This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
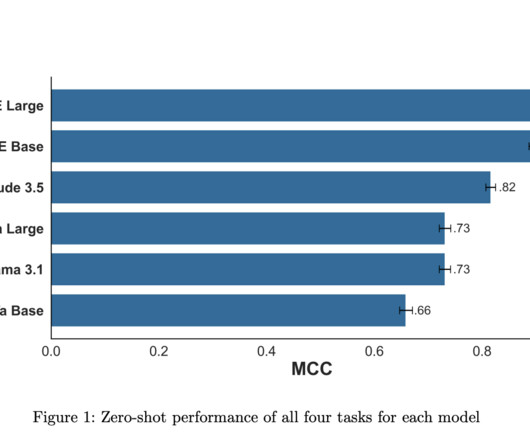
Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text. Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.
This article explores an innovative way to streamline the estimation of Scope 3 GHG emissions leveraging AI and Large Language Models (LLMs) to help categorize financial transaction data to align with spend-based emissions factors. Why are Scope 3 emissions difficult to calculate?
This interdisciplinary field incorporates linguistics, computer science, and mathematics, facilitating automatic translation, text categorization, and sentiment analysis. In sequential single interaction, retrievers identify relevant documents, which the language model then uses to predict the output.
Text embeddings are vector representations of words, sentences, paragraphs or documents that capture their semantic meaning. More recent methods based on pre-trained language models like BERT obtain much better context-aware embeddings. Existing methods predominantly use smaller BERT-style architectures as the backbone model.
BERT (Bi-directional Encoder Representations from Transformers) is one of the earliest LLM foundation models developed. An open-source model, Google created BERT in 2018. Dev Developers can write, test and document faster using AI tools that generate custom snippets of code.
While large language models (LLMs) have claimed the spotlight since the debut of ChatGPT, BERT language models have quietly handled most enterprise natural language tasks in production. Additionally, while the data and code needed to train some of the latest generation of models is still closed-source, open source variants of BERT abound.
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Product requirements documentation (PRD) generation Monterey is working on a “co-pilot for product development” that might include LLMs.
Introduction In natural language processing, text categorization tasks are common (NLP). transformer.ipynb” uses the BERT architecture to classify the behaviour type for a conversation uttered by therapist and client, i.e, The minimal number of documents in which a word must appear to be retained is min_df, which is set to 5.
In NLI, a “premise” document is paired with a “hypothesis” statement, and the model determines if the hypothesis is true based on the premise. For instance, a BERT model with 86 million parameters can perform NLI tasks, while the smallest effective zero-shot generative LLMs require 7-8 billion parameters.
Large language Models also intersect with Generative Ai, it can perform a variety of Natural Language Processing tasks, including generating and classifying text, question answering, and translating text from one language to another language, and Document summarization. RoBERTa (Robustly Optimized BERT Approach) — developed by Facebook AI.
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. In a recent talk at Google Berlin, Jacob Devlin described how Google are using his BERT architectures internally. We provide an example component for text categorization.
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. Extract and analyze data from documents.
It automates document analysis, enhances the identification of relevant legal principles, and establishes new benchmarks in the field. Automated document analysis AI tools designed for law firms use advanced technologies like NLP and machine learning to analyze extensive legal documents swiftly.
Government agencies summarize lengthy policy documents and reports to help policymakers strategize and prioritize goals. By creating condensed versions of long, complex documents, summarization technology enables users to focus on the most salient content. This leads to better comprehension and retention of critical information.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. We provide a prompt example for feedback categorization. Extracting valuable insights from customer feedback presents several significant challenges.
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! identifying the “emotional tone” of a particular document). These approaches were all based on a technique called “bagging”; the process of splitting documents into a collection of words (which we’ll refer to as “tokens”).
In the general language domain, there are two main branches of pre-trained language models: BERT (and its variants) and GPT (and its variants). The first one, BERT (and its variants), has received the most attention in the biomedical domain; examples include BioBERT and PubMedBERT, while the second one has received less attention.
The KGW Family modifies the logits produced by the LLM to create watermarked output by categorizing the vocabulary into a green list and a red list based on the preceding token. Additionally, two document-level text tampering attacks are provided: paraphrasing the context via OpenAI API or the Dipper model.
The DeepPavlov Library uses BERT base models to deal with Question Answering, such as RoBERTa. BERT is a pre-trained transformer-based deep learning model for natural language processing that achieved state-of-the-art results across a wide array of natural language processing tasks when this model was proposed.
Text Classification: Categorize text into predefined groups for content moderation and tone detection. Natural Language Question Answering : Use BERT to answer questions based on text passages. The official development workflow documentation can be found here. Super Resolution: Enhance low-resolution images to higher quality.
The ability to precisely comprehend the intricate details documented in clinical reports is essential for informing subsequent treatment decisions, adjusting therapeutic strategies, and ultimately improving patient outcomes. Step 1: Transforms raw texts to `document` document = DocumentAssembler().setInputCol("text").setOutputCol("document")
BERTBERT, an acronym that stands for “Bidirectional Encoder Representations from Transformers,” was one of the first foundation models and pre-dated the term by several years. BERT proved useful in several ways, including quantifying sentiment and predicting the words likely to follow in unfinished sentences.
