This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
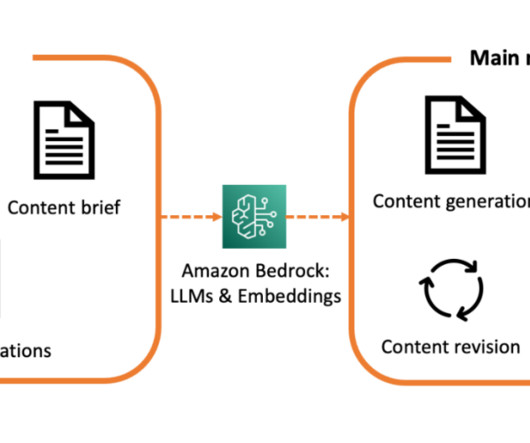
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications.
However, by using Anthropics Claude on Amazon Bedrock , researchers and engineers can now automate the indexing and tagging of these technical documents. With Anthropics Claude, you can extract more insights from documents, process web UIs and diverse product documentation, generate image catalog metadata, and more.
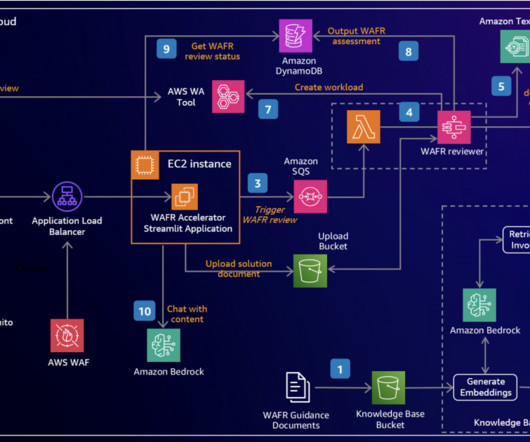
This solution automates portions of the WAFR report creation, helping solutions architects improve the efficiency and thoroughness of architectural assessments while supporting their decision-making process. Metadata filtering is used to improve retrieval accuracy.
Localization relies on both automation and humans-in-the-loop in a process called Machine Translation Post Editing (MTPE). The solution proposed in this post relies on LLMs context learning capabilities and promptengineering. The request is sent to the prompt generator.
It simplifies the creation and management of AI automations using either AI flows, multi-agent systems, or a combination of both, enabling agents to work together seamlessly, tackling complex tasks through collaborative intelligence. At a high level, CrewAI creates two main ways to create agentic automations: flows and crews.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced. This provides an automated deployment experience on your AWS account. Prerequisites This post is intended for developers with a basic understanding of LLM and promptengineering.
With the launch of the Automated Reasoning checks in Amazon Bedrock Guardrails (preview), AWS becomes the first and only major cloud provider to integrate automated reasoning in our generative AI offerings. Click on the image below to see a demo of Automated Reasoning checks in Amazon Bedrock Guardrails.
Yes, they have the data, the metadata, the workflows and a vast array of services to connect into; and so long as your systems only live within Salesforce, it sounds pretty ideal. While Salesforce and others talk a big game about automation, it’s always grounded in the need to be able to bring a human back into the center when necessary.
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. Along with protecting against toxicity and harmful content, it can also be used for Automated Reasoning checks , which helps you protect against hallucinations.
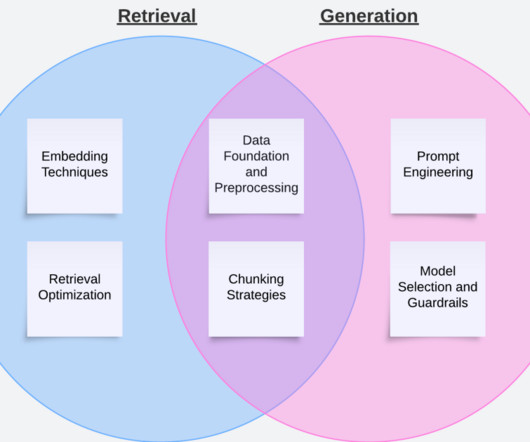
Implement metadata filtering , adding contextual layers to chunk retrieval. For code samples for metadata filtering using Amazon Bedrock Knowledge Bases, refer to the following GitHub repo. Success comes from methodically using techniques like promptengineering and chunking to improve both the retrieval and generation stages of RAG.
