This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
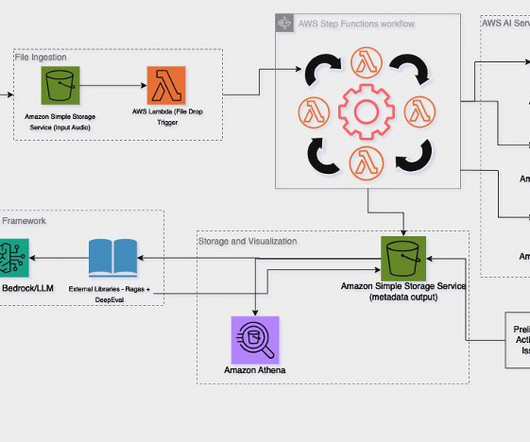
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
It often requires managing multiple machinelearning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. With Amazon Bedrock Data Automation, enterprises can accelerate AI adoption and develop solutions that are secure, scalable, and responsible.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. The DynamoDB table is crucial for tracking and managing the batch inference jobs throughout their lifecycle.
However, by using Anthropics Claude on Amazon Bedrock , researchers and engineers can now automate the indexing and tagging of these technical documents. This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata.
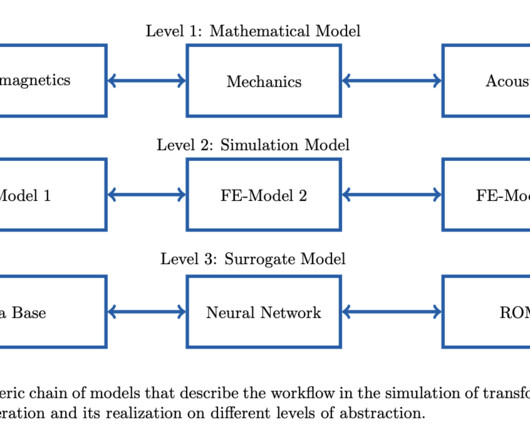
Emerging tools like Jupyter notebooks and Code Ocean facilitate documentation and integration, while automated workflows aim to merge computer-based and laboratory computations. FMI’s container-based approach aids in replicating simulations but requires metadata for broader reproducibility and adaptation.
You can trigger the processing of these invoices using the AWS CLI or automate the process with an Amazon EventBridge rule or AWS Lambda trigger. structured: | Process the pdf invoice and list all metadata and values in json format for the variables with descriptions in tags. The result should be returned as JSON as given in the tags.
Better data Automated data collection and analysis means fewer mistakes and more consistent results. Control plane: Secure drone communication and operations Our journey begins with automated drone flights. This brings the following benefits: Less risk for people Drones do the dangerous work so people dont have to.
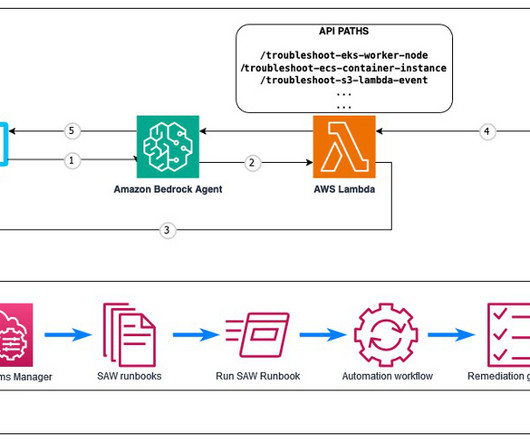
Fortunately, AWS provides a powerful tool called AWS Support Automation Workflows , which is a collection of curated AWS Systems Manager self-service automation runbooks. These runbooks are created by AWS Support Engineering with best practices learned from solving customer issues. The agent uses Anthropics Claude 3.5
Amazon Comprehend provides real-time APIs, such as DetectPiiEntities and DetectEntities , which use natural language processing (NLP) machinelearning (ML) models to identify text portions for redaction. For the metadata file used in this example, we focus on boosting two key metadata attributes: _document_title and services.
