

BERT models: Google’s NLP for the enterprise
Snorkel AI
DECEMBER 27, 2023
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.






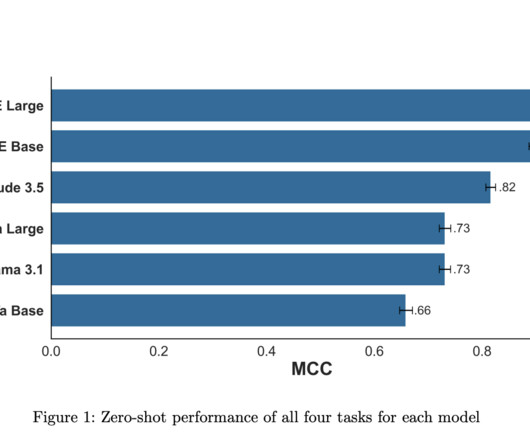







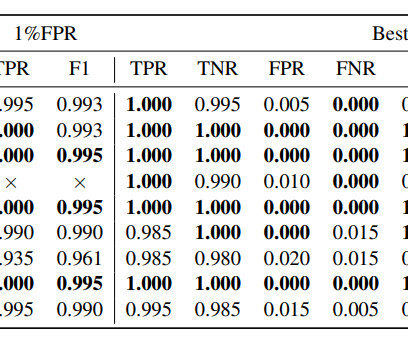





























Let's personalize your content