This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One-hot encoding is a process by which categorical variables are converted into a binary vector representation where only one bit is “hot” (set to 1) while all others are “cold” (set to 0). Functionality : Each encoder layer has self-attention mechanisms and feed-forward neuralnetworks.
Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text. Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.
In modern machine learning and artificial intelligence frameworks, transformers are one of the most widely used components across various domains including GPT series, and BERT in Natural Language Processing, and Vision Transformers in computer vision tasks.
Blockchain technology can be categorized primarily on the basis of the level of accessibility and control they offer, with Public, Private, and Federated being the three main types of blockchain technologies. The neuralnetwork consists of three types of layers including the hidden layer, the input payer, and the output layer.
A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does. BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018.
NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience. Systems like ChatGPT by OpenAI, BERT, and T5 have enabled breakthroughs in human-AI communication.
While earlier surveys predominantly centred on encoder-based models such as BERT, the emergence of decoder-only Transformers spurred advancements in analyzing these potent generative models. They explore methods to decode information in neuralnetwork models, especially in natural language processing.
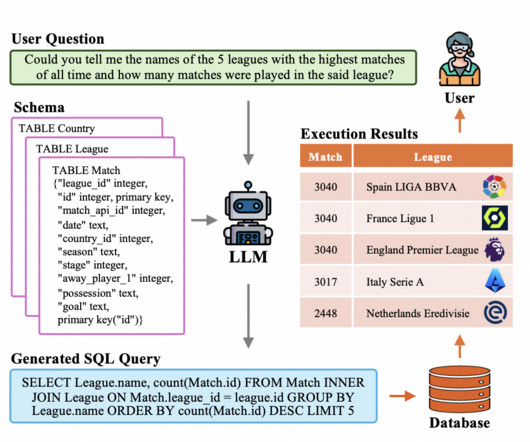
Traditional text-to-SQL systems using deep neuralnetworks and human engineering have succeeded. Using long short-term memory (LSTM) and transformer deep neuralnetworks, among others, enhanced the ability to generate SQL queries from plain English.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Unigrams, N-grams, exponential, and neuralnetworks are valid forms for the Language Model. rely on Language Models as their foundation.
Working of Large Language Models (LLMs) Deep neuralnetworks are used in Large language models to produce results based on patterns discovered from training data. Machine translation, summarization, ticket categorization, and spell-checking are among the examples. T5 (Text-to-Text Transfer Transformer) — developed by Google.
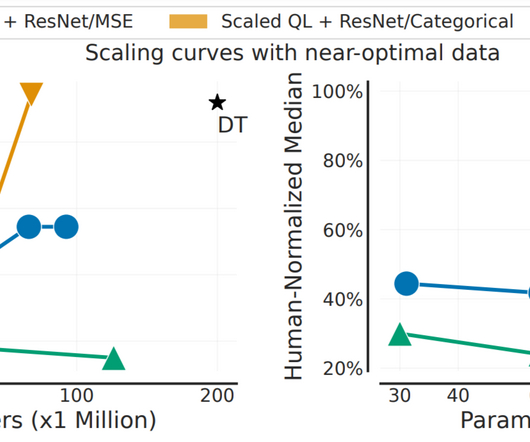
In the same way that BERT or GPT-3 models provide general-purpose initialization for NLP, large RL–pre-trained models could provide general-purpose initialization for decision-making. A few crucial design decisions made this possible: Neuralnetwork size: We found that multi-game Q-learning required large neuralnetwork architectures.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. BERT + Random Forest.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. Deep neuralnetworks have offered a solution, by building dense representations that transfer well between tasks. In this post we introduce our new wrapping library, spacy-transformers.
M5 LLMS are BERT-based LLMs fine-tuned on internal Amazon product catalog data using product title, bullet points, description, and more. Fine-tune the sentence transformer M5_ASIN_SMALL_V20 Now we create a sentence transformer from a BERT-based model called M5_ASIN_SMALL_V2.0. str.split("|").str[0] All other code remains the same.
Introduction In natural language processing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The fourth model which is also used for multi-class classification is built using the famous BERT architecture.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! Deep learning refers to the use of neuralnetwork architectures, characterized by their multi-layer design (i.e. cats” component of Docs, for which we’ll be training a text categorization model to classify sentiment as “positive” or “negative.”
It uses BERT, a popular NLP technique, to understand the meaning and context of words in the candidate summary and reference summary. The more similar the words and meanings captured by BERT, the higher the BERTScore. It uses neuralnetworks like BERT to measure semantic similarity beyond just exact word or phrase matching.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Model architectures that qualify as “supervised learning”—from traditional regression models to random forests to most neuralnetworks—require labeled data for training. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., Image processing : Predictive image processing models, such as convolutional neuralnetworks (CNNs), can classify images into predefined labels (e.g.,
TensorFlow is an open-source software library for AI and machine learning with deep neuralnetworks. TensorFlow Lite also optimizes the trained model using quantization techniques (discussed later in this article), which consequently reduces the necessary memory usage as well as the computational cost of utilizing neuralnetworks.