IBM software products are embedding watsonx capabilities across digital labor, IT automation, security, sustainability, and application modernization to help unlock new levels of business value for clients. Automated development: Automates data preparation, model development, feature engineering and hyperparameter optimization using AutoAI.
Experts can check hard drives, metadata, data packets, network access logs or email exchanges to find, collect, and process information. Automate Processes Automation is one of AI’s greatest capabilities. Unfortunately, they often hallucinate, especially when unintentional promptengineering is involved.
Prompt catalog – Crafting effective prompts is important for guiding large language models (LLMs) to generate the desired outputs. Promptengineering is typically an iterative process, and teams experiment with different techniques and prompt structures until they reach their target outcomes.
At 20 Minutes, a key goal of our technology team is to develop new tools for our journalists that automate repetitive tasks, improve the quality of reporting, and allow us to reach a wider audience. While these tasks can feel like a chore, they are critical to search engine optimization (SEO) and therefore the audience reach of the article.
This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain. PromptengineeringPromptengineering enables you to instruct LLMs to generate suggestions, explanations, or completions of text in an interactive way.
This includes features for hyperparameter tuning, automated model selection, and visualization of model metrics. Automated pipelining and workflow orchestration: Platforms should provide tools for automated pipelining and workflow orchestration, enabling you to define and manage complex ML pipelines.
Try metadata filtering in your OpenSearch index. Try using query rewriting to get the right metadata filtering. The retriever isn’t at fault, the problem is with FM generation (evaluated by a human or LLM): Try promptengineering to mitigate hallucinations. If none of the above help: Consider training a custom embedding.
Prompting Rather than inputs and outputs, LLMs are controlled via prompts – contextual instructions that frame a task. Promptengineering is crucial to steering LLMs effectively. Hybrid retrieval combines dense embeddings and sparse keyword metadata for improved recall.
The latest advances in generative artificial intelligence (AI) allow for new automated approaches to effectively analyze large volumes of customer feedback and distill the key themes and highlights. This post explores an innovative application of large language models (LLMs) to automate the process of customer review analysis.
After the completion of the research phase, the data scientists need to collaborate with ML engineers to create automations for building (ML pipelines) and deploying models into production using CI/CD pipelines. Strong domain knowledge for tuning, including promptengineering, is required as well.
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. PromptengineeringPromptengineering is crucial for the knowledge retrieval system.
The use cases can range from medical information extraction and clinical notes summarization to marketing content generation and medical-legal review automation (MLR process). We use promptengineering to send our summarization instructions to the LLM.
Model training is only a small part of a typical machine learning project (source: own study) Of course, in the context of Large Language Models, we often talk about just fine tuning, few-shot learning or just promptengineering instead of a full training procedure. Not the best combination, right?
The AmazonTextractPDFLoader is a service loader type of document loader that provides quick way to automate document processing by using Amazon Textract in combination with LangChain. This task is particularly useful for automation of key entity extraction that requires the output to be aligned with desired formats.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal promptengineering. Evaluating RAG systems at scale requires an automated approach to extract metrics that are quantitative indicators of its reliability.
We envision a future where AI seamlessly integrates into our teams’ workflows, automating repetitive tasks, providing intelligent recommendations, and freeing up time for more strategic, high-value interactions. AWS data teams make sure the information used is accurate, up to date, and appropriately utilized.
Be sure to check out his talk, “ Prompt Optimization with GPT-4 and Langchain ,” there! The difference between the average person using AI and a PromptEngineer is testing. Most people run a prompt 2–3 times and find something that works well enough. In an industry where time is money, this feature is invaluable.