The SST2 dataset is a text classification dataset with two labels (0 and 1) and a column of text to categorize. Training – Take the shaped CSV file and run fine-tuning with BERT for text classification utilizing Transformers libraries. Refer to SageMaker documentation for detailed instructions.
In this article, we will explore about ALBERT ( A lite weighted version of BERT machine learning model) What is ALBERT? ALBERT (A Lite BERT) is a language model developed by Google Research in 2019. BERT, GPT-2, and XLNet are some examples of models that can be used as teacher models for ALBERT.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. Most recently, OpenAI debuted GPT-4.
BERT, the first breakout large language model In 2019, a team of researchers at Goole introduced BERT (which stands for bidirectional encoder representations from transformers). By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. Most recently, OpenAI debuted GPT-4.
report() Output of the.report() In this snippet, we defined the task as crows-pairs , the model as bert-base-uncased from huggingface , and the data as CrowS-Pairs. Output of the.generated_results() We can continue with this dataframe with our own methods, we can categorize by bias-type or even do more filtration for the probabilities.
Its categorical power is brittle. This is a piece of text that includes the portions of the prompt to be repeated for every document, as well as a placeholder for the document to examine. BERT for misinformation. The largest version of BERT contains 340 million parameters. A GPT-3 model—82.5%
Its categorical power is brittle. This is a piece of text that includes the portions of the prompt to be repeated for every document, as well as a placeholder for the document to examine. BERT for misinformation. The largest version of BERT contains 340 million parameters. A GPT-3 model—82.5%
Its categorical power is brittle. This is a piece of text that includes the portions of the prompt to be repeated for every document, as well as a placeholder for the document to examine. BERT for misinformation. The largest version of BERT contains 340 million parameters. A GPT-3 model—82.5%
Transformer-based models, such as Bidirectional Encoder Representations from Transformers (BERT), have revolutionized NLP by offering accuracy comparable to human baselines on benchmarks like SQuAD for question-answer, entity recognition, intent recognition, sentiment analysis, and more.
Text Classification : Categorizing text into predefined categories based on its content. Text Summarization : Generating a summary of a longer text document. It is used to automatically detect and categorize posts or comments into various groups such as ‘offensive’, ‘non-offensive’, ‘spam’, ‘promotional’, and others.
This data needs to be analysed and be in a structured manner whether it is in the form of emails, texts, documents, articles, and many more. This involves three phases: aspect detection, sentiment categorization, and aggregation of results. Commonly used models include BERT, GPT, and LSTM-based models.
SpanCategorizer for predicting arbitrary and overlapping spans A common task in applied NLP is extracting spans of texts from documents, including longer phrases or nested expressions. adds 5 new pipeline packages, including a new core family for Catalan and a new transformer-based pipeline for Danish using the danish-bert-botxo weights.
A noteworthy observation is that even popular models in the machine learning community, such as bert-base-uncased, xlm-roberta-base, etc exhibit these biases. It can identify entities (NER), categorize texts (Text Classification), flag inappropriate content (Toxicity), and even facilitate question-answering capabilities.
Specifically, our aim is to facilitate standardized categorization for enhanced medical data analysis and interpretation. Detecting and Mapping MedDRA Concepts in Free-Text Documents In Spark NLP for Healthcare, the process of mapping entities to medical terminologies, or entity resolution, begins with Named Entity Recognition (NER).
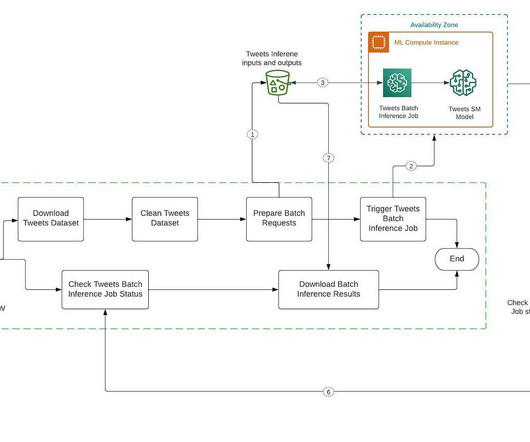
For example, a company may enrich documents in bulk to translate documents, identify entities and categorize those documents, etc. Create a Tweets Classifier model A prerequisite to executing the SageMaker batch job is to create a Tweets classifier (HuggingFace BERT) model on SageMaker.
While there are many origins of hallucinations within an LLM’s architecture, we can simplify and categorize the root causes into four main origins of hallucinations: Lack of or scarce data during training As a rule of thumb, an LLM cannot give you any info that was not clearly shown during training. Here, the hallucinations are materialized.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Bank agents may also struggle to track the status of complaints and ensure that they are resolved in a timely manner. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Bank agents may also struggle to track the status of complaints and ensure that they are resolved in a timely manner. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Bank agents may also struggle to track the status of complaints and ensure that they are resolved in a timely manner. Assigning complaints to staff.
AI is accelerating complaint resolution for banks AI can help banks automate many of the tasks involved in complaint handling, such as: Identifying, categorizing, and prioritizing complaints. Bank agents may also struggle to track the status of complaints and ensure that they are resolved in a timely manner. Assigning complaints to staff.
Types of commonsense: Commonsense knowledge can be categorized according to types, including but not limited to: Social commonsense: people are capable of making inferences about other people's mental states, e.g. what motivates them, what they are likely to do next, etc. Using the AllenNLP demo. Is it still useful?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content