancement in deeplearning and AI development, with some suggesting it’s a move towards developing “ strong AI.” Innovators who want a custom AI can pick a “foundation model” like OpenAI’s GPT-3 or BERT and feed it their data.
Implementing end-to-end deeplearning projects has never been easier with these awesome tools Image by Freepik LLMs such as GPT, BERT, and Llama 2 are a game changer in AI. But you need to fine-tune these language models when performing your deeplearning projects. This is where AI platforms come in. Let’s do this.
BERT Transformer Source: Image created by the author + Stable Diffusion (All Rights Reserved) In the context of machine learning and NLP, a transformer is a deeplearning model introduced in a paper titled “Attention is All You Need” by Vaswani et al.
From Big Data to NLP insights: Getting started with PySpark and Spark NLP The amount of data being generated today is staggering and growing. Apache Spark has emerged as the de facto tool to analyze big data over the last few years and is now a critical part of the datascience toolbox.
The journey continues with “NLP and DeepLearning,” diving into the essentials of Natural Language Processing , deeplearning's role in NLP, and foundational concepts of neural networks. ChatGPT for Developers focuses on programming, debugging, and API integrations with ChatGPT.
In Part 1 (fine-tuning a BERT model), I explained what a transformer model is and the various open source models types that are available from Hugging Face’s free transformers library. We also walked through how to fine-tune a BERT model to conduct sentiment analysis. In Part… Read the full blog for free on Medium.
ODSC West 2024 showcased a wide range of talks and workshops from leading datascience, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best datascience instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
Advances in deeplearning and other NLP techniques have helped solve some of these challenges and have led to significant improvements in performance of QA systems in recent years. The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. 2023), Arxiv publications [3] Q.
From deeplearning, Natural Language Processing (NLP), and Natural Language Understanding (NLU) to Computer Vision, AI is propelling everyone into a future with endless innovations. These deeplearning-based models demonstrate impressive accuracy and fluency while processing and comprehending natural language.
This ongoing process straddles the intersection between evidence-based medicine, datascience, and artificial intelligence (AI). BioBERT and similar BERT-based NER models are trained and fine-tuned using a biomedical corpus (or dataset) such as NCBI Disease, BC5CDR, or Species-800. a text file with one word per line).
Metaflow overview Metaflow was originally developed at Netflix to enable data scientists and ML engineers to build ML/AI systems quickly and deploy them on production-grade infrastructure. He is also the author of a book, Effective DataScience Infrastructure, published by Manning. We are happy to help you get started.
RoBERTa RoBERTa (Robustly Optimized BERT Approach) is a natural language processing (NLP) model based on the BERT (Bidirectional Encoder Representations from Transformers) architecture. This refers to the fact that BERT was pre-trained on one set of tasks but fine-tuned on a different set of tasks for downstream NLP applications.
Traditional methods like ARIMA struggle with modern data complexities, but deeplearning has shown promise. Now, imagine a large, pretrained model tailored for time-series data — one that delivers accurate predictions without extensive retraining.
A lot goes into learning a new skill, regardless of how in-depth it is. Getting started with natural language processing (NLP) is no exception, as you need to be savvy in machine learning, deeplearning, language, and more. Sign up for Ai+ Training and get started with learning NLP today!
For example, Seek AI , a developer of AI-powered intelligent data solutions, announced it has raised $7.5 Seek AI uses complex deep-learning foundation models with hundreds of billions of parameters. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
Deeplearning is a powerful AI approach that uses multi-layered artificial neural networks to deliver state-of-the-art accuracy in tasks such as object detection, speech recognition, and language translation. You’ll train deeplearning models from scratch, learning tools and tricks to achieve highly accurate results.
With our new focus areas, we’re diving into Computer Vision and NLP projects as well as spending more time on deeplearning projects and seeing how you, the community, use Comet and Kangas. This week we’ve got pieces on YOLOv5, sentiment analysis, ExBERT, and how to use Comet for deeplearning experiments.
image by rawpixel.com Understanding the concept of language models in natural language processing (NLP) is very important to anyone working in the Deeplearning and machine learning space. Learn more from Uber’s Olcay Cirit. One of the areas that has seen significant growth is language modeling.
Deeplearning models have gained widespread popularity for NLP because of their ability to accurately generalize over a range of contexts and languages. Fundamental understanding of a deeplearning framework such as TensorFlow, PyTorch, or Keras. Basic understanding of neural networks.
This technique is commonly used in neural network-based models such as BERT, where it helps to handle out-of-vocabulary words. Three examples of tokenization methods; image from FreeCodeCamp Tokenization is a fundamental step in data preparation for NLP tasks.
Initially introduced for Natural Language Processing (NLP) applications like translation, this type of network was used in both Google’s BERT and OpenAI’s GPT-2 and GPT-3. The Vision Transformer made as few changes as possible to the original architecture introduced for text data. What does this mean for deeplearning practitioners?
Machine Learning for DataScience and Analytics Authors: Ansaf Salleb-Aouissi, Cliff Stein, David Blei, Itsik Peer Associate, Mihalis Yannakakis, Peter Orbanz If you ever dreamt of attending classes at Columbia University but never had the chance, this artificial intelligence course focused on ML is the next best thing.
They design intricate sequences of prompts, leveraging their knowledge of AI, machine learning, and datascience to guide powerful LLMs (Large Language Models) towards complex tasks. Datascience methodologies and skills can be leveraged to design these experiments, analyze results, and iteratively improve prompt strategies.
For instance, the word bank is interpreted differently in river bank and financial bank, thanks to context-aware models like BERT. Each document undergoes a preprocessing pipeline where textual content is cleaned, tokenised, and transformed into embeddings using models like BERT or Sentence Transformers.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content