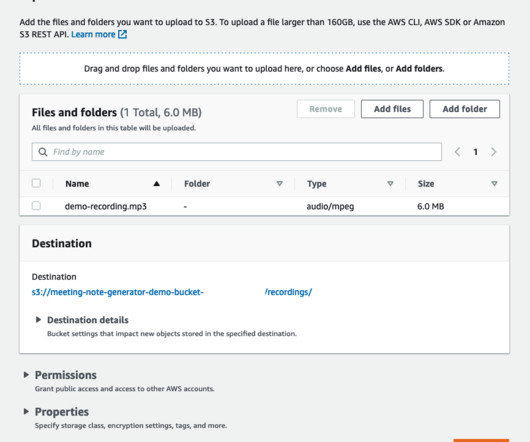
You can use large language models (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering. Solution overview The Meeting Notes Generator Solution creates an automated serverless pipeline using AWS Lambda for transcribing and summarizing audio and video recordings of meetings.
Tools range from data platforms to vector databases, embedding providers, fine-tuning platforms, promptengineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways. with efficient methods and enhancing model performance through promptengineering and retrieval augmented generation (RAG).
This final prompt gives the LLM more context with which to answer the users question. Promptengineering: crafting effective prompt templates Poorly designed prompt templates can lead to off-target responses or outputs that lack the desired specificity. Learn more about retrieval-augmented generation in our guide.
These remarkable AI systems have found applications in a wide array of fields, revolutionizing the way we interact with technology and enabling new possibilities in communication, automation, and problem-solving. Users can gain deep insights into the evolution of their prompts and responses.
In terms of technology: generating code snippets, code translation, and automated documentation. This goes into the model risk management in analyzing the metadata around the model, whether it’s fit for purpose with automated or human-in-the-loop capabilities. Then comes promptengineering.
In terms of technology: generating code snippets, code translation, and automated documentation. This goes into the model risk management in analyzing the metadata around the model, whether it’s fit for purpose with automated or human-in-the-loop capabilities. Then comes promptengineering.
Automation: Custom tools enable you to automate repetitive tasks or workflows. From expanding functionality with specific use cases to seamless integration and automation, LangChain’s agents are reshaping how we interact with AI systems. Integration: Custom tools can integrate LangChain with other systems or tools.
The StringComparison evaluators facilitate this so you can answer questions like: Which LLM or prompt produces a preferred output for a given question? The simplest and often most reliable automated way to choose a preferred prediction for a given input is to use the pairwise_string evaluator. kwargs : Additional keyword arguments.
Using Selenium, a powerful tool for browser automation, it opens an actual browser window (in headless mode, meaning without a graphical interface) and interacts with the webpage. How SeleniumURLLoader Retrieves Text The SeleniumURLLoader is like an undercover agent in the world of web browsers.
This emergent ability in LLMs has compelled software developers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more. The JSON artifact is directly integrated to the core SnapLogic integration platform.
With these tools in hand, the next challenge is to integrate LLM evaluation into the Machine Learning and Operation (MLOps) lifecycle to achieve automation and scalability in the process. Those metrics serve as a useful tool for automated evaluation, providing quantitative measures of lexical similarity between generated and reference text.
Automate health checks: Develop comprehensive scripts to ensure host health. Metadata, callbacks, and data format conversions. They consider this result exciting given the minimal effort required. The article concludes by explaining that deeper language programs in DSPy, like deeper neural networks, can be more effective.
IBM watsonx™ can be used to automate the identification of regulatory obligations and map legal and regulatory requirements to a risk governance framework. The enhanced metadata supports the matching categories to internal controls and other relevant policy and governance datasets.
This prompted 123RF to search for a more reliable and affordable solution to enhance multilingual content discovery. This post explores how 123RF used Amazon Bedrock, Anthropic’s Claude 3 Haiku, and a vector store to efficiently translate content metadata, significantly reduce costs, and improve their global content discovery capabilities.
The core challenge lies in developing data pipelines that can handle diverse data sources, the multitude of data entities in each data source, their metadata and access control information, while maintaining accuracy. Amazon Q Business also helps streamline tasks and accelerate problem solving.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content