I have written short summaries of 68 different research papers published in the areas of MachineLearning and Natural Language Processing. They focus on coherence, as opposed to correctness, and develop an automated LLM-based score (BooookScore) for assessing summaries. University of Wisconsin-Madison.
It simplifies the creation and management of AI automations using either AI flows, multi-agent systems, or a combination of both, enabling agents to work together seamlessly, tackling complex tasks through collaborative intelligence. At a high level, CrewAI creates two main ways to create agentic automations: flows and crews.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
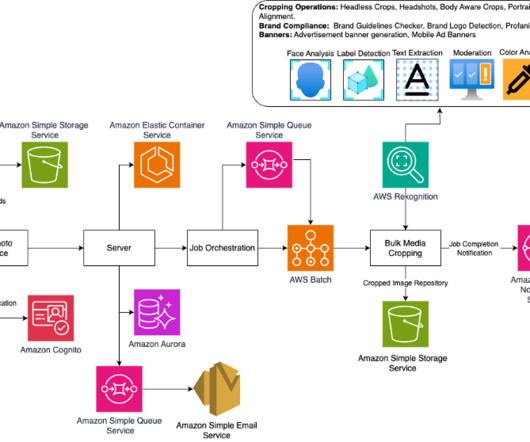
Crop.photo from Evolphin Software is a cloud-based service that offers powerful bulk processing tools for automating image cropping, content resizing, background removal, and listing image analysis. This is where Crop.photos smart automations come in with an innovative solution for high-volume image processing needs.
After some impressive advances over the past decade, largely thanks to the techniques of MachineLearning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments.
Innovations in artificial intelligence (AI) and machinelearning (ML) are causing organizations to take a fresh look at the possibilities these technologies can offer. Automating these checks allows them to be repeated regularly and consistently rather than organizations having to rely on infrequent manual point- in-time checks.
AI models trained with a mix of clinical trial metadata, medical and pharmacy claims data, and patient data from membership (primary care) services can also help identify clinical trial sites that will provide access to diverse, relevant patient populations.
Here’s a handy checklist to help you find and implement the best possible observability platform to keep all your applications running merry and bright: Complete automation. Contextualizing telemetry data by visualizing the relevant information or metadata enables teams to better understand and interpret the data. Ease of use.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
The automation provided by Rad AI Impressions not only reduces burnout, but also safeguards against errors arising from manual repetition. First, it enhances researcher productivity by providing the necessary processes and automation, positioning them to deliver high-quality models with regularity. No one writes any code manually.
Artificial intelligence (AI) and machinelearning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. Machinelearning operations (MLOps) applies DevOps principles to ML systems.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. Dhawal Patel is a Principal MachineLearning Architect at AWS.
Localization relies on both automation and humans-in-the-loop in a process called Machine Translation Post Editing (MTPE). The solution proposed in this post relies on LLMs context learning capabilities and prompt engineering. One of LLMs most fascinating strengths is their inherent ability to understand context.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machinelearning (ML). Capture and document model metadata for report generation.
Also, a lakehouse can introduce definitional metadata to ensure clarity and consistency, which enables more trustworthy, governed data. And AI, both supervised and unsupervised machinelearning, is often the best or sometimes only way to unlock these new big data insights at scale. All of this supports the use of AI.
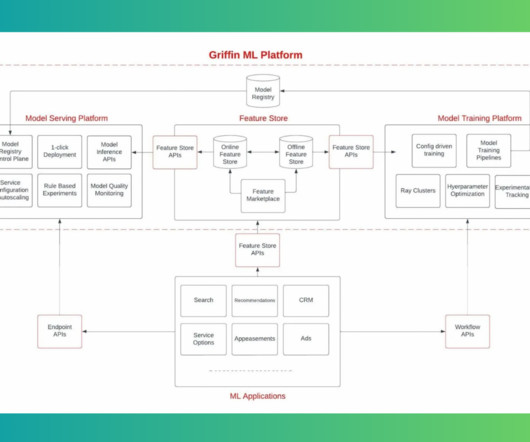
a machinelearning (ML) platform, to streamline the development and deployment of ML applications. The researchers said that this architecture change and an intuitive web user interface allow Machinelearning engineers (MLEs) to have a seamless experience. uses a centralized feature and metadata management system.