As the name suggests, this technique involves transferring the learnings of one trained machine learning model to another, in the form of neuralnetwork weights. But, there are open source models like German-BERT that are already trained on huge data corpora, with many parameters. Book a demo to learn more.
Categorization of LLMs – Source One of the most common examples of an LLM is a virtual voice assistant such as Siri or Alexa. This early research was not about designing a system but exploring the fundamentals of Artificial NeuralNetworks. When you ask, “What is the weather today?”,
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
The potential of these enormous neuralnetworks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment. All of this made it easy for researchers and practitioners to use BERT.
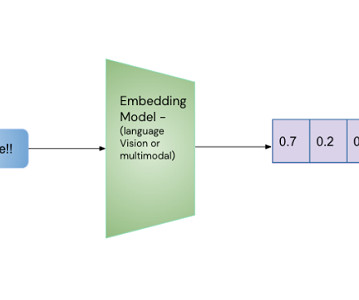
Using Embeddings to Detect Anomalies Figure 1: Using a trained deep neuralnetwork, it is possible to convert unstructured data to numeric representations, i.e., embeddings Embeddings are numerical representations generated from unstructured data like images, text, and audio, and greatly influence machine learning approaches for handling such data.
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more. Basic understanding of neuralnetworks.
This allows GuardDuty to categorize previously unseen domains as highly likely to be malicious or benign based on their association to known malicious domains. By using Graph NeuralNetworks (GNNs), GuardDuty is able to enhance its capability to alert customers.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
Convolutional neuralnetworks (CNNs) and recurrent neuralnetworks (RNNs) are often employed to extract meaningful representations from images and text, respectively. Textual queries are transformed into embeddings using methods like word embeddings or recurrent neuralnetworks.
Uniquely, this model did not rely on conventional neuralnetwork architectures like convolutional or recurrent layers. without conventional neuralnetworks. Source ) This has led to groundbreaking models like GPT for generative tasks and BERT for understanding context in Natural Language Processing ( NLP ).
Deep learning is a powerful AI approach that uses multi-layered artificial neuralnetworks to deliver state-of-the-art accuracy in tasks such as object detection, speech recognition, and language translation. Basic understanding of neuralnetworks.
This leap forward is due to the influence of foundation models in NLP, such as GPT and BERT. The Segment Anything Model Technical Backbone: Convolutional, Generative Networks, and More Convolutional NeuralNetworks (CNNs) and Generative Adversarial Networks (GANs) play a foundational role in the capabilities of SAM.
Text Classification : Categorizing text into predefined categories based on its content. It is used to automatically detect and categorize posts or comments into various groups such as ‘offensive’, ‘non-offensive’, ‘spam’, ‘promotional’, and others. It’s ‘trained’ on labeled data and then used to categorize new, unseen data.
Types of commonsense: Commonsense knowledge can be categorized according to types, including but not limited to: Social commonsense: people are capable of making inferences about other people's mental states, e.g. what motivates them, what they are likely to do next, etc. In the last 3 years, language models have been ubiquitous in NLP.
In this example figure, features are extracted from raw historical data, which are then are fed into a neuralnetwork (NN). Parallel computing Parallel computing refers to carrying out multiple processes simultaneously, and can be categorized according to the granularity at which parallelism is supported by the hardware.
Clearly, we couldn’t use a model such as BERT or GPT-2 directly. Stepping back a little, the problem of so-called “one hot” representations posing representational issues for neuralnetworks is actually quite familiar. It helps most for text categorization and parsing, but is less effective for named entity recognition.
LaMDA is built on Transformer , a neuralnetwork architecture that Google Research invented and open-sourced in 2017. Like other large language models, including BERT and GPT-3, LaMDA is trained on terabytes of text data to learn how words relate to one another and then predict what words are likely to come next.
LangChain categorizes its chains into three types: Utility chains, Generic chains, and Combine Documents chains. Hugging Face Hugging Face is a FREE-TO-USE Transformers Python library, compatible with PyTorch, TensorFlow, and JAX, and includes implementations of models like BERT , T5 , etc.
The Technologies Behind Generative Models Generative models owe their existence to deep neuralnetworks, sophisticated structures designed to mimic the human brain's functionality. By capturing and processing multifaceted variations in data, these networks serve as the backbone of numerous generative models.
LLMs are neuralnetworks that have been trained using a massive number of parameters, typically in the order of billions, using unlabeled data. Due to the sequential nature of text, recurrent neuralnetworks (RNNs) had been the state of the art for NLP modeling. Thus the basis of the transformer model was born.
The first two can be categorized as inductive bias of humans and the last one is introducing compute over human element; which provides the following advantages: Unbiased Exploration: Evolutionary algorithms can systematically explore a vast space of potential model combinations, significantly exceeding human capabilities.
Some well-known examples include OpenAIs GPT (Generative Pre-trained Transformer) and Googles BERT (Bidirectional Encoder Representations from Transformers). Types of Large Language Models Large Language Models can be categorized based on their architecture, training objectives, and use cases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content