Failing to adopt a more automated approach could have potentially led to decreased customer satisfaction scores and, consequently, a loss in future revenue. The evaluation framework, call metadata generation, and Amazon Q in QuickSight were new components introduced from the original PCA solution. and Anthropics Claude Haiku 3.
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. Data engineers contribute to the data lineage process by providing the necessary information and metadata about the data transformations they perform. To view this series from the beginning, start with Part 1.
Emerging technologies and trends, such as machinelearning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Automation can significantly improve efficiency and reduce errors. As new technologies emerge, organizations must adapt to avoid being left behind.
A well-designed data architecture should support business intelligence and analysis, automation, and AI—all of which can help organizations to quickly seize market opportunities, build customer value, drive major efficiencies, and respond to risks such as supply chain disruptions.
Seamless integration with data science and machinelearning tools is crucial, and native support for AI workflows—such as managing model data, training sets and inference data—can enhance operational efficiency. We unify source data, metadata, operational data, vector data and generated data—all in one platform.
AI agents continue to gain momentum, as businesses use the power of generative AI to reinvent customer experiences and automate complex workflows. For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security.
AutomatedMachineLearning has become essential in data-driven decision-making, allowing domain experts to use machinelearning without requiring considerable statistical knowledge. This innovative approach holds promise for revolutionizing the field of AutomatedMachineLearning.
SageMaker JumpStart is a machinelearning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
The majority of us who work in machinelearning, analytics, and related disciplines do so for organizations with a variety of different structures and motives. The following is an extract from Andrew McMahon’s book , MachineLearning Engineering with Python, Second Edition.
It employs software automation to strengthens the ability to mitigate risks, manage regulatory requirements, and govern the lifecycle for both generative AI and predictive machinelearning (ML) models. Risk management – preset risk thresholds, and proactively detect and mitigate AI model risks.
In addition to these capabilities, generative AI can revolutionize drive tests, optimize network resource allocation, automate fault detection, optimize truck rolls and enhance customer experience through personalized services. Operators and suppliers are already identifying and capitalizing on these opportunities.
Bringing together traditional machinelearning and generative AI with a family of enterprise-grade, IBM-trained foundation models, watsonx allows the USTA to deliver fan-pleasing, AI-driven features much more quickly. This year, the USTA is using watsonx , IBM’s new AI and data platform for business.
IBM software products are embedding watsonx capabilities across digital labor, IT automation, security, sustainability, and application modernization to help unlock new levels of business value for clients. Automated development: Automates data preparation, model development, feature engineering and hyperparameter optimization using AutoAI.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machinelearning (ML)-based methods use additional information, such as the time series data of related variables. A dataset must conform to the schema defined within Forecast.
Additionally, for every retrieval result you bring, you can provide a name and additional metadata in the form of key-value pairs. When using BYOI, you must provide your retrieval results in a new field called output (this field is required for BYOI jobs but optional and not needed for non-BYOI jobs). Fields marked with ? are optional.
Although these traditional machinelearning (ML) approaches might perform decently in terms of accuracy, there are several significant advantages to adopting generative AI approaches. This provides an automated deployment experience on your AWS account. You can also refer to the cleanup section in the GitHub deployment guide.
Using machinelearning (ML), AI can understand what customers are saying as well as their tone—and can direct them to customer service agents when needed. McDonald’s is building AI solutions for customer care with IBM Watson AI technology and NLP to accelerate the development of its automated order taking (AOT) technology.
Machinelearning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content